 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeamPose: Repurposing Seams as Capacitive Sensors in a Shirt for Upper-Body Pose Tracking
Jun 17, 2024



Seams are areas of overlapping fabric formed by stitching two or more pieces of fabric together in the cut-and-sew apparel manufacturing process. In SeamPose, we repurposed seams as capacitive sensors in a shirt for continuous upper-body pose estimation. Compared to previous all-textile motion-capturing garments that place the electrodes on the surface of clothing, our solution leverages existing seams inside of a shirt by machine-sewing insulated conductive threads over the seams. The unique invisibilities and placements of the seams afford the sensing shirt to look and wear the same as a conventional shirt while providing exciting pose-tracking capabilities. To validate this approach, we implemented a proof-of-concept untethered shirt. With eight capacitive sensing seams, our customized deep-learning pipeline accurately estimates the upper-body 3D joint positions relative to the pelvis. With a 12-participant user study, we demonstrated promising cross-user and cross-session tracking performance. SeamPose represents a step towards unobtrusive integration of smart clothing for everyday pose estimation.
STLGRU: Spatio-Temporal Lightweight Graph GRU for Traffic Flow Prediction
Dec 08, 2022Reliable forecasting of traffic flow requires efficient modeling of traffic data. Different correlations and influences arise in a dynamic traffic network, making modeling a complicated task. Existing literature has proposed many different methods to capture the complex underlying spatial-temporal relations of traffic networks. However, methods still struggle to capture different local and global dependencies of long-range nature. Also, as more and more sophisticated methods are being proposed, models are increasingly becoming memory-heavy and, thus, unsuitable for low-powered devices. In this paper, we focus on solving these problems by proposing a novel deep learning framework - STLGRU. Specifically, our proposed STLGRU can effectively capture both local and global spatial-temporal relations of a traffic network using memory-augmented attention and gating mechanism. Instead of employing separate temporal and spatial components, we show that our memory module and gated unit can learn the spatial-temporal dependencies successfully, allowing for reduced memory usage with fewer parameters. We extensively experiment on several real-world traffic prediction datasets to show that our model performs better than existing methods while the memory footprint remains lower. Code is available at \url{https://github.com/Kishor-Bhaumik/STLGRU}.
Hierarchical Self Attention Based Autoencoder for Open-Set Human Activity Recognition
Mar 07, 2021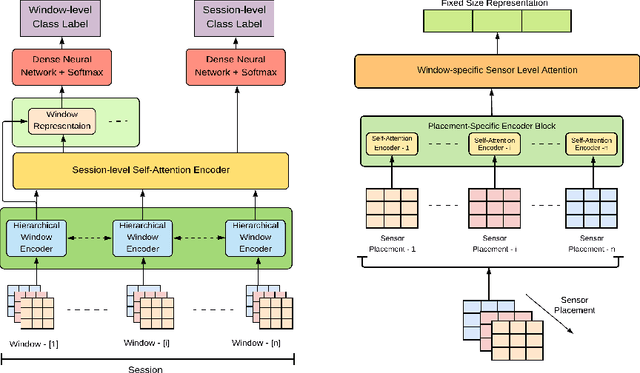
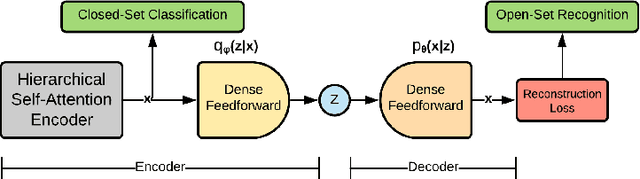
Wearable sensor based human activity recognition is a challenging problem due to difficulty in modeling spatial and temporal dependencies of sensor signals. Recognition models in closed-set assumption are forced to yield members of known activity classes as prediction. However, activity recognition models can encounter an unseen activity due to body-worn sensor malfunction or disability of the subject performing the activities. This problem can be addressed through modeling solution according to the assumption of open-set recognition. Hence, the proposed self attention based approach combines data hierarchically from different sensor placements across time to classify closed-set activities and it obtains notable performance improvement over state-of-the-art models on five publicly available datasets. The decoder in this autoencoder architecture incorporates self-attention based feature representations from encoder to detect unseen activity classes in open-set recognition setting. Furthermore, attention maps generated by the hierarchical model demonstrate explainable selection of features in activity recognition. We conduct extensive leave one subject out validation experiments that indicate significantly improved robustness to noise and subject specific variability in body-worn sensor signals. The source code is available at: github.com/saif-mahmud/hierarchical-attention-HAR
Human Activity Recognition from Wearable Sensor Data Using Self-Attention
Mar 17, 2020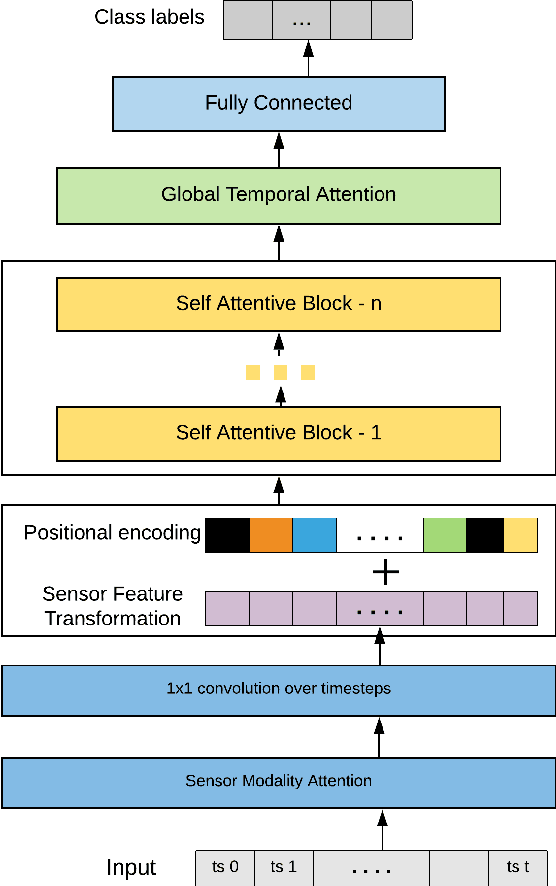
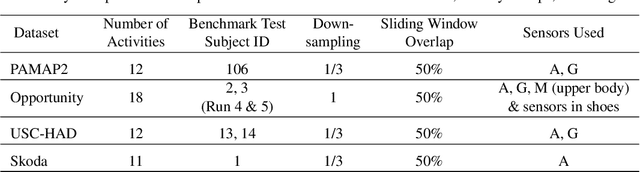
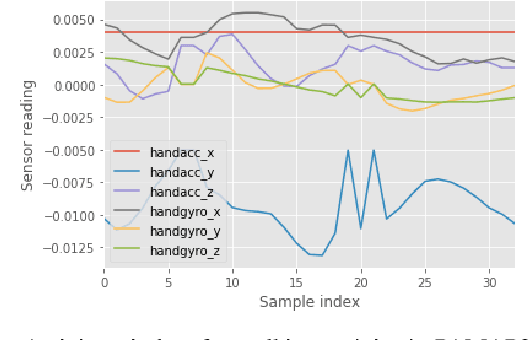
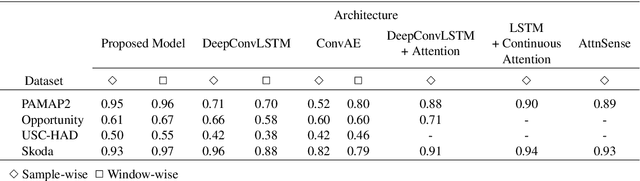
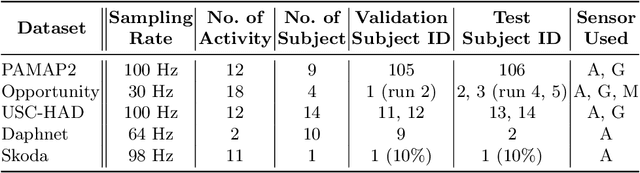
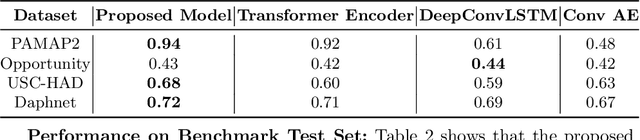
Human Activity Recognition from body-worn sensor data poses an inherent challenge in capturing spatial and temporal dependencies of time-series signals. In this regard, the existing recurrent or convolutional or their hybrid models for activity recognition struggle to capture spatio-temporal context from the feature space of sensor reading sequence. To address this complex problem, we propose a self-attention based neural network model that foregoes recurrent architectures and utilizes different types of attention mechanisms to generate higher dimensional feature representation used for classification. We performed extensive experiments on four popular publicly available HAR datasets: PAMAP2, Opportunity, Skoda and USC-HAD. Our model achieve significant performance improvement over recent state-of-the-art models in both benchmark test subjects and Leave-one-subject-out evaluation. We also observe that the sensor attention maps produced by our model is able capture the importance of the modality and placement of the sensors in predicting the different activity classes.