 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgelamBERT: Language and Action Learning Using Multimodal BERT
Paper and Code
Apr 15, 2020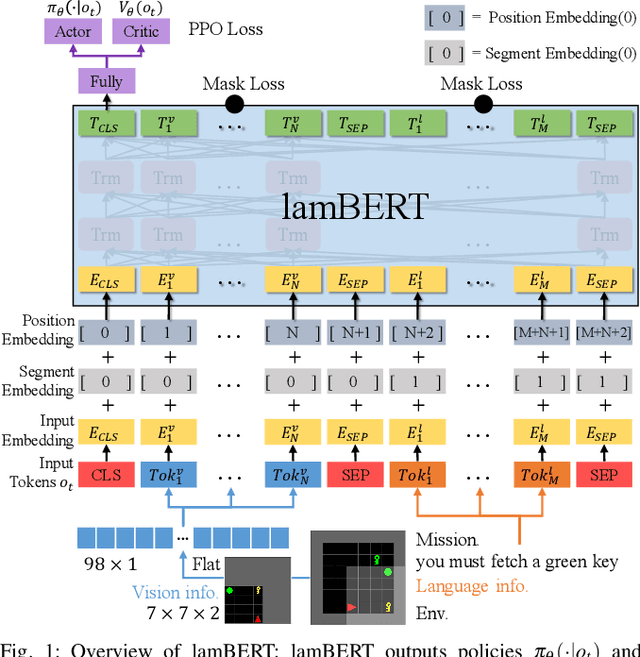
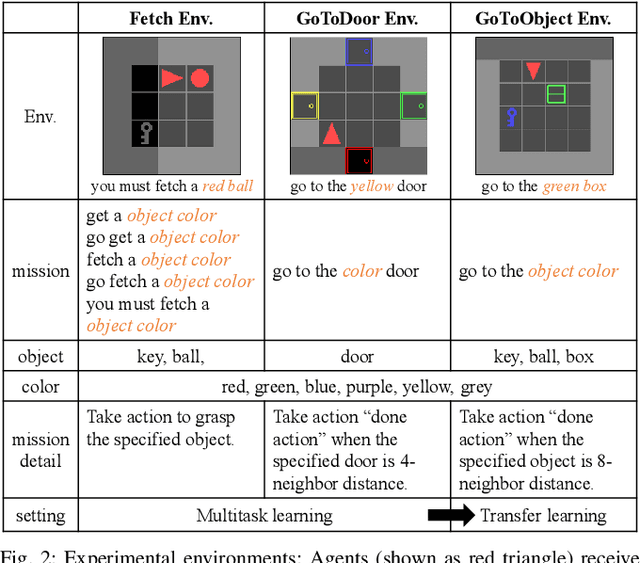
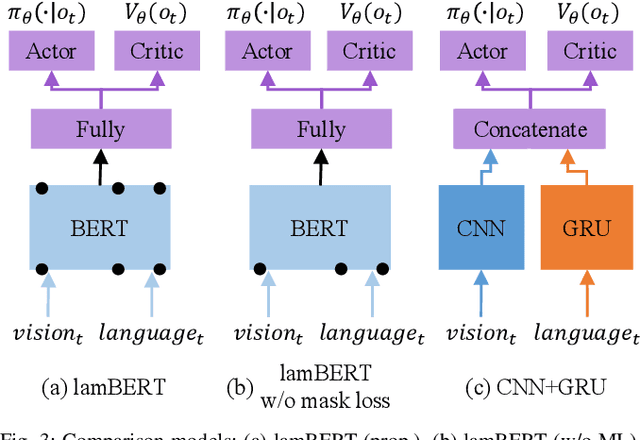
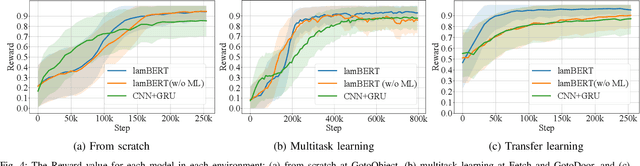
Recently, the bidirectional encoder representations from transformers (BERT) model has attracted much attention in the field of natural language processing, owing to its high performance in language understanding-related tasks. The BERT model learns language representation that can be adapted to various tasks via pre-training using a large corpus in an unsupervised manner. This study proposes the language and action learning using multimodal BERT (lamBERT) model that enables the learning of language and actions by 1) extending the BERT model to multimodal representation and 2) integrating it with reinforcement learning. To verify the proposed model, an experiment is conducted in a grid environment that requires language understanding for the agent to act properly. As a result, the lamBERT model obtained higher rewards in multitask settings and transfer settings when compared to other models, such as the convolutional neural network-based model and the lamBERT model without pre-training.