 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnforcing KL Regularization in General Tsallis Entropy Reinforcement Learning via Advantage Learning
Paper and Code
May 16, 2022

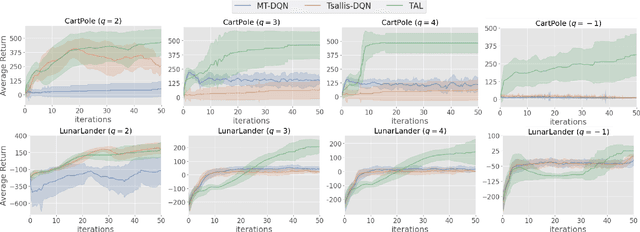

Maximum Tsallis entropy (MTE) framework in reinforcement learning has gained popularity recently by virtue of its flexible modeling choices including the widely used Shannon entropy and sparse entropy. However, non-Shannon entropies suffer from approximation error and subsequent underperformance either due to its sensitivity or the lack of closed-form policy expression. To improve the tradeoff between flexibility and empirical performance, we propose to strengthen their error-robustness by enforcing implicit Kullback-Leibler (KL) regularization in MTE motivated by Munchausen DQN (MDQN). We do so by drawing connection between MDQN and advantage learning, by which MDQN is shown to fail on generalizing to the MTE framework. The proposed method Tsallis Advantage Learning (TAL) is verified on extensive experiments to not only significantly improve upon Tsallis-DQN for various non-closed-form Tsallis entropies, but also exhibits comparable performance to state-of-the-art maximum Shannon entropy algorithms.