 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Dive into Semi-Supervised ELBO for Improving Classification Performance
Aug 29, 2021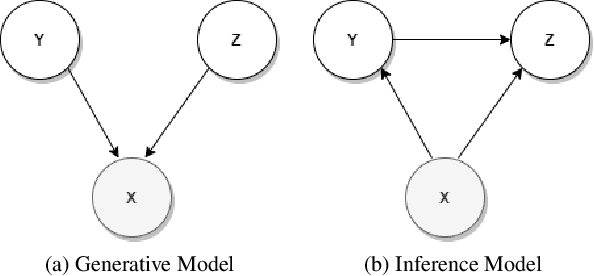
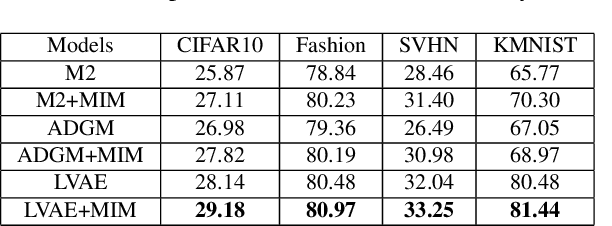
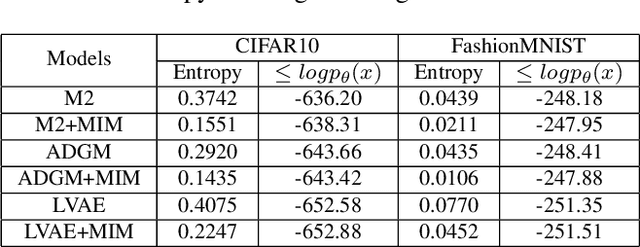
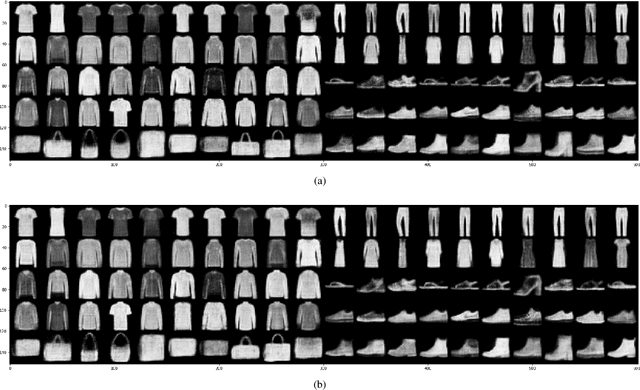
Decomposition of the evidence lower bound (ELBO) objective of VAE used for density estimation revealed the deficiency of VAE for representation learning and suggested ways to improve the model. In this paper, we investigate whether we can get similar insights by decomposing the ELBO for semi-supervised classification using VAE model. Specifically, we show that mutual information between input and class labels decreases during maximization of ELBO objective. We propose a method to address this issue. We also enforce cluster assumption to aid in classification. Experiments on a diverse datasets verify that our method can be used to improve the classification performance of existing VAE based semi-supervised models. Experiments also show that, this can be achieved without sacrificing the generative power of the model.
A Novel Disaster Image Dataset and Characteristics Analysis using Attention Model
Jul 02, 2021
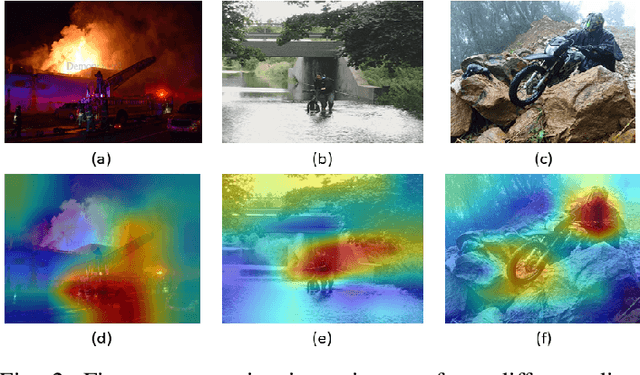

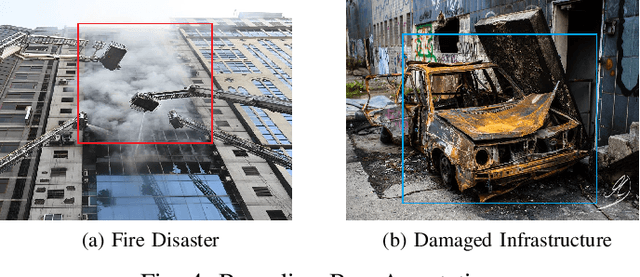
The advancement of deep learning technology has enabled us to develop systems that outperform any other classification technique. However, success of any empirical system depends on the quality and diversity of the data available to train the proposed system. In this research, we have carefully accumulated a relatively challenging dataset that contains images collected from various sources for three different disasters: fire, water and land. Besides this, we have also collected images for various damaged infrastructure due to natural or man made calamities and damaged human due to war or accidents. We have also accumulated image data for a class named non-damage that contains images with no such disaster or sign of damage in them. There are 13,720 manually annotated images in this dataset, each image is annotated by three individuals. We are also providing discriminating image class information annotated manually with bounding box for a set of 200 test images. Images are collected from different news portals, social media, and standard datasets made available by other researchers. A three layer attention model (TLAM) is trained and average five fold validation accuracy of 95.88% is achieved. Moreover, on the 200 unseen test images this accuracy is 96.48%. We also generate and compare attention maps for these test images to determine the characteristics of the trained attention model. Our dataset is available at https://niloy193.github.io/Disaster-Dataset
Attention Toward Neighbors: A Context Aware Framework for High Resolution Image Segmentation
Jun 24, 2021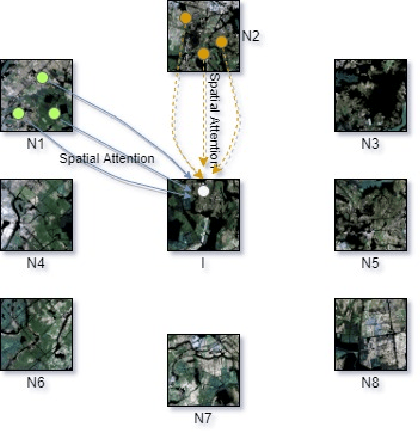
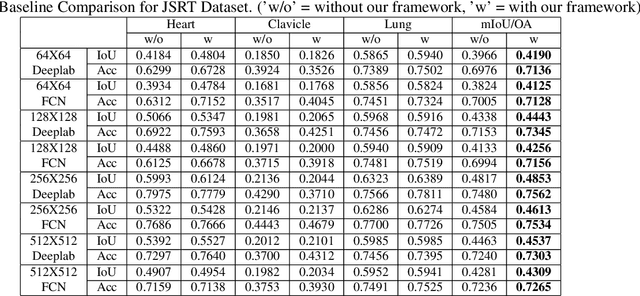
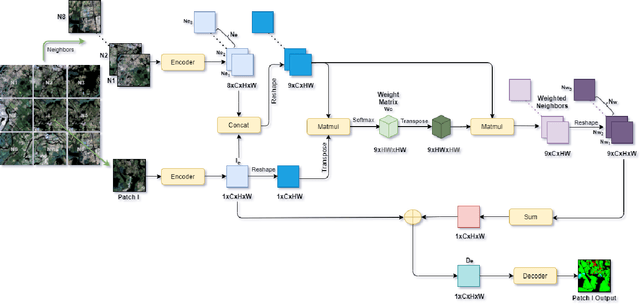
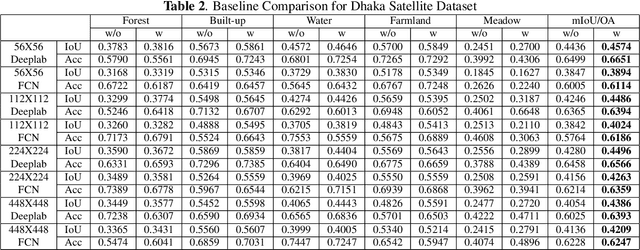
High-resolution image segmentation remains challenging and error-prone due to the enormous size of intermediate feature maps. Conventional methods avoid this problem by using patch based approaches where each patch is segmented independently. However, independent patch segmentation induces errors, particularly at the patch boundary due to the lack of contextual information in very high-resolution images where the patch size is much smaller compared to the full image. To overcome these limitations, in this paper, we propose a novel framework to segment a particular patch by incorporating contextual information from its neighboring patches. This allows the segmentation network to see the target patch with a wider field of view without the need of larger feature maps. Comparative analysis from a number of experiments shows that our proposed framework is able to segment high resolution images with significantly improved mean Intersection over Union and overall accuracy.
Rapid Feature Extraction for Optical Character Recognition
Jun 01, 2012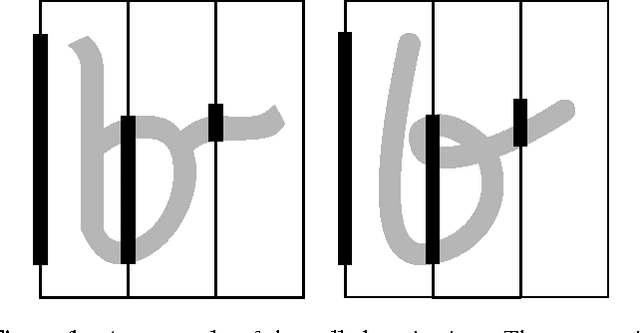
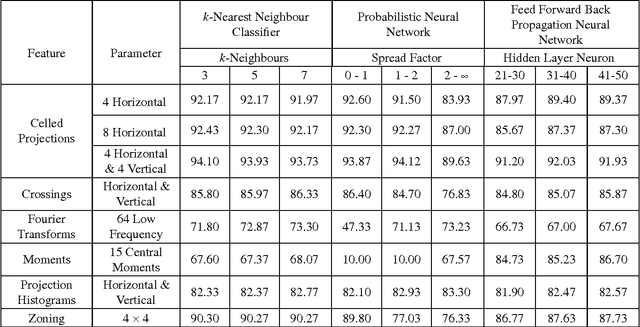
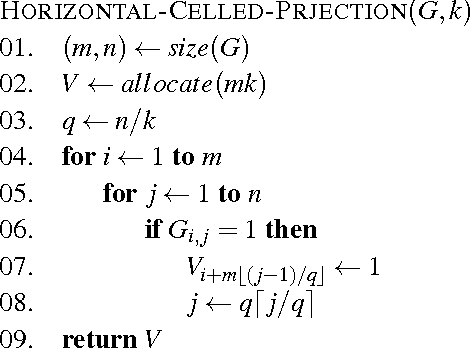
Feature extraction is one of the fundamental problems of character recognition. The performance of character recognition system is depends on proper feature extraction and correct classifier selection. In this article, a rapid feature extraction method is proposed and named as Celled Projection (CP) that compute the projection of each section formed through partitioning an image. The recognition performance of the proposed method is compared with other widely used feature extraction methods that are intensively studied for many different scripts in literature. The experiments have been conducted using Bangla handwritten numerals along with three different well known classifiers which demonstrate comparable results including 94.12% recognition accuracy using celled projection.