 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Based Imitation Learning Using Entropy Regularization of Model and Policy
Paper and Code
Jun 21, 2022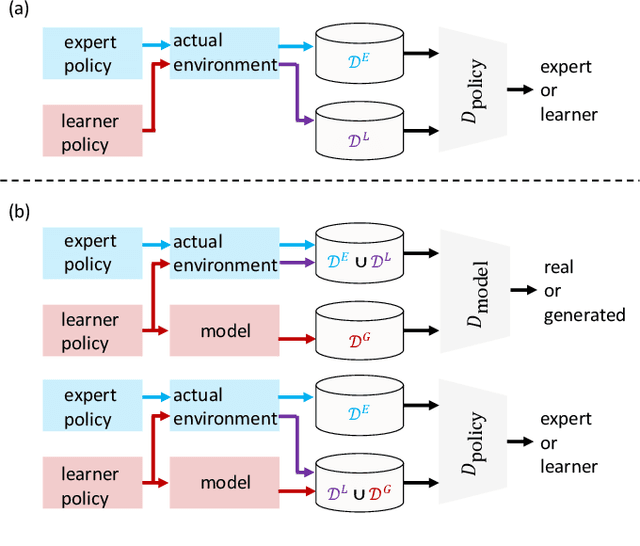
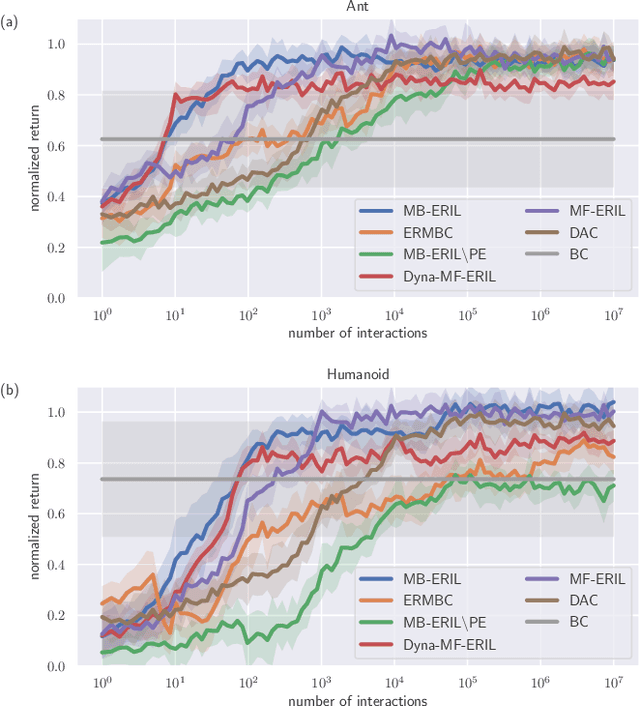

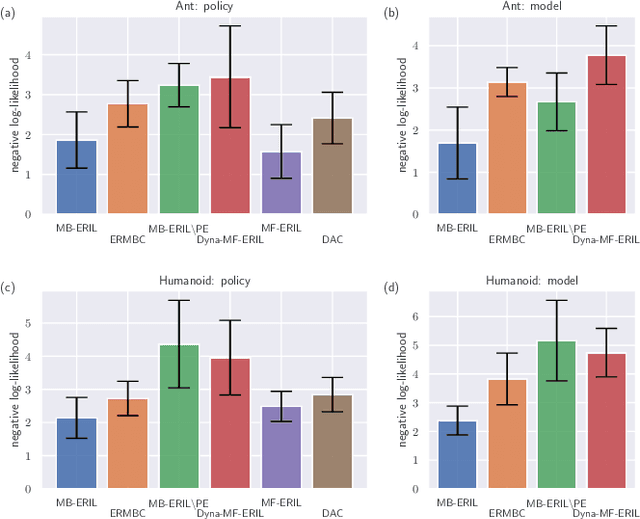
Approaches based on generative adversarial networks for imitation learning are promising because they are sample efficient in terms of expert demonstrations. However, training a generator requires many interactions with the actual environment because model-free reinforcement learning is adopted to update a policy. To improve the sample efficiency using model-based reinforcement learning, we propose model-based Entropy-Regularized Imitation Learning (MB-ERIL) under the entropy-regularized Markov decision process to reduce the number of interactions with the actual environment. MB-ERIL uses two discriminators. A policy discriminator distinguishes the actions generated by a robot from expert ones, and a model discriminator distinguishes the counterfactual state transitions generated by the model from the actual ones. We derive the structured discriminators so that the learning of the policy and the model is efficient. Computer simulations and real robot experiments show that MB-ERIL achieves a competitive performance and significantly improves the sample efficiency compared to baseline methods.