Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Pre-processing on NumtaDB for Bengali Handwritten Digit Recognition
Paper and Code
Aug 18, 2020


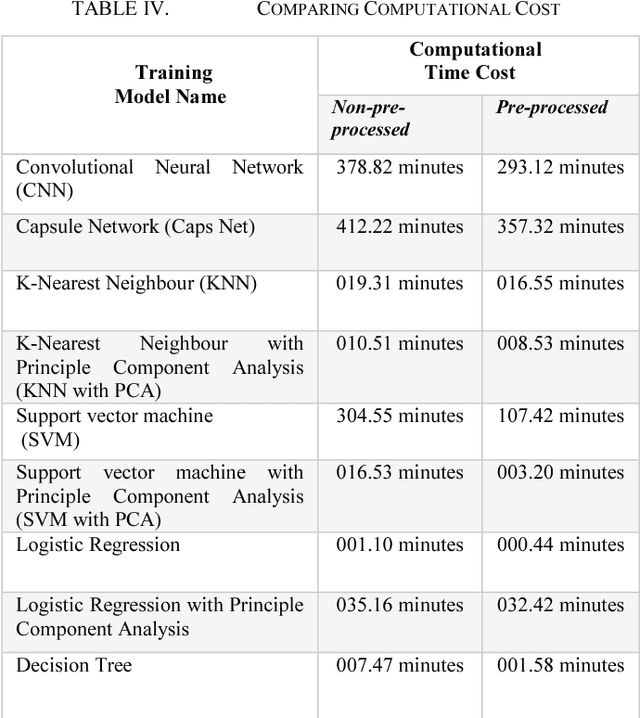
NumtaDB is by far the largest data-set collection for handwritten digits in Bengali. This is a diverse dataset containing more than 85000 images. But this diversity also makes this dataset very difficult to work with. The goal of this paper is to find the benchmark for pre-processed images which gives good accuracy on any machine learning models. The reason being, there are no available pre-processed data for Bengali digit recognition to work with like the English digits for MNIST.
* 2018 International Conference on Bangla Speech and Language
Processing (ICBSLP), Sylhet, 2018, pp. 1-6 * 5 pages, 8 figures and 4 tables
View paper on