 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$q$-Munchausen Reinforcement Learning
Paper and Code
May 16, 2022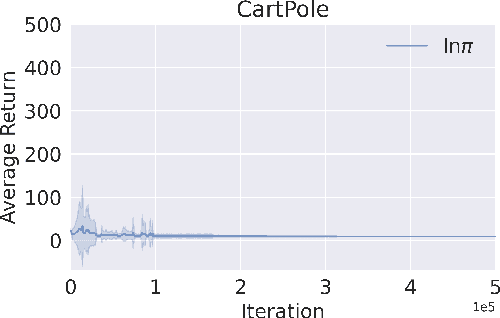

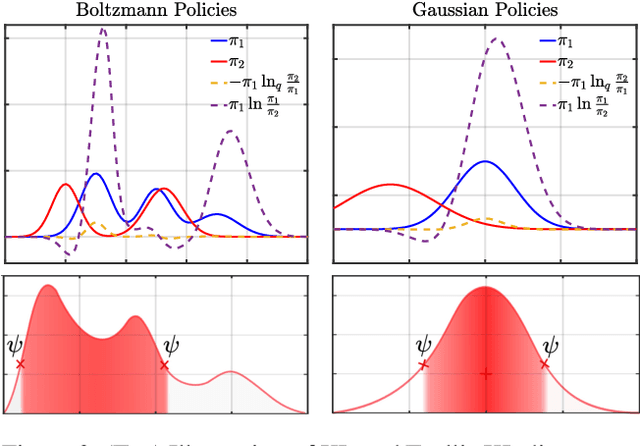
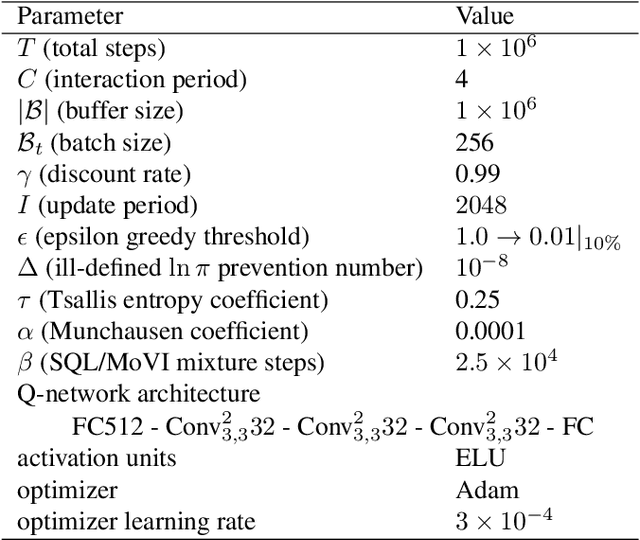
The recently successful Munchausen Reinforcement Learning (M-RL) features implicit Kullback-Leibler (KL) regularization by augmenting the reward function with logarithm of the current stochastic policy. Though significant improvement has been shown with the Boltzmann softmax policy, when the Tsallis sparsemax policy is considered, the augmentation leads to a flat learning curve for almost every problem considered. We show that it is due to the mismatch between the conventional logarithm and the non-logarithmic (generalized) nature of Tsallis entropy. Drawing inspiration from the Tsallis statistics literature, we propose to correct the mismatch of M-RL with the help of $q$-logarithm/exponential functions. The proposed formulation leads to implicit Tsallis KL regularization under the maximum Tsallis entropy framework. We show such formulation of M-RL again achieves superior performance on benchmark problems and sheds light on more general M-RL with various entropic indices $q$.