 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStability of SGD: Tightness Analysis and Improved Bounds
Feb 10, 2021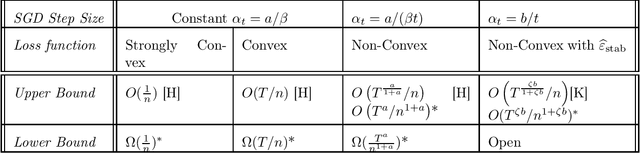
Stochastic Gradient Descent (SGD) based methods have been widely used for training large-scale machine learning models that also generalize well in practice. Several explanations have been offered for this generalization performance, a prominent one being algorithmic stability [18]. However, there are no known examples of smooth loss functions for which the analysis can be shown to be tight. Furthermore, apart from the properties of the loss function, data distribution has also been shown to be an important factor in generalization performance. This raises the question: is the stability analysis of [18] tight for smooth functions, and if not, for what kind of loss functions and data distributions can the stability analysis be improved? In this paper we first settle open questions regarding tightness of bounds in the data-independent setting: we show that for general datasets, the existing analysis for convex and strongly-convex loss functions is tight, but it can be improved for non-convex loss functions. Next, we give a novel and improved data-dependent bounds: we show stability upper bounds for a large class of convex regularized loss functions, with negligible regularization parameters, and improve existing data-dependent bounds in the non-convex setting. We hope that our results will initiate further efforts to better understand the data-dependent setting under non-convex loss functions, leading to an improved understanding of the generalization abilities of deep networks.