 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Simplify Slide-level Fine-tuning of Pathology Foundation Models?
Feb 28, 2025The emergence of foundation models in computational pathology has transformed histopathological image analysis, with whole slide imaging (WSI) diagnosis being a core application. Traditionally, weakly supervised fine-tuning via multiple instance learning (MIL) has been the primary method for adapting foundation models to WSIs. However, in this work we present a key experimental finding: a simple nonlinear mapping strategy combining mean pooling and a multilayer perceptron, called SiMLP, can effectively adapt patch-level foundation models to slide-level tasks without complex MIL-based learning. Through extensive experiments across diverse downstream tasks, we demonstrate the superior performance of SiMLP with state-of-the-art methods. For instance, on a large-scale pan-cancer classification task, SiMLP surpasses popular MIL-based methods by 3.52%. Furthermore, SiMLP shows strong learning ability in few-shot classification and remaining highly competitive with slide-level foundation models pretrained on tens of thousands of slides. Finally, SiMLP exhibits remarkable robustness and transferability in lung cancer subtyping. Overall, our findings challenge the conventional MIL-based fine-tuning paradigm, demonstrating that a task-agnostic representation strategy alone can effectively adapt foundation models to WSI analysis. These insights offer a unique and meaningful perspective for future research in digital pathology, paving the way for more efficient and broadly applicable methodologies.
Diagnostic Text-guided Representation Learning in Hierarchical Classification for Pathological Whole Slide Image
Nov 16, 2024



With the development of digital imaging in medical microscopy, artificial intelligent-based analysis of pathological whole slide images (WSIs) provides a powerful tool for cancer diagnosis. Limited by the expensive cost of pixel-level annotation, current research primarily focuses on representation learning with slide-level labels, showing success in various downstream tasks. However, given the diversity of lesion types and the complex relationships between each other, these techniques still deserve further exploration in addressing advanced pathology tasks. To this end, we introduce the concept of hierarchical pathological image classification and propose a representation learning called PathTree. PathTree considers the multi-classification of diseases as a binary tree structure. Each category is represented as a professional pathological text description, which messages information with a tree-like encoder. The interactive text features are then used to guide the aggregation of hierarchical multiple representations. PathTree uses slide-text similarity to obtain probability scores and introduces two extra tree specific losses to further constrain the association between texts and slides. Through extensive experiments on three challenging hierarchical classification datasets: in-house cryosectioned lung tissue lesion identification, public prostate cancer grade assessment, and public breast cancer subtyping, our proposed PathTree is consistently competitive compared to the state-of-the-art methods and provides a new perspective on the deep learning-assisted solution for more complex WSI classification.
Task-oriented Embedding Counts: Heuristic Clustering-driven Feature Fine-tuning for Whole Slide Image Classification
Jun 02, 2024



In the field of whole slide image (WSI) classification, multiple instance learning (MIL) serves as a promising approach, commonly decoupled into feature extraction and aggregation. In this paradigm, our observation reveals that discriminative embeddings are crucial for aggregation to the final prediction. Among all feature updating strategies, task-oriented ones can capture characteristics specifically for certain tasks. However, they can be prone to overfitting and contaminated by samples assigned with noisy labels. To address this issue, we propose a heuristic clustering-driven feature fine-tuning method (HC-FT) to enhance the performance of multiple instance learning by providing purified positive and hard negative samples. Our method first employs a well-trained MIL model to evaluate the confidence of patches. Then, patches with high confidence are marked as positive samples, while the remaining patches are used to identify crucial negative samples. After two rounds of heuristic clustering and selection, purified positive and hard negative samples are obtained to facilitate feature fine-tuning. The proposed method is evaluated on both CAMELYON16 and BRACS datasets, achieving an AUC of 97.13% and 85.85%, respectively, consistently outperforming all compared methods.
RetMIL: Retentive Multiple Instance Learning for Histopathological Whole Slide Image Classification
Mar 16, 2024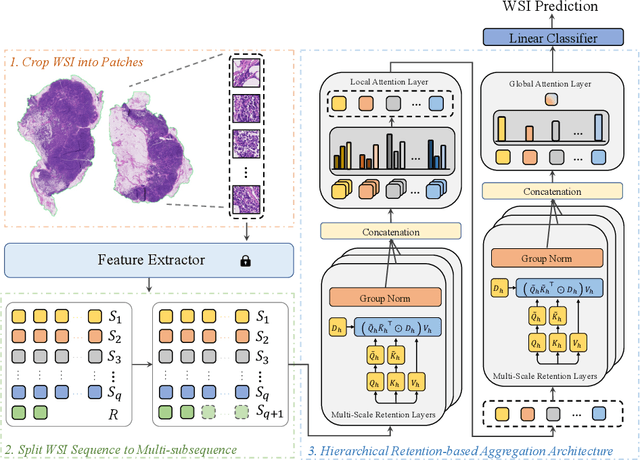
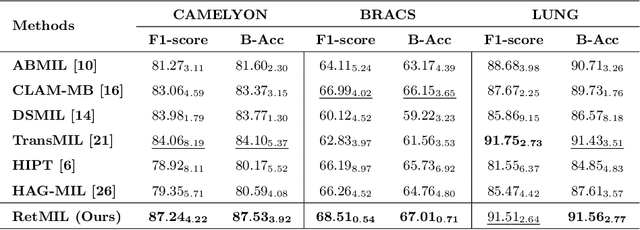
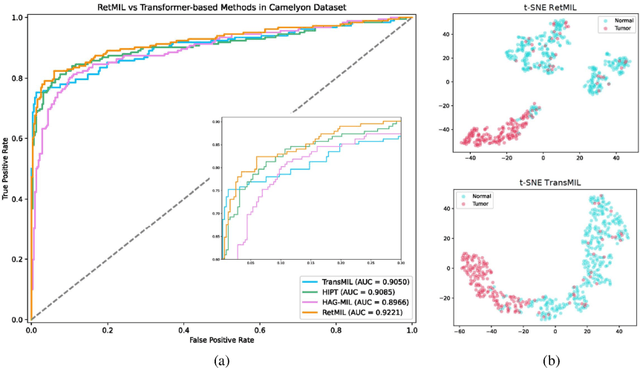
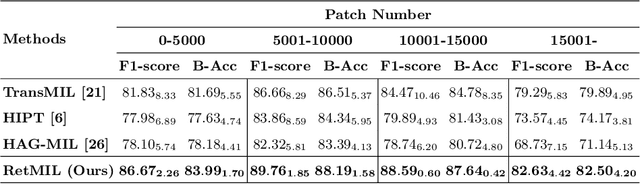
Histopathological whole slide image (WSI) analysis with deep learning has become a research focus in computational pathology. The current paradigm is mainly based on multiple instance learning (MIL), in which approaches with Transformer as the backbone are well discussed. These methods convert WSI tasks into sequence tasks by representing patches as tokens in the WSI sequence. However, the feature complexity brought by high heterogeneity and the ultra-long sequences brought by gigapixel size makes Transformer-based MIL suffer from the challenges of high memory consumption, slow inference speed, and lack of performance. To this end, we propose a retentive MIL method called RetMIL, which processes WSI sequences through hierarchical feature propagation structure. At the local level, the WSI sequence is divided into multiple subsequences. Tokens of each subsequence are updated through a parallel linear retention mechanism and aggregated utilizing an attention layer. At the global level, subsequences are fused into a global sequence, then updated through a serial retention mechanism, and finally the slide-level representation is obtained through a global attention pooling. We conduct experiments on two public CAMELYON and BRACS datasets and an public-internal LUNG dataset, confirming that RetMIL not only achieves state-of-the-art performance but also significantly reduces computational overhead. Our code will be accessed shortly.
Dynamic Graph Representation with Knowledge-aware Attention for Histopathology Whole Slide Image Analysis
Mar 12, 2024



Histopathological whole slide images (WSIs) classification has become a foundation task in medical microscopic imaging processing. Prevailing approaches involve learning WSIs as instance-bag representations, emphasizing significant instances but struggling to capture the interactions between instances. Additionally, conventional graph representation methods utilize explicit spatial positions to construct topological structures but restrict the flexible interaction capabilities between instances at arbitrary locations, particularly when spatially distant. In response, we propose a novel dynamic graph representation algorithm that conceptualizes WSIs as a form of the knowledge graph structure. Specifically, we dynamically construct neighbors and directed edge embeddings based on the head and tail relationships between instances. Then, we devise a knowledge-aware attention mechanism that can update the head node features by learning the joint attention score of each neighbor and edge. Finally, we obtain a graph-level embedding through the global pooling process of the updated head, serving as an implicit representation for the WSI classification. Our end-to-end graph representation learning approach has outperformed the state-of-the-art WSI analysis methods on three TCGA benchmark datasets and in-house test sets. Our code is available at https://github.com/WonderLandxD/WiKG.
Shapley Values-enabled Progressive Pseudo Bag Augmentation for Whole Slide Image Classification
Dec 09, 2023
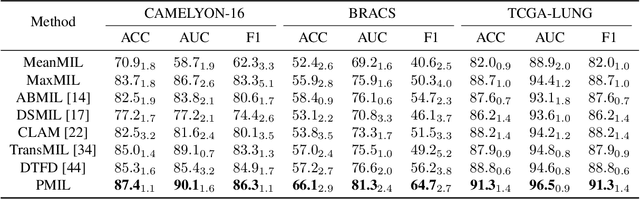
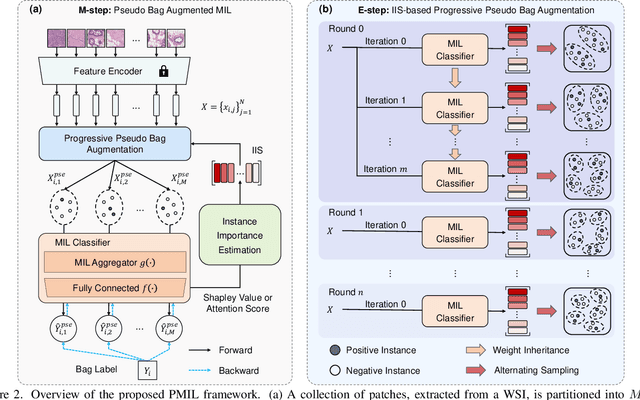

In computational pathology, whole slide image (WSI) classification presents a formidable challenge due to its gigapixel resolution and limited fine-grained annotations. Multiple instance learning (MIL) offers a weakly supervised solution, yet refining instance-level information from bag-level labels remains complex. While most of the conventional MIL methods use attention scores to estimate instance importance scores (IIS) which contribute to the prediction of the slide labels, these often lead to skewed attention distributions and inaccuracies in identifying crucial instances. To address these issues, we propose a new approach inspired by cooperative game theory: employing Shapley values to assess each instance's contribution, thereby improving IIS estimation. The computation of the Shapley value is then accelerated using attention, meanwhile retaining the enhanced instance identification and prioritization. We further introduce a framework for the progressive assignment of pseudo bags based on estimated IIS, encouraging more balanced attention distributions in MIL models. Our extensive experiments on CAMELYON-16, BRACS, and TCGA-LUNG datasets show our method's superiority over existing state-of-the-art approaches, offering enhanced interpretability and class-wise insights. We will release the code upon acceptance.
The Whole Pathological Slide Classification via Weakly Supervised Learning
Jul 12, 2023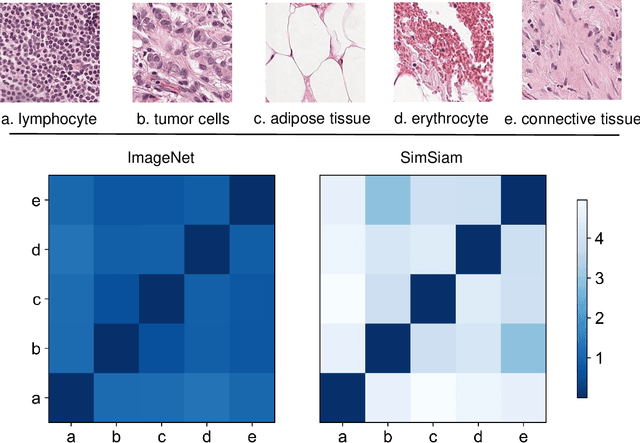
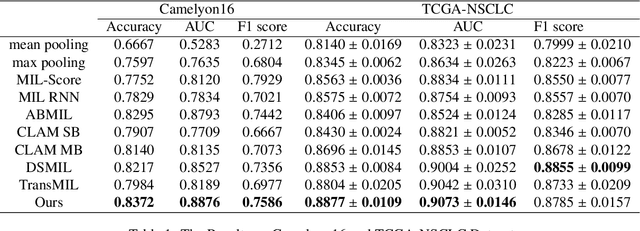
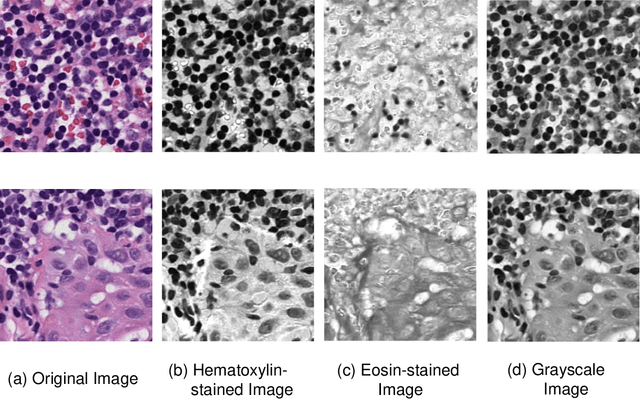

Due to its superior efficiency in utilizing annotations and addressing gigapixel-sized images, multiple instance learning (MIL) has shown great promise as a framework for whole slide image (WSI) classification in digital pathology diagnosis. However, existing methods tend to focus on advanced aggregators with different structures, often overlooking the intrinsic features of H\&E pathological slides. To address this limitation, we introduced two pathological priors: nuclear heterogeneity of diseased cells and spatial correlation of pathological tiles. Leveraging the former, we proposed a data augmentation method that utilizes stain separation during extractor training via a contrastive learning strategy to obtain instance-level representations. We then described the spatial relationships between the tiles using an adjacency matrix. By integrating these two views, we designed a multi-instance framework for analyzing H\&E-stained tissue images based on pathological inductive bias, encompassing feature extraction, filtering, and aggregation. Extensive experiments on the Camelyon16 breast dataset and TCGA-NSCLC Lung dataset demonstrate that our proposed framework can effectively handle tasks related to cancer detection and differentiation of subtypes, outperforming state-of-the-art medical image classification methods based on MIL. The code will be released later.