 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbounded Output Networks for Classification
Jul 25, 2018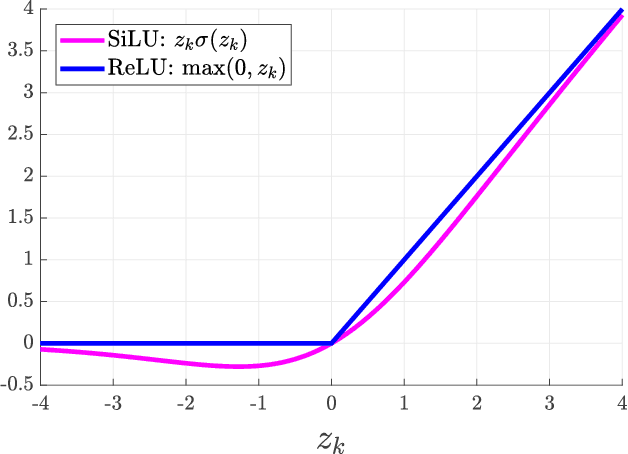
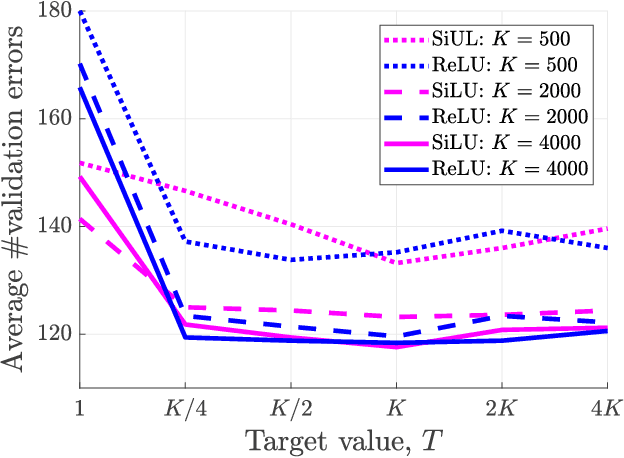

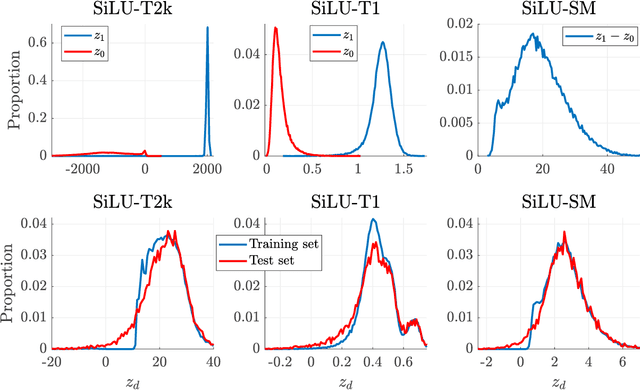
We proposed the expected energy-based restricted Boltzmann machine (EE-RBM) as a discriminative RBM method for classification. Two characteristics of the EE-RBM are that the output is unbounded and that the target value of correct classification is set to a value much greater than one. In this study, by adopting features of the EE-RBM approach to feed-forward neural networks, we propose the UnBounded output network (UBnet) which is characterized by three features: (1) unbounded output units; (2) the target value of correct classification is set to a value much greater than one; and (3) the models are trained by a modified mean-squared error objective. We evaluate our approach using the MNIST, CIFAR-10, and CIFAR-100 benchmark datasets. We first demonstrate, for shallow UBnets on MNIST, that a setting of the target value equal to the number of hidden units significantly outperforms a setting of the target value equal to one, and it also outperforms standard neural networks by about 25\%. We then validate our approach by achieving high-level classification performance on the three datasets using unbounded output residual networks. We finally use MNIST to analyze the learned features and weights, and we demonstrate that UBnets are much more robust against adversarial examples than the standard approach of using a softmax output layer and training the networks by a cross-entropy objective.
Online Meta-learning by Parallel Algorithm Competition
Feb 24, 2017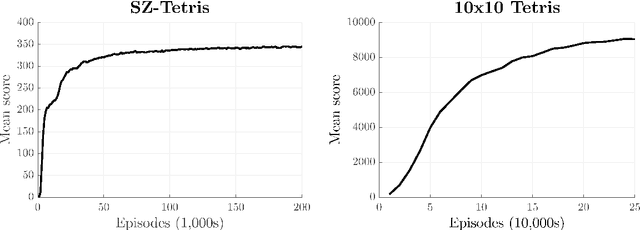


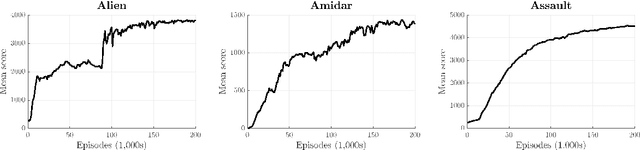
The efficiency of reinforcement learning algorithms depends critically on a few meta-parameters that modulates the learning updates and the trade-off between exploration and exploitation. The adaptation of the meta-parameters is an open question in reinforcement learning, which arguably has become more of an issue recently with the success of deep reinforcement learning in high-dimensional state spaces. The long learning times in domains such as Atari 2600 video games makes it not feasible to perform comprehensive searches of appropriate meta-parameter values. We propose the Online Meta-learning by Parallel Algorithm Competition (OMPAC) method. In the OMPAC method, several instances of a reinforcement learning algorithm are run in parallel with small differences in the initial values of the meta-parameters. After a fixed number of episodes, the instances are selected based on their performance in the task at hand. Before continuing the learning, Gaussian noise is added to the meta-parameters with a predefined probability. We validate the OMPAC method by improving the state-of-the-art results in stochastic SZ-Tetris and in standard Tetris with a smaller, 10$\times$10, board, by 31% and 84%, respectively, and by improving the results for deep Sarsa($\lambda$) agents in three Atari 2600 games by 62% or more. The experiments also show the ability of the OMPAC method to adapt the meta-parameters according to the learning progress in different tasks.