 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Actor-Critic Algorithm with Truly Inequality Constraint
Paper and Code
Mar 08, 2023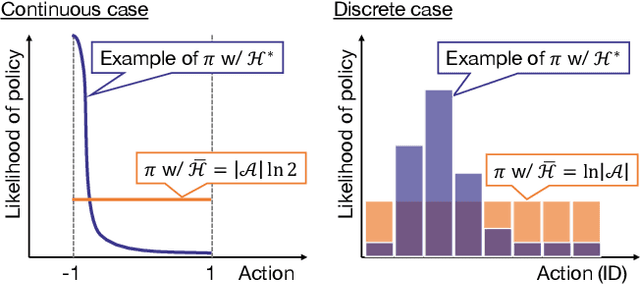
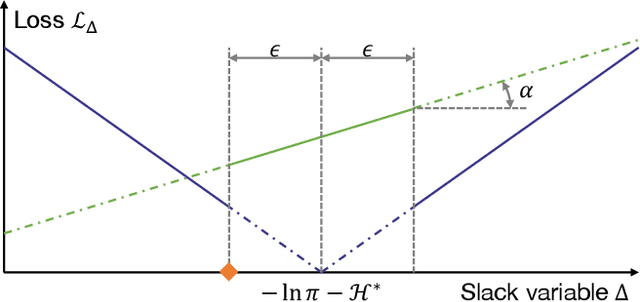
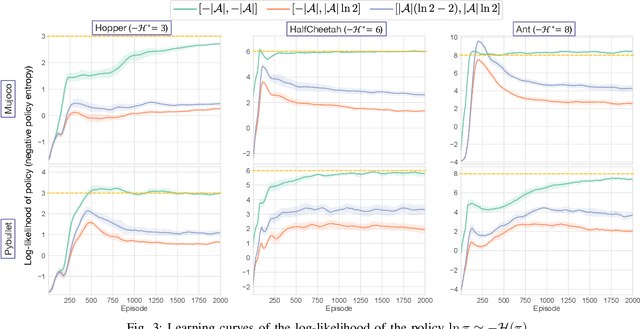
Soft actor-critic (SAC) in reinforcement learning is expected to be one of the next-generation robot control schemes. Its ability to maximize policy entropy would make a robotic controller robust to noise and perturbation, which is useful for real-world robot applications. However, the priority of maximizing the policy entropy is automatically tuned in the current implementation, the rule of which can be interpreted as one for equality constraint, binding the policy entropy into its specified target value. The current SAC is therefore no longer maximize the policy entropy, contrary to our expectation. To resolve this issue in SAC, this paper improves its implementation with a slack variable for appropriately handling the inequality constraint to maximize the policy entropy. In Mujoco and Pybullet simulators, the modified SAC achieved the higher robustness and the more stable learning than before while regularizing the norm of action. In addition, a real-robot variable impedance task was demonstrated for showing the applicability of the modified SAC to real-world robot control.