Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning transformer attention weights into zero-shot sequence labelers
Paper and Code
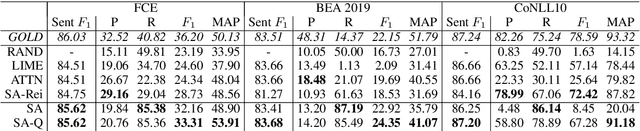
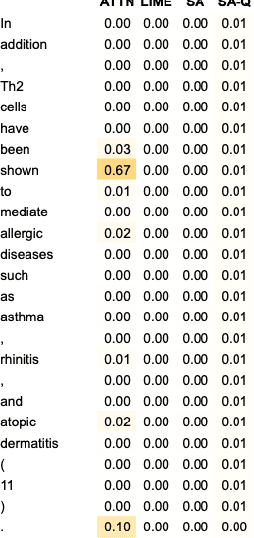
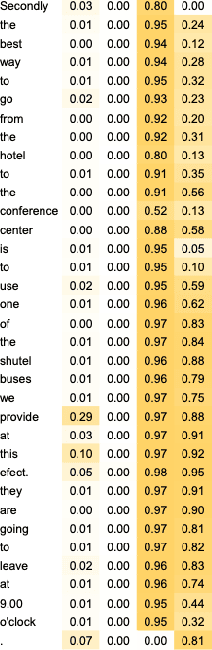
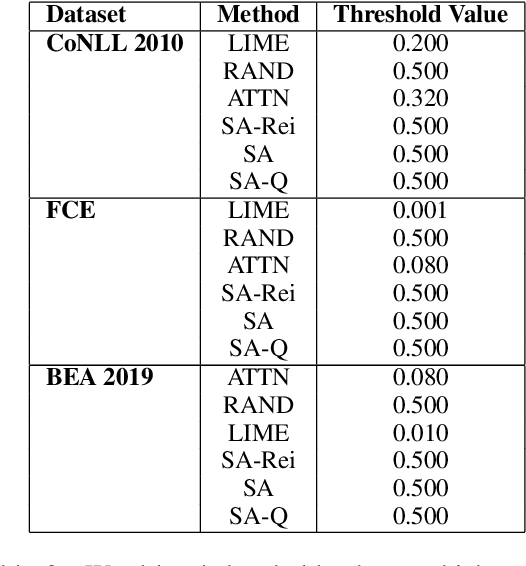
We demonstrate how transformer-based models can be redesigned in order to capture inductive biases across tasks on different granularities and perform inference in a zero-shot manner. Specifically, we show how sentence-level transformers can be modified into effective sequence labelers at the token level without any direct supervision. We compare against a range of diverse and previously proposed methods for generating token-level labels, and present a simple yet effective modified attention layer that significantly advances the current state of the art.
View paper on