 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBD Open LULC Map: High-resolution land use land cover mapping & benchmarking for urban development in Dhaka, Bangladesh
May 28, 2025Land Use Land Cover (LULC) mapping using deep learning significantly enhances the reliability of LULC classification, aiding in understanding geography, socioeconomic conditions, poverty levels, and urban sprawl. However, the scarcity of annotated satellite data, especially in South/East Asian developing countries, poses a major challenge due to limited funding, diverse infrastructures, and dense populations. In this work, we introduce the BD Open LULC Map (BOLM), providing pixel-wise LULC annotations across eleven classes (e.g., Farmland, Water, Forest, Urban Structure, Rural Built-Up) for Dhaka metropolitan city and its surroundings using high-resolution Bing satellite imagery (2.22 m/pixel). BOLM spans 4,392 sq km (891 million pixels), with ground truth validated through a three-stage process involving GIS experts. We benchmark LULC segmentation using DeepLab V3+ across five major classes and compare performance on Bing and Sentinel-2A imagery. BOLM aims to support reliable deep models and domain adaptation tasks, addressing critical LULC dataset gaps in South/East Asia.
BD-SAT: High-resolution Land Use Land Cover Dataset & Benchmark Results for Developing Division: Dhaka, BD
Jun 09, 2024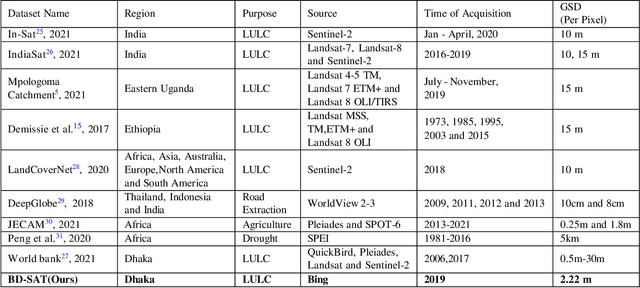

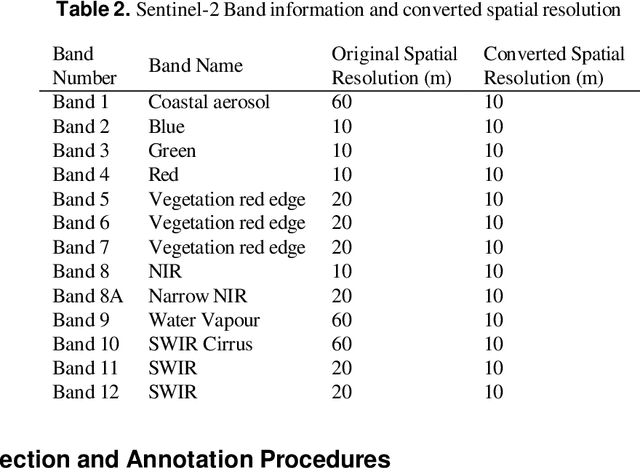

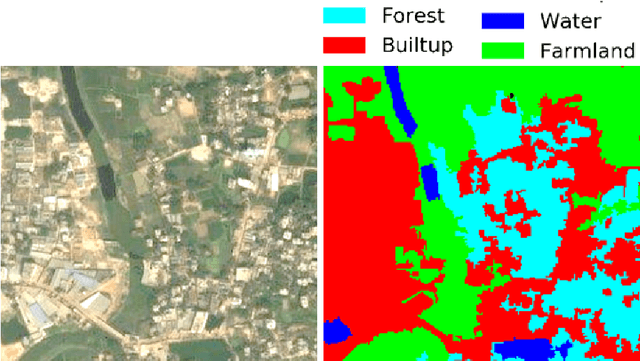
Land Use Land Cover (LULC) analysis on satellite images using deep learning-based methods is significantly helpful in understanding the geography, socio-economic conditions, poverty levels, and urban sprawl in developing countries. Recent works involve segmentation with LULC classes such as farmland, built-up areas, forests, meadows, water bodies, etc. Training deep learning methods on satellite images requires large sets of images annotated with LULC classes. However, annotated data for developing countries are scarce due to a lack of funding, absence of dedicated residential/industrial/economic zones, a large population, and diverse building materials. BD-SAT provides a high-resolution dataset that includes pixel-by-pixel LULC annotations for Dhaka metropolitan city and surrounding rural/urban areas. Using a strict and standardized procedure, the ground truth is created using Bing satellite imagery with a ground spatial distance of 2.22 meters per pixel. A three-stage, well-defined annotation process has been followed with support from GIS experts to ensure the reliability of the annotations. We performed several experiments to establish benchmark results. The results show that the annotated BD-SAT is sufficient to train large deep learning models with adequate accuracy for five major LULC classes: forest, farmland, built-up areas, water bodies, and meadows.
A Novel Disaster Image Dataset and Characteristics Analysis using Attention Model
Jul 02, 2021
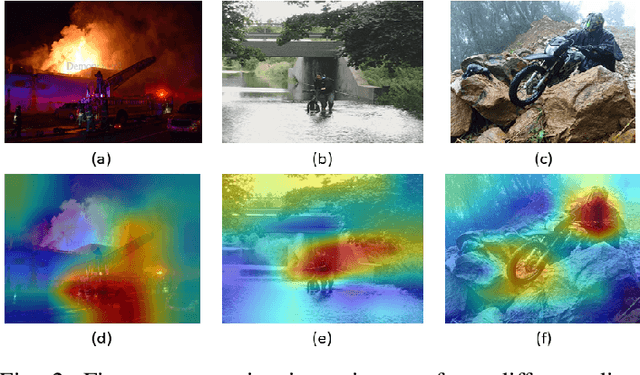

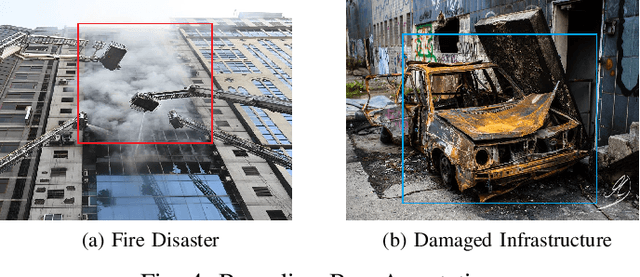
The advancement of deep learning technology has enabled us to develop systems that outperform any other classification technique. However, success of any empirical system depends on the quality and diversity of the data available to train the proposed system. In this research, we have carefully accumulated a relatively challenging dataset that contains images collected from various sources for three different disasters: fire, water and land. Besides this, we have also collected images for various damaged infrastructure due to natural or man made calamities and damaged human due to war or accidents. We have also accumulated image data for a class named non-damage that contains images with no such disaster or sign of damage in them. There are 13,720 manually annotated images in this dataset, each image is annotated by three individuals. We are also providing discriminating image class information annotated manually with bounding box for a set of 200 test images. Images are collected from different news portals, social media, and standard datasets made available by other researchers. A three layer attention model (TLAM) is trained and average five fold validation accuracy of 95.88% is achieved. Moreover, on the 200 unseen test images this accuracy is 96.48%. We also generate and compare attention maps for these test images to determine the characteristics of the trained attention model. Our dataset is available at https://niloy193.github.io/Disaster-Dataset
Deep-learning coupled with novel classification method to classify the urban environment of the developing world
Nov 25, 2020
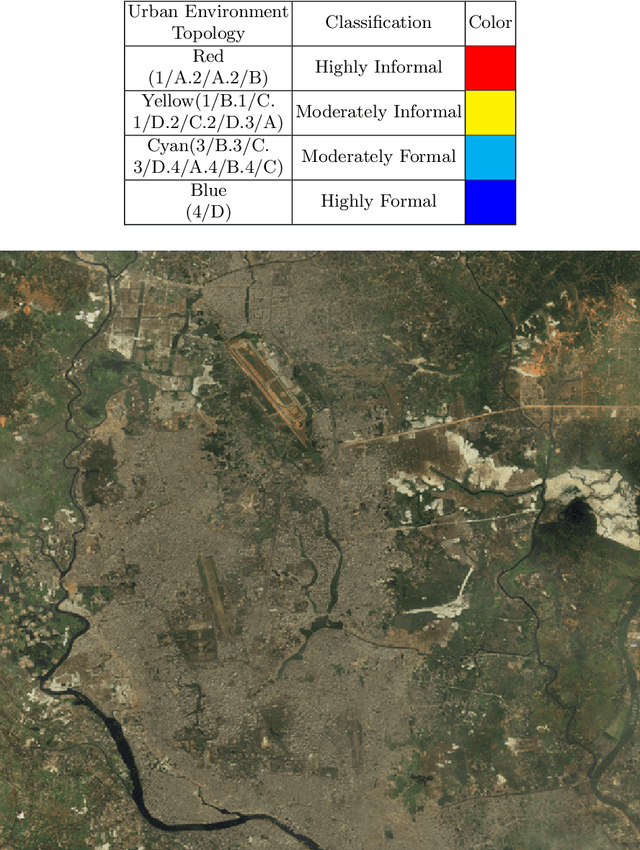
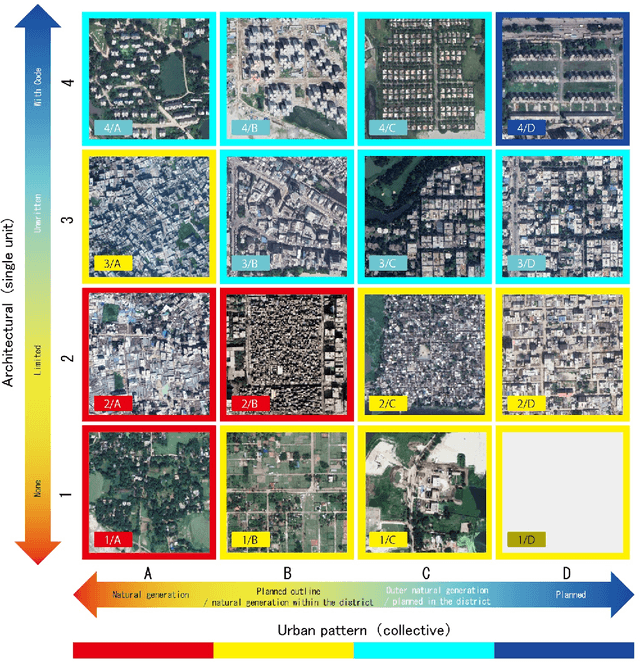
Rapid globalization and the interdependence of humanity that engender tremendous in-flow of human migration towards the urban spaces. With advent of high definition satellite images, high resolution data, computational methods such as deep neural network, capable hardware; urban planning is seeing a paradigm shift. Legacy data on urban environments are now being complemented with high-volume, high-frequency data. In this paper we propose a novel classification method that is readily usable for machine analysis and show applicability of the methodology on a developing world setting. The state-of-the-art is mostly dominated by classification of building structures, building types etc. and largely represents the developed world which are insufficient for developing countries such as Bangladesh where the surrounding is crucial for the classification. Moreover, the traditional methods propose small-scale classifications, which give limited information with poor scalability and are slow to compute. We categorize the urban area in terms of informal and formal spaces taking the surroundings into account. 50 km x 50 km Google Earth image of Dhaka, Bangladesh was visually annotated and categorized by an expert. The classification is based broadly on two dimensions: urbanization and the architectural form of urban environment. Consequently, the urban space is divided into four classes: 1) highly informal; 2) moderately informal; 3) moderately formal; and 4) highly formal areas. In total 16 sub-classes were identified. For semantic segmentation, Google's DeeplabV3+ model was used which increases the field of view of the filters to incorporate larger context. Image encompassing 70% of the urban space was used for training and the remaining 30% was used for testing and validation. The model is able to segment with 75% accuracy and 60% Mean IoU.
LULC Segmentation of RGB Satellite Image Using FCN-8
Aug 24, 2020


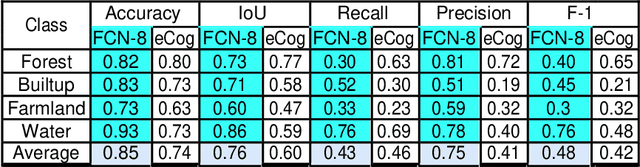
This work presents use of Fully Convolutional Network (FCN-8) for semantic segmentation of high-resolution RGB earth surface satel-lite images into land use land cover (LULC) categories. Specically, we propose a non-overlapping grid-based approach to train a Fully Convo-lutional Network (FCN-8) with vgg-16 weights to segment satellite im-ages into four (forest, built-up, farmland and water) classes. The FCN-8 semantically projects the discriminating features in lower resolution learned by the encoder onto the pixel space in higher resolution to get a dense classi cation. We experimented the proposed system with Gaofen-2 image dataset, that contains 150 images of over 60 di erent cities in china. For comparison, we used available ground-truth along with images segmented using a widely used commeriial GIS software called eCogni-tion. With the proposed non-overlapping grid-based approach, FCN-8 obtains signi cantly improved performance, than the eCognition soft-ware. Our model achieves average accuracy of 91.0% and average Inter-section over Union (IoU) of 0.84. In contrast, eCognitions average accu-racy is 74.0% and IoU is 0.60. This paper also reports a detail analysis of errors occurred at the LULC boundary.
Image Pre-processing on NumtaDB for Bengali Handwritten Digit Recognition
Aug 18, 2020


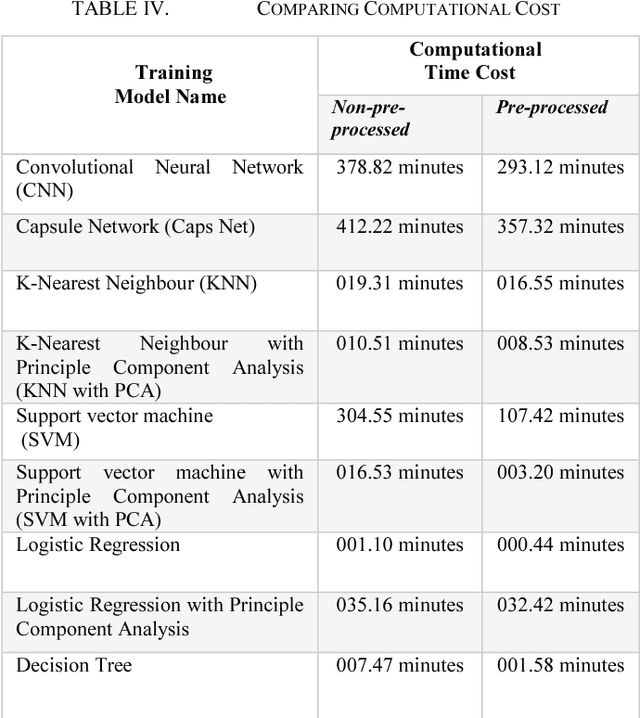
NumtaDB is by far the largest data-set collection for handwritten digits in Bengali. This is a diverse dataset containing more than 85000 images. But this diversity also makes this dataset very difficult to work with. The goal of this paper is to find the benchmark for pre-processed images which gives good accuracy on any machine learning models. The reason being, there are no available pre-processed data for Bengali digit recognition to work with like the English digits for MNIST.
* 5 pages, 8 figures and 4 tables