 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Offline Imitation Learning from Diverse Auxiliary Data
Paper and Code
Oct 04, 2024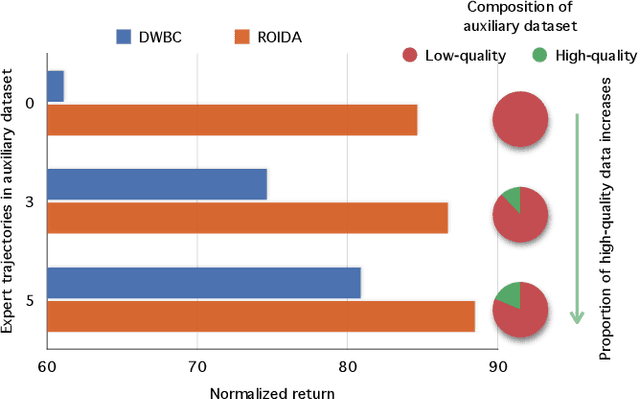
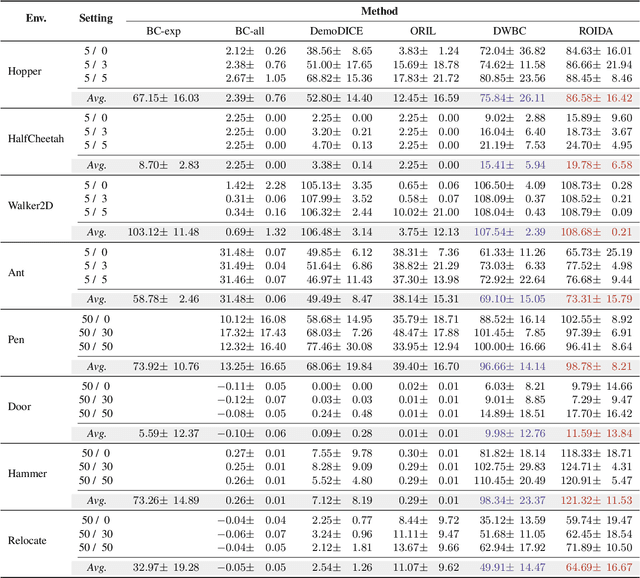
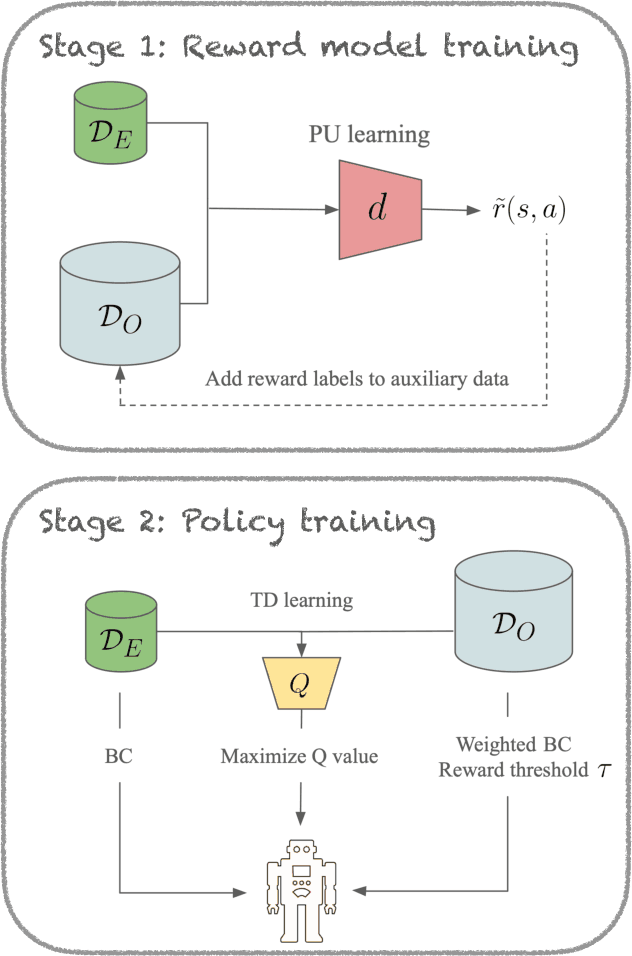
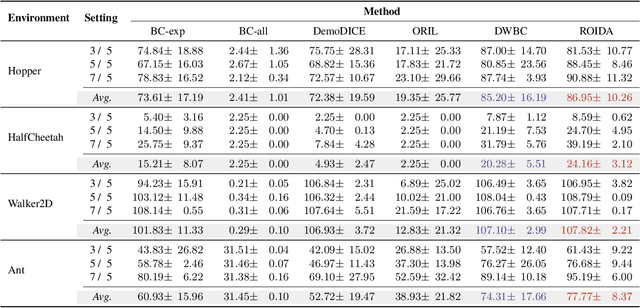
Offline imitation learning enables learning a policy solely from a set of expert demonstrations, without any environment interaction. To alleviate the issue of distribution shift arising due to the small amount of expert data, recent works incorporate large numbers of auxiliary demonstrations alongside the expert data. However, the performance of these approaches rely on assumptions about the quality and composition of the auxiliary data. However, they are rarely successful when those assumptions do not hold. To address this limitation, we propose Robust Offline Imitation from Diverse Auxiliary Data (ROIDA). ROIDA first identifies high-quality transitions from the entire auxiliary dataset using a learned reward function. These high-reward samples are combined with the expert demonstrations for weighted behavioral cloning. For lower-quality samples, ROIDA applies temporal difference learning to steer the policy towards high-reward states, improving long-term returns. This two-pronged approach enables our framework to effectively leverage both high and low-quality data without any assumptions. Extensive experiments validate that ROIDA achieves robust and consistent performance across multiple auxiliary datasets with diverse ratios of expert and non-expert demonstrations. ROIDA effectively leverages unlabeled auxiliary data, outperforming prior methods reliant on specific data assumptions.