 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Dense Video Grounding via Parallel Regression
Paper and Code
Sep 23, 2021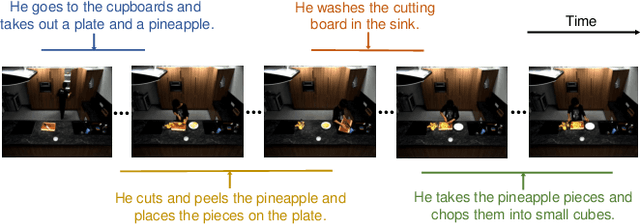
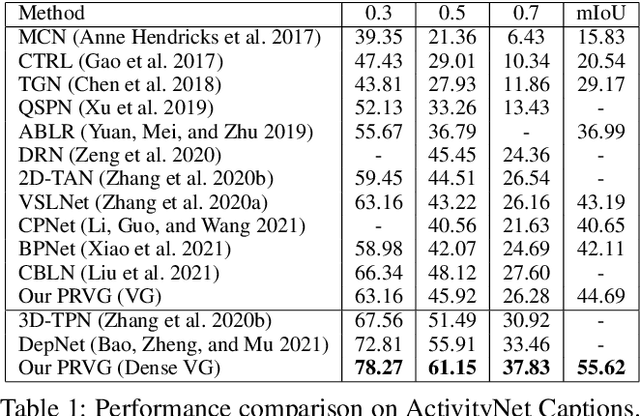
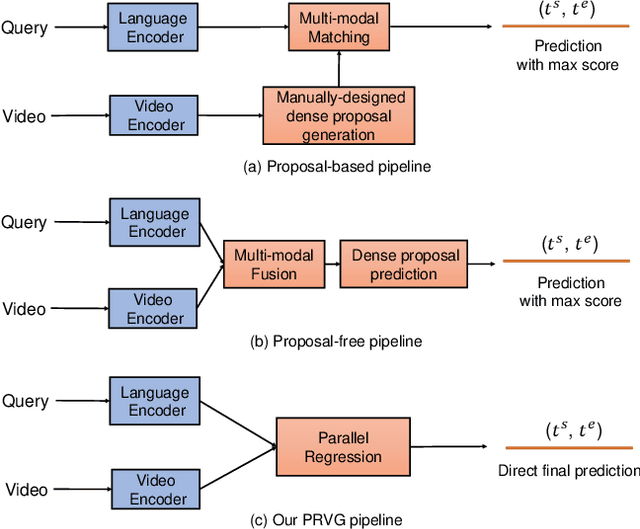
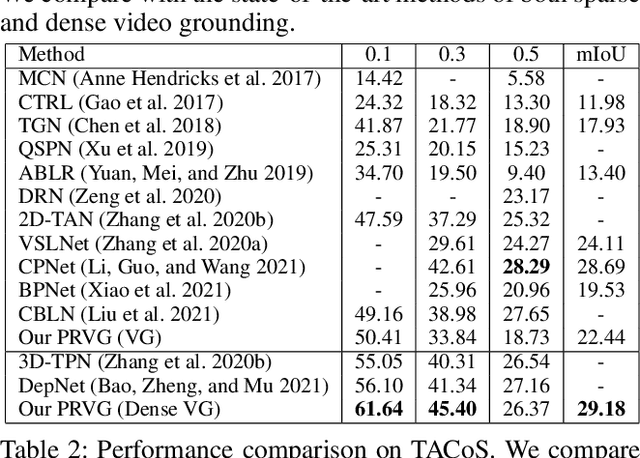
Video grounding aims to localize the corresponding video moment in an untrimmed video given a language query. Existing methods often address this task in an indirect way, by casting it as a proposal-and-match or fusion-and-detection problem. Solving these surrogate problems often requires sophisticated label assignment during training and hand-crafted removal of near-duplicate results. Meanwhile, existing works typically focus on sparse video grounding with a single sentence as input, which could result in ambiguous localization due to its unclear description. In this paper, we tackle a new problem of dense video grounding, by simultaneously localizing multiple moments with a paragraph as input. From a perspective on video grounding as language conditioned regression, we present an end-to-end parallel decoding paradigm by re-purposing a Transformer-alike architecture (PRVG). The key design in our PRVG is to use languages as queries, and directly regress the moment boundaries based on language-modulated visual representations. Thanks to its simplicity in design, our PRVG framework can be applied in different testing schemes (sparse or dense grounding) and allows for efficient inference without any post-processing technique. In addition, we devise a robust proposal-level attention loss to guide the training of PRVG, which is invariant to moment duration and contributes to model convergence. We perform experiments on two video grounding benchmarks of ActivityNet Captions and TACoS, demonstrating that our PRVG can significantly outperform previous methods. We also perform in-depth studies to investigate the effectiveness of parallel regression paradigm on video grounding.