 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-Quantized Actor-Critic Algorithm for Robustness to Noisy Temporal Difference Error
Apr 02, 2026In reinforcement learning (RL), temporal difference (TD) errors are widely adopted for optimizing value and policy functions. However, since the TD error is defined by a bootstrap method, its computation tends to be noisy and destabilize learning. Heuristics to improve the accuracy of TD errors, such as target networks and ensemble models, have been introduced so far. While these are essential approaches for the current deep RL algorithms, they cause side effects like increased computational cost and reduced learning efficiency. Therefore, this paper revisits the TD learning algorithm based on control as inference, deriving a novel algorithm capable of robust learning against noisy TD errors. First, the distribution model of optimality, a binary random variable, is represented by a sigmoid function. Alongside forward and reverse Kullback-Leibler divergences, this new model derives a robust learning rule: when the sigmoid function saturates with a large TD error probably due to noise, the gradient vanishes, implicitly excluding it from learning. Furthermore, the two divergences exhibit distinct gradient-vanishing characteristics. Building on these analyses, the optimality is decomposed into multiple levels to achieve pseudo-quantization of TD errors, aiming for further noise reduction. Additionally, a Jensen-Shannon divergence-based approach is approximately derived to inherit the characteristics of both divergences. These benefits are verified through RL benchmarks, demonstrating stable learning even when heuristics are insufficient or rewards contain noise.
CubeDAgger: Improved Robustness of Interactive Imitation Learning without Violation of Dynamic Stability
May 08, 2025Interactive imitation learning makes an agent's control policy robust by stepwise supervisions from an expert. The recent algorithms mostly employ expert-agent switching systems to reduce the expert's burden by limitedly selecting the supervision timing. However, the precise selection is difficult and such a switching causes abrupt changes in actions, damaging the dynamic stability. This paper therefore proposes a novel method, so-called CubeDAgger, which improves robustness while reducing dynamic stability violations by making three improvements to a baseline method, EnsembleDAgger. The first improvement adds a regularization to explicitly activate the threshold for deciding the supervision timing. The second transforms the expert-agent switching system to an optimal consensus system of multiple action candidates. Third, autoregressive colored noise to the actions is introduced to make the stochastic exploration consistent over time. These improvements are verified by simulations, showing that the learned policies are sufficiently robust while maintaining dynamic stability during interaction.
Improvements of Dark Experience Replay and Reservoir Sampling towards Better Balance between Consolidation and Plasticity
Apr 29, 2025Continual learning is the one of the most essential abilities for autonomous agents, which can incrementally learn daily-life skills. For this ultimate goal, a simple but powerful method, dark experience replay (DER), has been proposed recently. DER mitigates catastrophic forgetting, in which the skills acquired in the past are unintentionally forgotten, by stochastically storing the streaming data in a reservoir sampling (RS) buffer and by relearning them or retaining the past outputs for them. However, since DER considers multiple objectives, it will not function properly without appropriate weighting of them. In addition, the ability to retain past outputs inhibits learning if the past outputs are incorrect due to distribution shift or other effects. This is due to a tradeoff between memory consolidation and plasticity. The tradeoff is hidden even in the RS buffer, which gradually stops storing new data for new skills in it as data is continuously passed to it. To alleviate the tradeoff and achieve better balance, this paper proposes improvement strategies to each of DER and RS. Specifically, DER is improved with automatic adaptation of weights, block of replaying erroneous data, and correction of past outputs. RS is also improved with generalization of acceptance probability, stratification of plural buffers, and intentional omission of unnecessary data. These improvements are verified through multiple benchmarks including regression, classification, and reinforcement learning problems. As a result, the proposed methods achieve steady improvements in learning performance by balancing the memory consolidation and plasticity.
Weber-Fechner Law in Temporal Difference learning derived from Control as Inference
Dec 30, 2024



This paper investigates a novel nonlinear update rule based on temporal difference (TD) errors in reinforcement learning (RL). The update rule in the standard RL states that the TD error is linearly proportional to the degree of updates, treating all rewards equally without no bias. On the other hand, the recent biological studies revealed that there are nonlinearities in the TD error and the degree of updates, biasing policies optimistic or pessimistic. Such biases in learning due to nonlinearities are expected to be useful and intentionally leftover features in biological learning. Therefore, this research explores a theoretical framework that can leverage the nonlinearity between the degree of the update and TD errors. To this end, we focus on a control as inference framework, since it is known as a generalized formulation encompassing various RL and optimal control methods. In particular, we investigate the uncomputable nonlinear term needed to be approximately excluded in the derivation of the standard RL from control as inference. By analyzing it, Weber-Fechner law (WFL) is found, namely, perception (a.k.a. the degree of updates) in response to stimulus change (a.k.a. TD error) is attenuated by increase in the stimulus intensity (a.k.a. the value function). To numerically reveal the utilities of WFL on RL, we then propose a practical implementation using a reward-punishment framework and modifying the definition of optimality. Analysis of this implementation reveals that two utilities can be expected i) to increase rewards to a certain level early, and ii) to sufficiently suppress punishment. We finally investigate and discuss the expected utilities through simulations and robot experiments. As a result, the proposed RL algorithm with WFL shows the expected utilities that accelerate the reward-maximizing startup and continue to suppress punishments during learning.
Design of Restricted Normalizing Flow towards Arbitrary Stochastic Policy with Computational Efficiency
Dec 17, 2024This paper proposes a new design method for a stochastic control policy using a normalizing flow (NF). In reinforcement learning (RL), the policy is usually modeled as a distribution model with trainable parameters. When this parameterization has less expressiveness, it would fail to acquiring the optimal policy. A mixture model has capability of a universal approximation, but it with too much redundancy increases the computational cost, which can become a bottleneck when considering the use of real-time robot control. As another approach, NF, which is with additional parameters for invertible transformation from a simple stochastic model as a base, is expected to exert high expressiveness and lower computational cost. However, NF cannot compute its mean analytically due to complexity of the invertible transformation, and it lacks reliability because it retains stochastic behaviors after deployment for robot controller. This paper therefore designs a restricted NF (RNF) that achieves an analytic mean by appropriately restricting the invertible transformation. In addition, the expressiveness impaired by this restriction is regained using bimodal student-t distribution as its base, so-called Bit-RNF. In RL benchmarks, Bit-RNF policy outperformed the previous models. Finally, a real robot experiment demonstrated the applicability of Bit-RNF policy to real world. The attached video is uploaded on youtube: https://youtu.be/R_GJVZDW9bk
* 27 pages, 13 figures
DROP: Distributional and Regular Optimism and Pessimism for Reinforcement Learning
Oct 22, 2024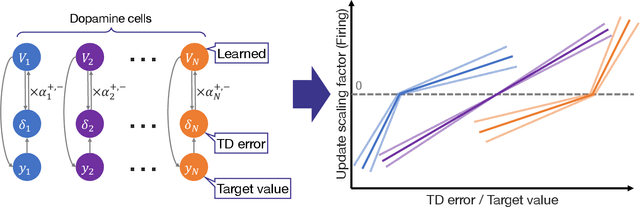

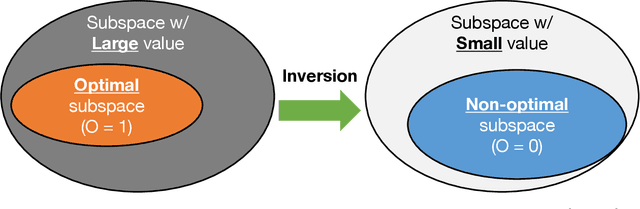
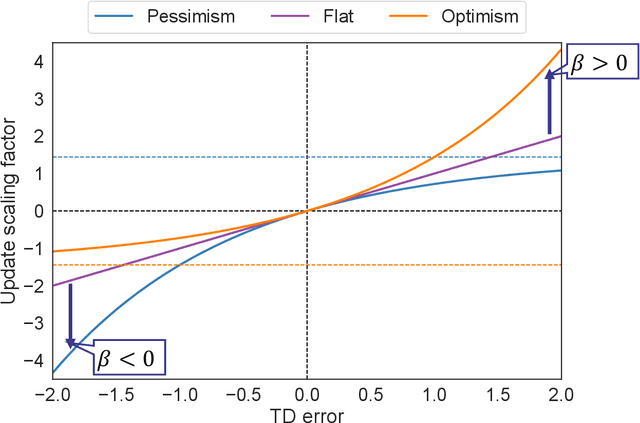
In reinforcement learning (RL), temporal difference (TD) error is known to be related to the firing rate of dopamine neurons. It has been observed that each dopamine neuron does not behave uniformly, but each responds to the TD error in an optimistic or pessimistic manner, interpreted as a kind of distributional RL. To explain such a biological data, a heuristic model has also been designed with learning rates asymmetric for the positive and negative TD errors. However, this heuristic model is not theoretically-grounded and unknown whether it can work as a RL algorithm. This paper therefore introduces a novel theoretically-grounded model with optimism and pessimism, which is derived from control as inference. In combination with ensemble learning, a distributional value function as a critic is estimated from regularly introduced optimism and pessimism. Based on its central value, a policy in an actor is improved. This proposed algorithm, so-called DROP (distributional and regular optimism and pessimism), is compared on dynamic tasks. Although the heuristic model showed poor learning performance, DROP showed excellent one in all tasks with high generality. In other words, it was suggested that DROP is a new model that can elicit the potential contributions of optimism and pessimism.
Domains as Objectives: Domain-Uncertainty-Aware Policy Optimization through Explicit Multi-Domain Convex Coverage Set Learning
Oct 07, 2024The problem of uncertainty is a feature of real world robotics problems and any control framework must contend with it in order to succeed in real applications tasks. Reinforcement Learning is no different, and epistemic uncertainty arising from model uncertainty or misspecification is a challenge well captured by the sim-to-real gap. A simple solution to this issue is domain randomization (DR), which unfortunately can result in conservative agents. As a remedy to this conservativeness, the use of universal policies that take additional information about the randomized domain has risen as an alternative solution, along with recurrent neural network-based controllers. Uncertainty-aware universal policies present a particularly compelling solution able to account for system identification uncertainties during deployment. In this paper, we reveal that the challenge of efficiently optimizing uncertainty-aware policies can be fundamentally reframed as solving the convex coverage set (CCS) problem within a multi-objective reinforcement learning (MORL) context. By introducing a novel Markov decision process (MDP) framework where each domain's performance is treated as an independent objective, we unify the training of uncertainty-aware policies with MORL approaches. This connection enables the application of MORL algorithms for domain randomization (DR), allowing for more efficient policy optimization. To illustrate this, we focus on the linear utility function, which aligns with the expectation in DR formulations, and propose a series of algorithms adapted from the MORL literature to solve the CCS, demonstrating their ability to enhance the performance of uncertainty-aware policies.
LiRA: Light-Robust Adversary for Model-based Reinforcement Learning in Real World
Sep 29, 2024Model-based reinforcement learning has attracted much attention due to its high sample efficiency and is expected to be applied to real-world robotic applications. In the real world, as unobservable disturbances can lead to unexpected situations, robot policies should be taken to improve not only control performance but also robustness. Adversarial learning is an effective way to improve robustness, but excessive adversary would increase the risk of malfunction, and make the control performance too conservative. Therefore, this study addresses a new adversarial learning framework to make reinforcement learning robust moderately and not conservative too much. To this end, the adversarial learning is first rederived with variational inference. In addition, light robustness, which allows for maximizing robustness within an acceptable performance degradation, is utilized as a constraint. As a result, the proposed framework, so-called LiRA, can automatically adjust adversary level, balancing robustness and conservativeness. The expected behaviors of LiRA are confirmed in numerical simulations. In addition, LiRA succeeds in learning a force-reactive gait control of a quadrupedal robot only with real-world data collected less than two hours.
Revisiting Experience Replayable Conditions
Feb 15, 2024Experience replay (ER) used in (deep) reinforcement learning is considered to be applicable only to off-policy algorithms. However, there have been some cases in which ER has been applied for on-policy algorithms, suggesting that off-policyness might be a sufficient condition for applying ER. This paper reconsiders more strict "experience replayable conditions" (ERC) and proposes the way of modifying the existing algorithms to satisfy ERC. To this end, instability of policy improvements is assumed to be a key in ERC. The instability factors are revealed from the viewpoint of metric learning as i) repulsive forces from negative samples and ii) replays of inappropriate experiences. Accordingly, the corresponding stabilization tricks are derived. As a result, it is confirmed through numerical simulations that the proposed stabilization tricks make ER applicable to an advantage actor-critic, an on-policy algorithm. In addition, its learning performance is comparable to that of a soft actor-critic, a state-of-the-art off-policy algorithm.
Intentionally-underestimated Value Function at Terminal State for Temporal-difference Learning with Mis-designed Reward
Aug 24, 2023



Robot control using reinforcement learning has become popular, but its learning process generally terminates halfway through an episode for safety and time-saving reasons. This study addresses the problem of the most popular exception handling that temporal-difference (TD) learning performs at such termination. That is, by forcibly assuming zero value after termination, unintentionally implicit underestimation or overestimation occurs, depending on the reward design in the normal states. When the episode is terminated due to task failure, the failure may be highly valued with the unintentional overestimation, and the wrong policy may be acquired. Although this problem can be avoided by paying attention to the reward design, it is essential in practical use of TD learning to review the exception handling at termination. This paper therefore proposes a method to intentionally underestimate the value after termination to avoid learning failures due to the unintentional overestimation. In addition, the degree of underestimation is adjusted according to the degree of stationarity at termination, thereby preventing excessive exploration due to the intentional underestimation. Simulations and real robot experiments showed that the proposed method can stably obtain the optimal policies for various tasks and reward designs. https://youtu.be/AxXr8uFOe7M