 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOFL-SAM2: Prompt SAM2 with Online Few-shot Learner for Efficient Medical Image Segmentation
Dec 31, 2025The Segment Anything Model 2 (SAM2) has demonstrated remarkable promptable visual segmentation capabilities in video data, showing potential for extension to medical image segmentation (MIS) tasks involving 3D volumes and temporally correlated 2D image sequences. However, adapting SAM2 to MIS presents several challenges, including the need for extensive annotated medical data for fine-tuning and high-quality manual prompts, which are both labor-intensive and require intervention from medical experts. To address these challenges, we introduce OFL-SAM2, a prompt-free SAM2 framework for label-efficient MIS. Our core idea is to leverage limited annotated samples to train a lightweight mapping network that captures medical knowledge and transforms generic image features into target features, thereby providing additional discriminative target representations for each frame and eliminating the need for manual prompts. Crucially, the mapping network supports online parameter update during inference, enhancing the model's generalization across test sequences. Technically, we introduce two key components: (1) an online few-shot learner that trains the mapping network to generate target features using limited data, and (2) an adaptive fusion module that dynamically integrates the target features with the memory-attention features generated by frozen SAM2, leading to accurate and robust target representation. Extensive experiments on three diverse MIS datasets demonstrate that OFL-SAM2 achieves state-of-the-art performance with limited training data.
Customized SAM 2 for Referring Remote Sensing Image Segmentation
Mar 10, 2025Referring Remote Sensing Image Segmentation (RRSIS) aims to segment target objects in remote sensing (RS) images based on textual descriptions. Although Segment Anything Model 2 (SAM 2) has shown remarkable performance in various segmentation tasks, its application to RRSIS presents several challenges, including understanding the text-described RS scenes and generating effective prompts from text descriptions. To address these issues, we propose RS2-SAM 2, a novel framework that adapts SAM 2 to RRSIS by aligning the adapted RS features and textual features, providing pseudo-mask-based dense prompts, and enforcing boundary constraints. Specifically, we first employ a union encoder to jointly encode the visual and textual inputs, generating aligned visual and text embeddings as well as multimodal class tokens. Then, we design a bidirectional hierarchical fusion module to adapt SAM 2 to RS scenes and align adapted visual features with the visually enhanced text embeddings, improving the model's interpretation of text-described RS scenes. Additionally, a mask prompt generator is introduced to take the visual embeddings and class tokens as input and produce a pseudo-mask as the dense prompt of SAM 2. To further refine segmentation, we introduce a text-guided boundary loss to optimize segmentation boundaries by computing text-weighted gradient differences. Experimental results on several RRSIS benchmarks demonstrate that RS2-SAM 2 achieves state-of-the-art performance.
MPG-SAM 2: Adapting SAM 2 with Mask Priors and Global Context for Referring Video Object Segmentation
Jan 23, 2025



Referring video object segmentation (RVOS) aims to segment objects in a video according to textual descriptions, which requires the integration of multimodal information and temporal dynamics perception. The Segment Anything Model 2 (SAM 2) has shown great effectiveness across various video segmentation tasks. However, its application to offline RVOS is challenged by the translation of the text into effective prompts and a lack of global context awareness. In this paper, we propose a novel RVOS framework, termed MPG-SAM 2, to address these challenges. Specifically, MPG-SAM 2 employs a unified multimodal encoder to jointly encode video and textual features, generating semantically aligned video and text embeddings, along with multimodal class tokens. A mask prior generator utilizes the video embeddings and class tokens to create pseudo masks of target objects and global context. These masks are fed into the prompt encoder as dense prompts along with multimodal class tokens as sparse prompts to generate accurate prompts for SAM 2. To provide the online SAM 2 with a global view, we introduce a hierarchical global-historical aggregator, which allows SAM 2 to aggregate global and historical information of target objects at both pixel and object levels, enhancing the target representation and temporal consistency. Extensive experiments on several RVOS benchmarks demonstrate the superiority of MPG-SAM 2 and the effectiveness of our proposed modules.
Referring Video Object Segmentation with Inter-Frame Interaction and Cross-Modal Correlation
Jul 02, 2023



Referring video object segmentation (RVOS) aims to segment the target object in a video sequence described by a language expression. Typical query-based methods process the video sequence in a frame-independent manner to reduce the high computational cost, which however affects the performance due to the lack of inter-frame interaction for temporal coherence modeling and spatio-temporal representation learning of the referred object. Besides, they directly adopt the raw and high-level sentence feature as the language queries to decode the visual features, where the weak correlation between visual and linguistic features also increases the difficulty of decoding the target information and limits the performance of the model. In this paper, we proposes a novel RVOS framework, dubbed IFIRVOS, to address these issues. Specifically, we design a plug-and-play inter-frame interaction module in the Transformer decoder to efficiently learn the spatio-temporal features of the referred object, so as to decode the object information in the video sequence more precisely and generate more accurate segmentation results. Moreover, we devise the vision-language interaction module before the multimodal Transformer to enhance the correlation between the visual and linguistic features, thus facilitating the process of decoding object information from visual features by language queries in Transformer decoder and improving the segmentation performance. Extensive experimental results on three benchmarks validate the superiority of our IFIRVOS over state-of-the-art methods and the effectiveness of our proposed modules.
Learning to Learn Better for Video Object Segmentation
Dec 05, 2022Recently, the joint learning framework (JOINT) integrates matching based transductive reasoning and online inductive learning to achieve accurate and robust semi-supervised video object segmentation (SVOS). However, using the mask embedding as the label to guide the generation of target features in the two branches may result in inadequate target representation and degrade the performance. Besides, how to reasonably fuse the target features in the two different branches rather than simply adding them together to avoid the adverse effect of one dominant branch has not been investigated. In this paper, we propose a novel framework that emphasizes Learning to Learn Better (LLB) target features for SVOS, termed LLB, where we design the discriminative label generation module (DLGM) and the adaptive fusion module to address these issues. Technically, the DLGM takes the background-filtered frame instead of the target mask as input and adopts a lightweight encoder to generate the target features, which serves as the label of the online few-shot learner and the value of the decoder in the transformer to guide the two branches to learn more discriminative target representation. The adaptive fusion module maintains a learnable gate for each branch, which reweighs the element-wise feature representation and allows an adaptive amount of target information in each branch flowing to the fused target feature, thus preventing one branch from being dominant and making the target feature more robust to distractor. Extensive experiments on public benchmarks show that our proposed LLB method achieves state-of-the-art performance.
Siamese Network with Interactive Transformer for Video Object Segmentation
Dec 28, 2021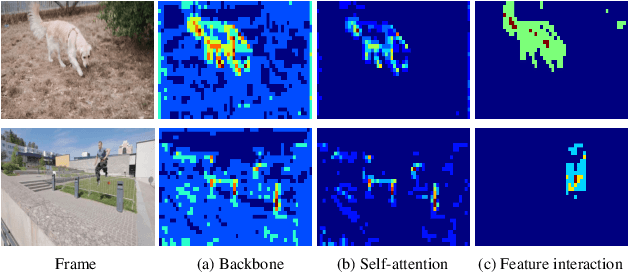
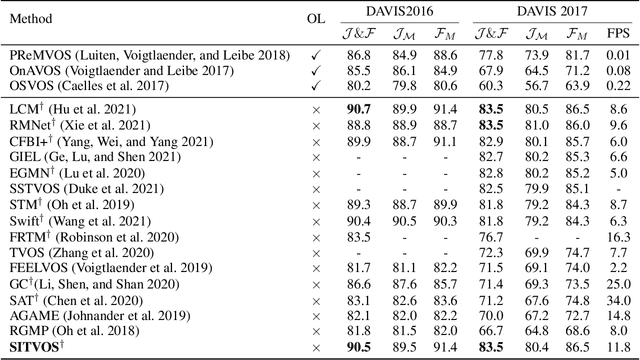


Semi-supervised video object segmentation (VOS) refers to segmenting the target object in remaining frames given its annotation in the first frame, which has been actively studied in recent years. The key challenge lies in finding effective ways to exploit the spatio-temporal context of past frames to help learn discriminative target representation of current frame. In this paper, we propose a novel Siamese network with a specifically designed interactive transformer, called SITVOS, to enable effective context propagation from historical to current frames. Technically, we use the transformer encoder and decoder to handle the past frames and current frame separately, i.e., the encoder encodes robust spatio-temporal context of target object from the past frames, while the decoder takes the feature embedding of current frame as the query to retrieve the target from the encoder output. To further enhance the target representation, a feature interaction module (FIM) is devised to promote the information flow between the encoder and decoder. Moreover, we employ the Siamese architecture to extract backbone features of both past and current frames, which enables feature reuse and is more efficient than existing methods. Experimental results on three challenging benchmarks validate the superiority of SITVOS over state-of-the-art methods.
Stagewise Unsupervised Domain Adaptation with Adversarial Self-Training for Road Segmentation of Remote Sensing Images
Aug 28, 2021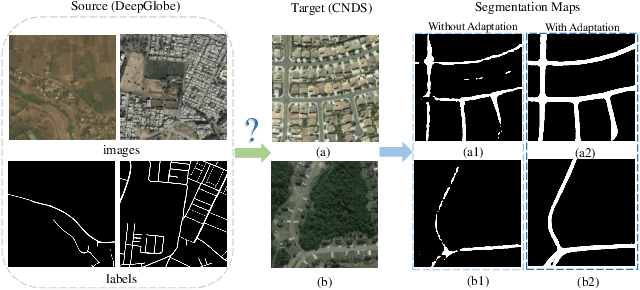


Road segmentation from remote sensing images is a challenging task with wide ranges of application potentials. Deep neural networks have advanced this field by leveraging the power of large-scale labeled data, which, however, are extremely expensive and time-consuming to acquire. One solution is to use cheap available data to train a model and deploy it to directly process the data from a specific application domain. Nevertheless, the well-known domain shift (DS) issue prevents the trained model from generalizing well on the target domain. In this paper, we propose a novel stagewise domain adaptation model called RoadDA to address the DS issue in this field. In the first stage, RoadDA adapts the target domain features to align with the source ones via generative adversarial networks (GAN) based inter-domain adaptation. Specifically, a feature pyramid fusion module is devised to avoid information loss of long and thin roads and learn discriminative and robust features. Besides, to address the intra-domain discrepancy in the target domain, in the second stage, we propose an adversarial self-training method. We generate the pseudo labels of target domain using the trained generator and divide it to labeled easy split and unlabeled hard split based on the road confidence scores. The features of hard split are adapted to align with the easy ones using adversarial learning and the intra-domain adaptation process is repeated to progressively improve the segmentation performance. Experiment results on two benchmarks demonstrate that RoadDA can efficiently reduce the domain gap and outperforms state-of-the-art methods.
Transportation Density Reduction Caused by City Lockdowns Across the World during the COVID-19 Epidemic: From the View of High-resolution Remote Sensing Imagery
Mar 02, 2021
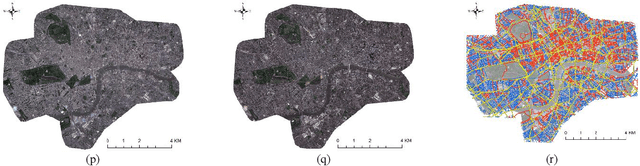
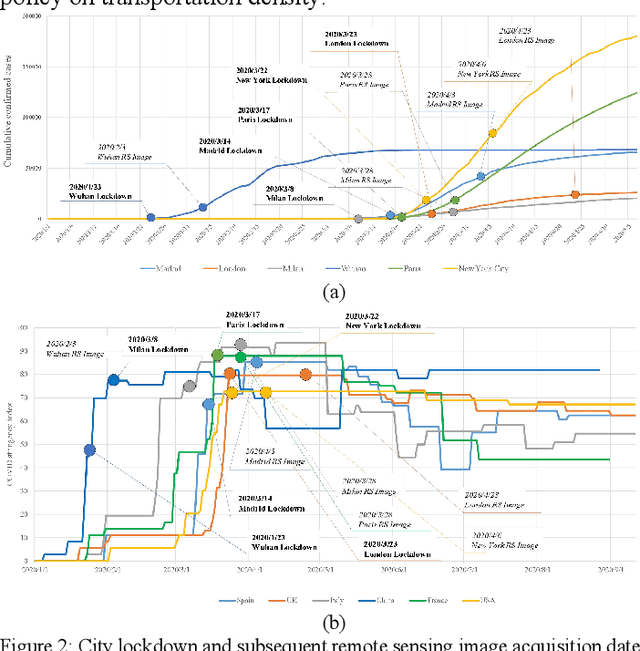
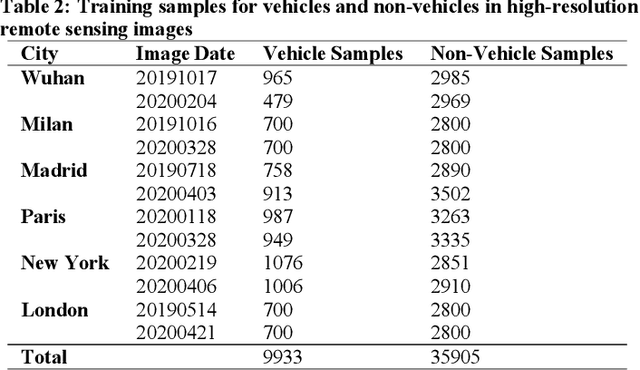
As the COVID-19 epidemic began to worsen in the first months of 2020, stringent lockdown policies were implemented in numerous cities throughout the world to control human transmission and mitigate its spread. Although transportation density reduction inside the city was felt subjectively, there has thus far been no objective and quantitative study of its variation to reflect the intracity population flows and their corresponding relationship with lockdown policy stringency from the view of remote sensing images with the high resolution under 1m. Accordingly, we here provide a quantitative investigation of the transportation density reduction before and after lockdown was implemented in six epicenter cities (Wuhan, Milan, Madrid, Paris, New York, and London) around the world during the COVID-19 epidemic, which is accomplished by extracting vehicles from the multi-temporal high-resolution remote sensing images. A novel vehicle detection model combining unsupervised vehicle candidate extraction and deep learning identification was specifically proposed for the images with the resolution of 0.5m. Our results indicate that transportation densities were reduced by an average of approximately 50% (and as much as 75.96%) in these six cities following lockdown. The influences on transportation density reduction rates are also highly correlated with policy stringency, with an R^2 value exceeding 0.83. Even within a specific city, the transportation density changes differed and tended to be distributed in accordance with the city's land-use patterns. Considering that public transportation was mostly reduced or even forbidden, our results indicate that city lockdown policies are effective at limiting human transmission within cities.
Defect Detection from UAV Images based on Region-Based CNNs
Nov 23, 2018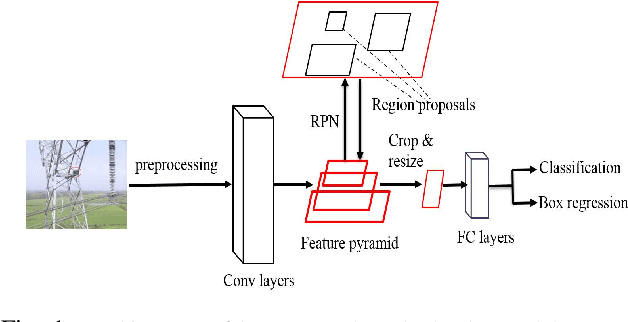



With the wide applications of Unmanned Aerial Vehicle (UAV) in engineering such as the inspection of the electrical equipment from distance, the demands of efficient object detection algorithms for abundant images acquired by UAV have also been significantly increased in recent years. In this work, we study the performance of the region-based CNN for the electrical equipment defect detection by using the UAV images. In order to train the detection model, we collect a UAV images dataset composes of four classes of electrical equipment defects with thousands of annotated labels. Then, based on the region-based faster R-CNN model, we present a multi-class defects detection model for electrical equipment which is more efficient and accurate than traditional single class detection methods. Technically, we have replaced the RoI pooling layer with a similar operation in Tensorflow and promoted the mini-batch to 128 per image in the training procedure. These improvements have slightly increased the speed of detection without any accuracy loss. Therefore, the modified region-based CNN could simultaneously detect multi-class of defects of the electrical devices in nearly real time. Experimental results on the real word electrical equipment images demonstrate that the proposed method achieves better performance than the traditional object detection algorithms in defect detection.