 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentProcessBench: Diagnosing Step-Level Process Quality in Tool-Using Agents
Mar 15, 2026While Large Language Models (LLMs) have evolved into tool-using agents, they remain brittle in long-horizon interactions. Unlike mathematical reasoning where errors are often rectifiable via backtracking, tool-use failures frequently induce irreversible side effects, making accurate step-level verification critical. However, existing process-level benchmarks are predominantly confined to closed-world mathematical domains, failing to capture the dynamic and open-ended nature of tool execution. To bridge this gap, we introduce AgentProcessBench, the first benchmark dedicated to evaluating step-level effectiveness in realistic, tool-augmented trajectories. The benchmark comprises 1,000 diverse trajectories and 8,509 human-labeled step annotations with 89.1% inter-annotator agreement. It features a ternary labeling scheme to capture exploration and an error propagation rule to reduce labeling ambiguity. Extensive experiments reveal key insights: (1) weaker policy models exhibit inflated ratios of correct steps due to early termination; (2) distinguishing neutral and erroneous actions remains a significant challenge for current models; and (3) process-derived signals provide complementary value to outcome supervision, significantly enhancing test-time scaling. We hope AgentProcessBench can foster future research in reward models and pave the way toward general agents. The code and data are available at https://github.com/RUCBM/AgentProcessBench.
Less Noise, More Voice: Reinforcement Learning for Reasoning via Instruction Purification
Jan 29, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has advanced LLM reasoning, but remains constrained by inefficient exploration under limited rollout budgets, leading to low sampling success and unstable training in complex tasks. We find that many exploration failures arise not from problem difficulty, but from a small number of prompt tokens that introduce interference. Building on this insight, we propose the Less Noise Sampling Framework (LENS), which first prompts by identifying and removing interference tokens. then transfers successful rollouts from the purification process to supervise policy optimization on the original noisy prompts, enabling the model to learn to ignore interference in the real-world, noisy prompting settings. Experimental results show that LENS significantly outperforms GRPO, delivering higher performance and faster convergence, with a 3.88% average gain and over 1.6$\times$ speedup. Our work highlights the critical role of pruning interference tokens in improving rollout efficiency, offering a new perspective for RLVR research.
Learning to Focus: Causal Attention Distillation via Gradient-Guided Token Pruning
Jun 09, 2025Large language models (LLMs) have demonstrated significant improvements in contextual understanding. However, their ability to attend to truly critical information during long-context reasoning and generation still falls behind the pace. Specifically, our preliminary experiments reveal that certain distracting patterns can misdirect the model's attention during inference, and removing these patterns substantially improves reasoning accuracy and generation quality. We attribute this phenomenon to spurious correlations in the training data, which obstruct the model's capacity to infer authentic causal instruction-response relationships. This phenomenon may induce redundant reasoning processes, potentially resulting in significant inference overhead and, more critically, the generation of erroneous or suboptimal responses. To mitigate this, we introduce a two-stage framework called Learning to Focus (LeaF) leveraging intervention-based inference to disentangle confounding factors. In the first stage, LeaF employs gradient-based comparisons with an advanced teacher to automatically identify confounding tokens based on causal relationships in the training corpus. Then, in the second stage, it prunes these tokens during distillation to enact intervention, aligning the student's attention with the teacher's focus distribution on truly critical context tokens. Experimental results demonstrate that LeaF not only achieves an absolute improvement in various mathematical reasoning and code generation benchmarks but also effectively suppresses attention to confounding tokens during inference, yielding a more interpretable and reliable reasoning model.
Temporal Dynamics Decoupling with Inverse Processing for Enhancing Human Motion Prediction
Dec 31, 2024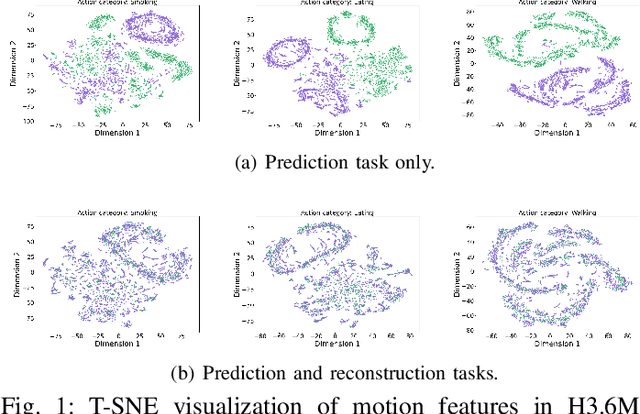
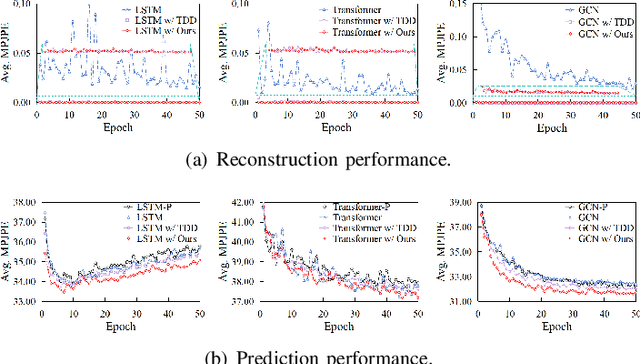
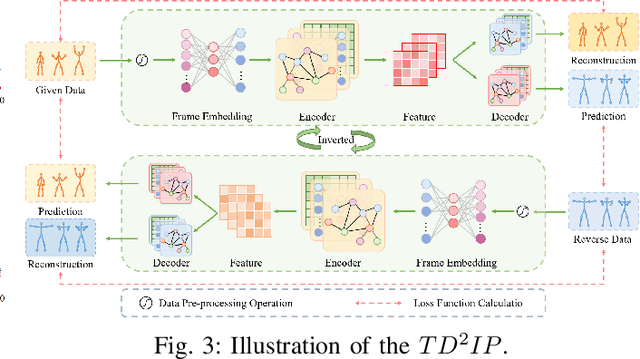
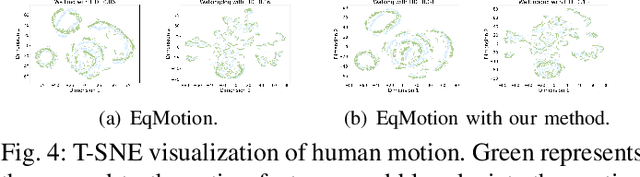
Exploring the bridge between historical and future motion behaviors remains a central challenge in human motion prediction. While most existing methods incorporate a reconstruction task as an auxiliary task into the decoder, thereby improving the modeling of spatio-temporal dependencies, they overlook the potential conflicts between reconstruction and prediction tasks. In this paper, we propose a novel approach: Temporal Decoupling Decoding with Inverse Processing (\textbf{$TD^2IP$}). Our method strategically separates reconstruction and prediction decoding processes, employing distinct decoders to decode the shared motion features into historical or future sequences. Additionally, inverse processing reverses motion information in the temporal dimension and reintroduces it into the model, leveraging the bidirectional temporal correlation of human motion behaviors. By alleviating the conflicts between reconstruction and prediction tasks and enhancing the association of historical and future information, \textbf{$TD^2IP$} fosters a deeper understanding of motion patterns. Extensive experiments demonstrate the adaptability of our method within existing methods.
Spatio-Temporal Multi-Subgraph GCN for 3D Human Motion Prediction
Dec 31, 2024



Human motion prediction (HMP) involves forecasting future human motion based on historical data. Graph Convolutional Networks (GCNs) have garnered widespread attention in this field for their proficiency in capturing relationships among joints in human motion. However, existing GCN-based methods tend to focus on either temporal-domain or spatial-domain features, or they combine spatio-temporal features without fully leveraging the complementarity and cross-dependency of these two features. In this paper, we propose the Spatial-Temporal Multi-Subgraph Graph Convolutional Network (STMS-GCN) to capture complex spatio-temporal dependencies in human motion. Specifically, we decouple the modeling of temporal and spatial dependencies, enabling cross-domain knowledge transfer at multiple scales through a spatio-temporal information consistency constraint mechanism. Besides, we utilize multiple subgraphs to extract richer motion information and enhance the learning associations of diverse subgraphs through a homogeneous information constraint mechanism. Extensive experiments on the standard HMP benchmarks demonstrate the superiority of our method.
Controllable Preference Optimization: Toward Controllable Multi-Objective Alignment
Feb 29, 2024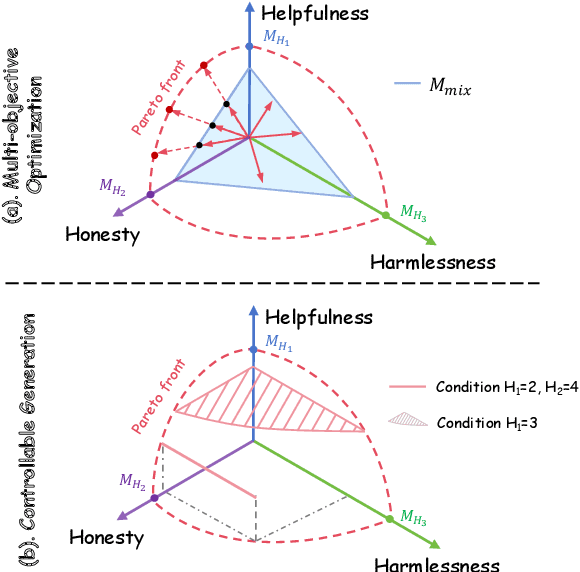
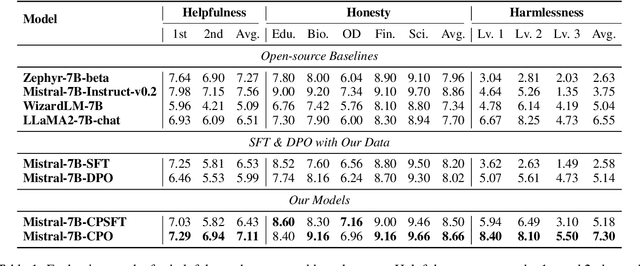
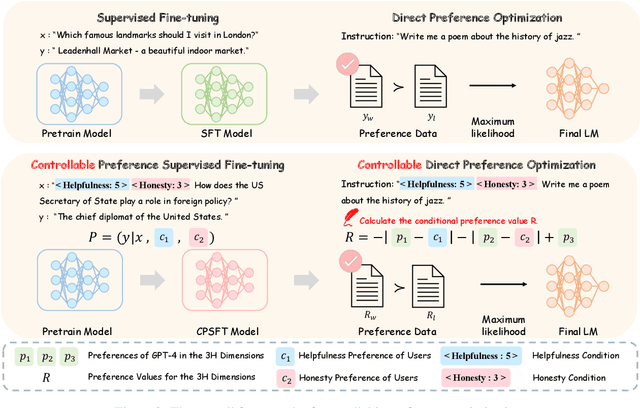

Alignment in artificial intelligence pursues the consistency between model responses and human preferences as well as values. In practice, the multifaceted nature of human preferences inadvertently introduces what is known as the "alignment tax" -a compromise where enhancements in alignment within one objective (e.g.,harmlessness) can diminish performance in others (e.g.,helpfulness). However, existing alignment techniques are mostly unidirectional, leading to suboptimal trade-offs and poor flexibility over various objectives. To navigate this challenge, we argue the prominence of grounding LLMs with evident preferences. We introduce controllable preference optimization (CPO), which explicitly specifies preference scores for different objectives, thereby guiding the model to generate responses that meet the requirements. Our experimental analysis reveals that the aligned models can provide responses that match various preferences among the "3H" (helpfulness, honesty, harmlessness) desiderata. Furthermore, by introducing diverse data and alignment goals, we surpass baseline methods in aligning with single objectives, hence mitigating the impact of the alignment tax and achieving Pareto improvements in multi-objective alignment.