 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreative Agents: Simulating the Systems Model of Creativity with Generative Agents
Nov 26, 2024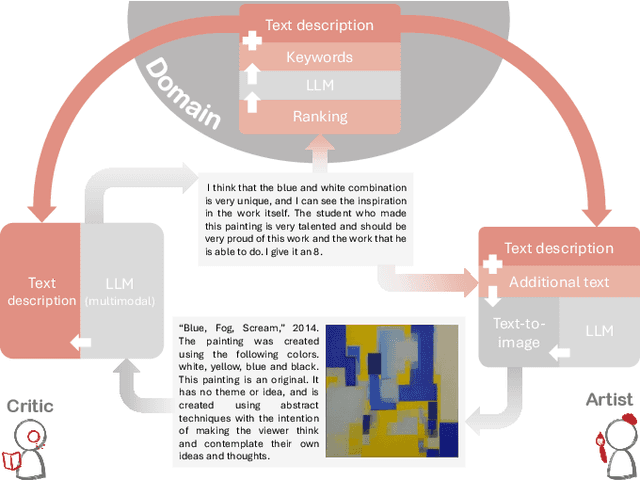
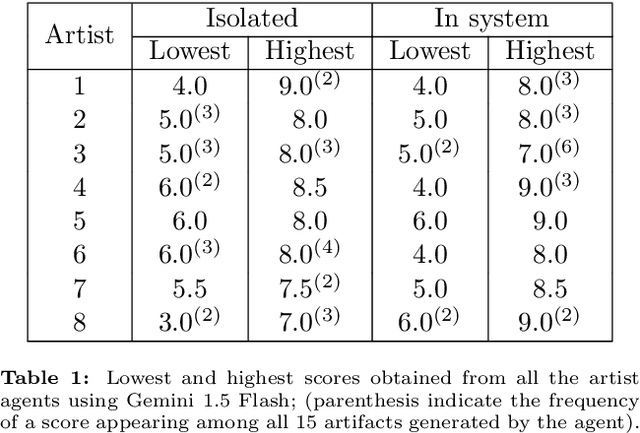
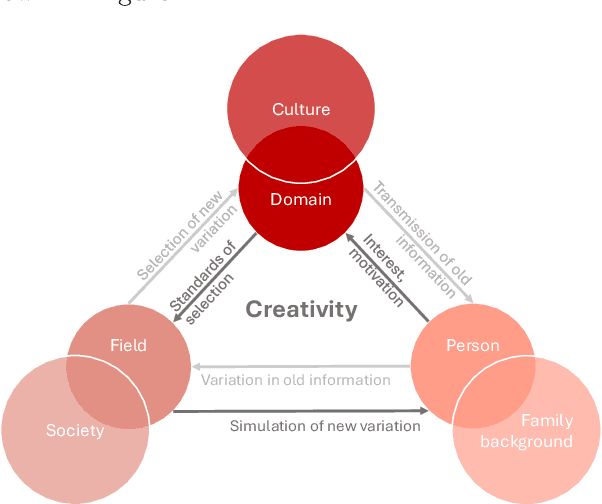
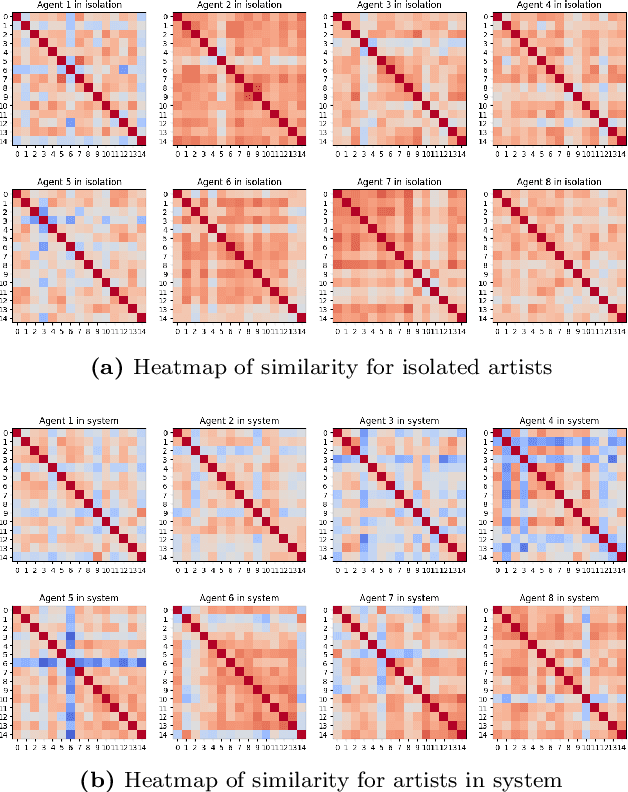
With the growing popularity of generative AI for images, video, and music, we witnessed models rapidly improve in quality and performance. However, not much attention is paid towards enabling AI's ability to "be creative". In this study, we implemented and simulated the systems model of creativity (proposed by Csikszentmihalyi) using virtual agents utilizing large language models (LLMs) and text prompts. For comparison, the simulations were conducted with the "virtual artists" being: 1)isolated and 2)placed in a multi-agent system. Both scenarios were compared by analyzing the variations and overall "creativity" in the generated artifacts (measured via a user study and LLM). Our results suggest that the generative agents may perform better in the framework of the systems model of creativity.
Data-Efficient Approach to Humanoid Control via Fine-Tuning a Pre-Trained GPT on Action Data
May 29, 2024



There are several challenges in developing a model for multi-tasking humanoid control. Reinforcement learning and imitation learning approaches are quite popular in this domain. However, there is a trade-off between the two. Reinforcement learning is not the best option for training a humanoid to perform multiple behaviors due to training time and model size, and imitation learning using kinematics data alone is not appropriate to realize the actual physics of the motion. Training models to perform multiple complex tasks take long training time due to high DoF and complexities of the movements. Although training models offline would be beneficial, another issue is the size of the dataset, usually being quite large to encapsulate multiple movements. Many papers have implemented state of the art deep learning models such as transformers to control humanoid characters and predict their motion based on a large dataset of recorded/reference motion. In this paper, we train a GPT on a large dataset of noisy expert policy rollout observations from a humanoid motion dataset as a pre-trained model and fine tune that model on a smaller dataset of noisy expert policy rollout observations and actions to autoregressively generate physically plausible motion trajectories. We show that it is possible to train a GPT-based foundation model on a smaller dataset in shorter training time to control a humanoid in a realistic physics environment to perform human-like movements.
Study of Emotion Concept Formation by Integrating Vision, Physiology, and Word Information using Multilayered Multimodal Latent Dirichlet Allocation
Apr 12, 2024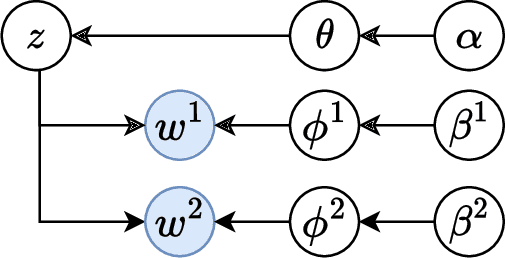
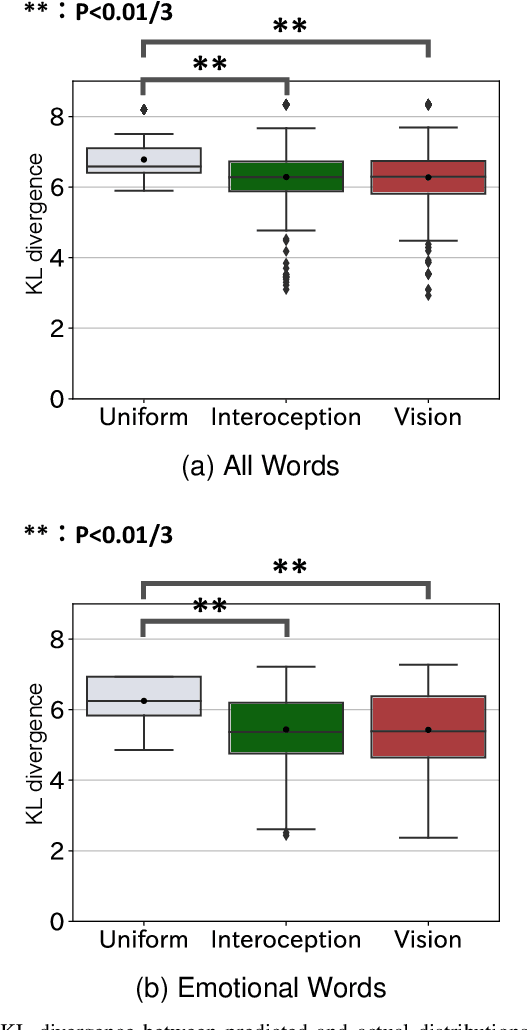
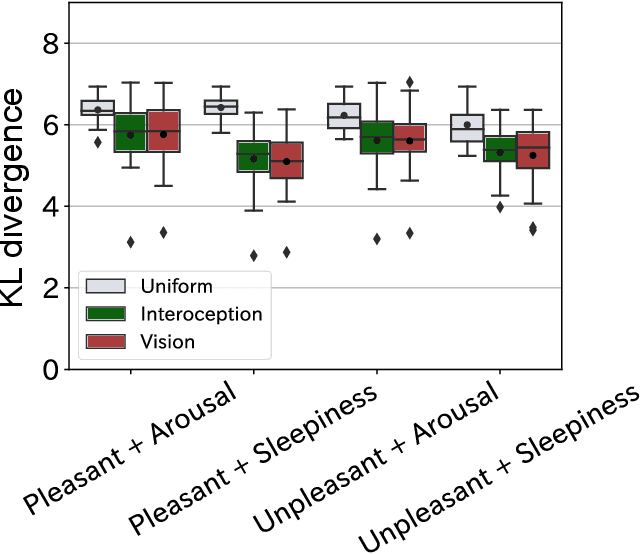
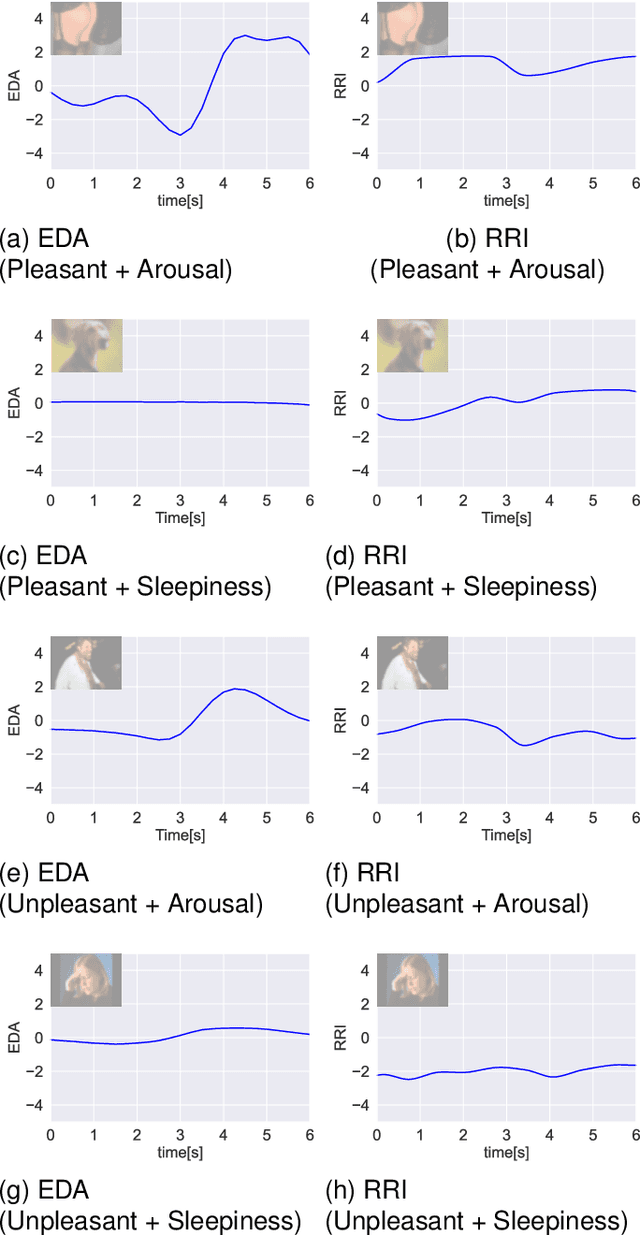
How are emotions formed? Through extensive debate and the promulgation of diverse theories , the theory of constructed emotion has become prevalent in recent research on emotions. According to this theory, an emotion concept refers to a category formed by interoceptive and exteroceptive information associated with a specific emotion. An emotion concept stores past experiences as knowledge and can predict unobserved information from acquired information. Therefore, in this study, we attempted to model the formation of emotion concepts using a constructionist approach from the perspective of the constructed emotion theory. Particularly, we constructed a model using multilayered multimodal latent Dirichlet allocation , which is a probabilistic generative model. We then trained the model for each subject using vision, physiology, and word information obtained from multiple people who experienced different visual emotion-evoking stimuli. To evaluate the model, we verified whether the formed categories matched human subjectivity and determined whether unobserved information could be predicted via categories. The verification results exceeded chance level, suggesting that emotion concept formation can be explained by the proposed model.
A Framework of Explanation Generation toward Reliable Autonomous Robots
May 06, 2021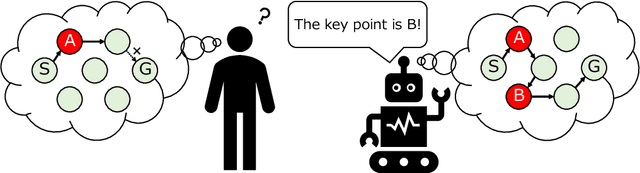

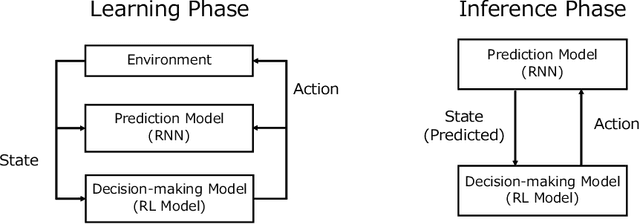
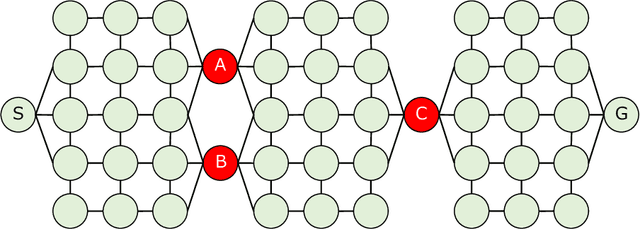
To realize autonomous collaborative robots, it is important to increase the trust that users have in them. Toward this goal, this paper proposes an algorithm which endows an autonomous agent with the ability to explain the transition from the current state to the target state in a Markov decision process (MDP). According to cognitive science, to generate an explanation that is acceptable to humans, it is important to present the minimum information necessary to sufficiently understand an event. To meet this requirement, this study proposes a framework for identifying important elements in the decision-making process using a prediction model for the world and generating explanations based on these elements. To verify the ability of the proposed method to generate explanations, we conducted an experiment using a grid environment. It was inferred from the result of a simulation experiment that the explanation generated using the proposed method was composed of the minimum elements important for understanding the transition from the current state to the target state. Furthermore, subject experiments showed that the generated explanation was a good summary of the process of state transition, and that a high evaluation was obtained for the explanation of the reason for an action.
lamBERT: Language and Action Learning Using Multimodal BERT
Apr 15, 2020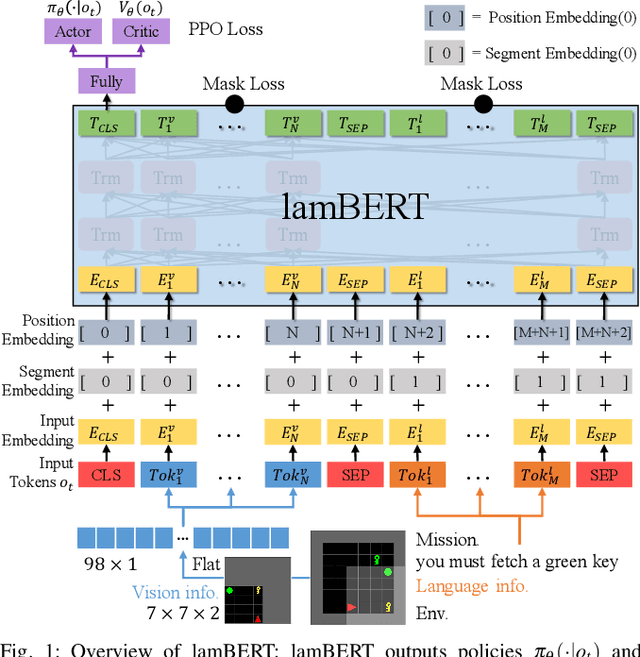
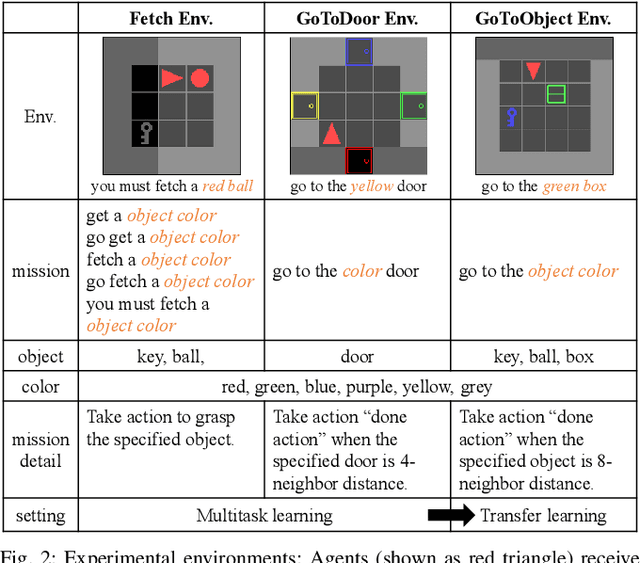
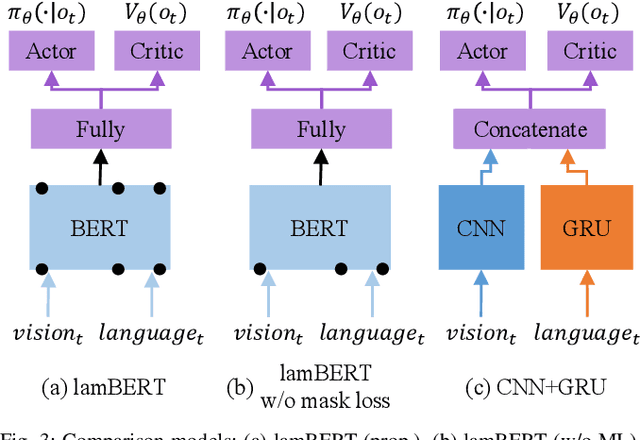
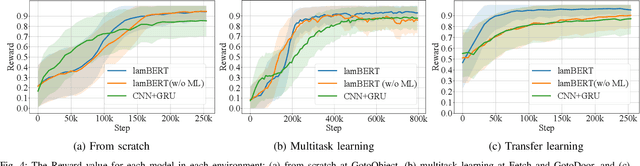
Recently, the bidirectional encoder representations from transformers (BERT) model has attracted much attention in the field of natural language processing, owing to its high performance in language understanding-related tasks. The BERT model learns language representation that can be adapted to various tasks via pre-training using a large corpus in an unsupervised manner. This study proposes the language and action learning using multimodal BERT (lamBERT) model that enables the learning of language and actions by 1) extending the BERT model to multimodal representation and 2) integrating it with reinforcement learning. To verify the proposed model, an experiment is conducted in a grid environment that requires language understanding for the agent to act properly. As a result, the lamBERT model obtained higher rewards in multitask settings and transfer settings when compared to other models, such as the convolutional neural network-based model and the lamBERT model without pre-training.