 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChiTransformer:Towards Reliable Stereo from Cues
Paper and Code

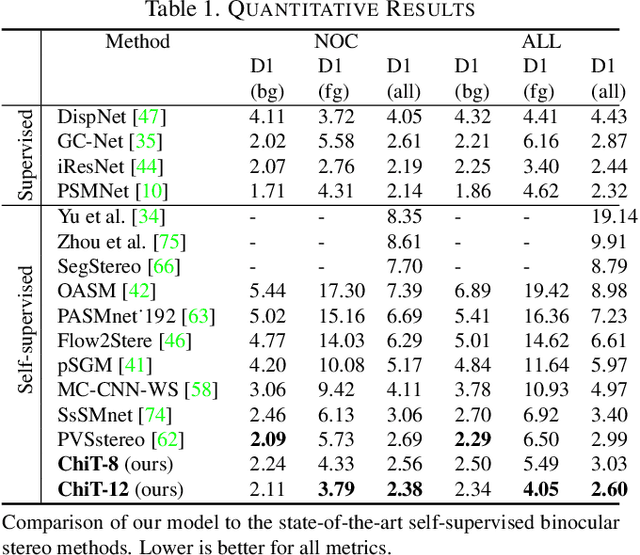
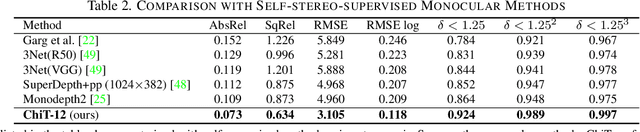

Current stereo matching techniques are challenged by restricted searching space, occluded regions and sheer size. While single image depth estimation is spared from these challenges and can achieve satisfactory results with the extracted monocular cues, the lack of stereoscopic relationship renders the monocular prediction less reliable on its own, especially in highly dynamic or cluttered environments. To address these issues in both scenarios, we present an optic-chiasm-inspired self-supervised binocular depth estimation method, wherein a vision transformer (ViT) with gated positional cross-attention (GPCA) layers is designed to enable feature-sensitive pattern retrieval between views while retaining the extensive context information aggregated through self-attentions. Monocular cues from a single view are thereafter conditionally rectified by a blending layer with the retrieved pattern pairs. This crossover design is biologically analogous to the optic-chasma structure in the human visual system and hence the name, ChiTransformer. Our experiments show that this architecture yields substantial improvements over state-of-the-art self-supervised stereo approaches by 11%, and can be used on both rectilinear and non-rectilinear (e.g., fisheye) images.