 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFool the Hydra: Adversarial Attacks against Multi-view Object Detection Systems
Nov 30, 2023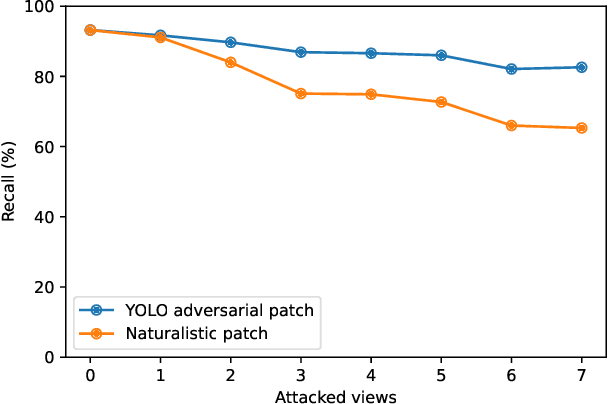
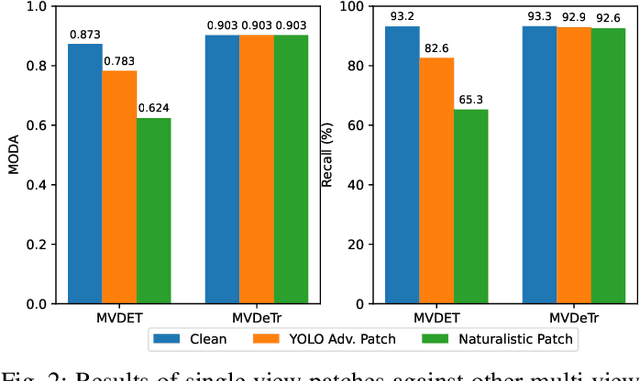
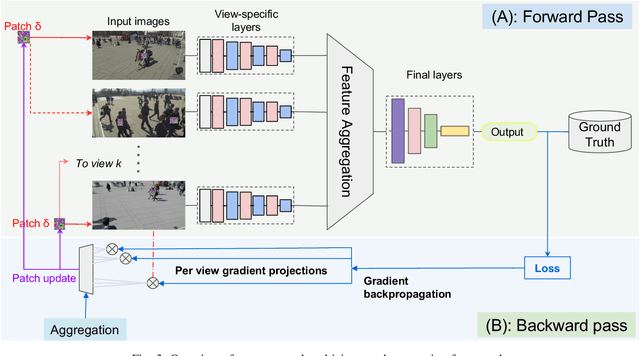
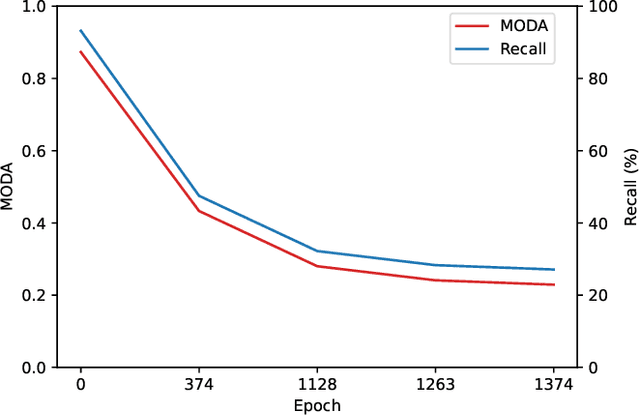
Adversarial patches exemplify the tangible manifestation of the threat posed by adversarial attacks on Machine Learning (ML) models in real-world scenarios. Robustness against these attacks is of the utmost importance when designing computer vision applications, especially for safety-critical domains such as CCTV systems. In most practical situations, monitoring open spaces requires multi-view systems to overcome acquisition challenges such as occlusion handling. Multiview object systems are able to combine data from multiple views, and reach reliable detection results even in difficult environments. Despite its importance in real-world vision applications, the vulnerability of multiview systems to adversarial patches is not sufficiently investigated. In this paper, we raise the following question: Does the increased performance and information sharing across views offer as a by-product robustness to adversarial patches? We first conduct a preliminary analysis showing promising robustness against off-the-shelf adversarial patches, even in an extreme setting where we consider patches applied to all views by all persons in Wildtrack benchmark. However, we challenged this observation by proposing two new attacks: (i) In the first attack, targeting a multiview CNN, we maximize the global loss by proposing gradient projection to the different views and aggregating the obtained local gradients. (ii) In the second attack, we focus on a Transformer-based multiview framework. In addition to the focal loss, we also maximize the transformer-specific loss by dissipating its attention blocks. Our results show a large degradation in the detection performance of victim multiview systems with our first patch attack reaching an attack success rate of 73% , while our second proposed attack reduced the performance of its target detector by 62%
Attention Deficit is Ordered! Fooling Deformable Vision Transformers with Collaborative Adversarial Patches
Nov 21, 2023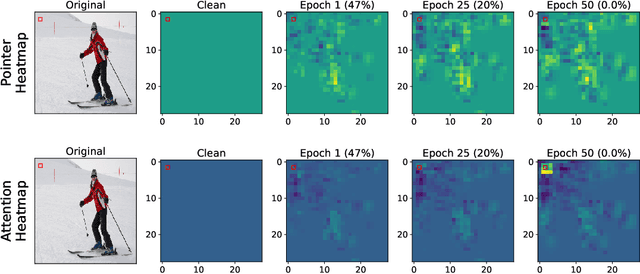



The latest generation of transformer-based vision models have proven to be superior to Convolutional Neural Network (CNN)-based models across several vision tasks, largely attributed to their remarkable prowess in relation modeling. Deformable vision transformers significantly reduce the quadratic complexity of modeling attention by using sparse attention structures, enabling them to be used in larger scale applications such as multi-view vision systems. Recent work demonstrated adversarial attacks against transformers; we show that these attacks do not transfer to deformable transformers due to their sparse attention structure. Specifically, attention in deformable transformers is modeled using pointers to the most relevant other tokens. In this work, we contribute for the first time adversarial attacks that manipulate the attention of deformable transformers, distracting them to focus on irrelevant parts of the image. We also develop new collaborative attacks where a source patch manipulates attention to point to a target patch that adversarially attacks the system. In our experiments, we find that only 1% patched area of the input field can lead to 0% AP. We also show that the attacks provide substantial versatility to support different attacker scenarios because of their ability to redirect attention under the attacker control.
Jedi: Entropy-based Localization and Removal of Adversarial Patches
Apr 20, 2023

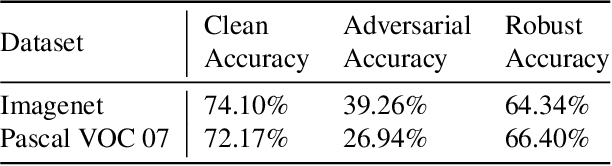

Real-world adversarial physical patches were shown to be successful in compromising state-of-the-art models in a variety of computer vision applications. Existing defenses that are based on either input gradient or features analysis have been compromised by recent GAN-based attacks that generate naturalistic patches. In this paper, we propose Jedi, a new defense against adversarial patches that is resilient to realistic patch attacks. Jedi tackles the patch localization problem from an information theory perspective; leverages two new ideas: (1) it improves the identification of potential patch regions using entropy analysis: we show that the entropy of adversarial patches is high, even in naturalistic patches; and (2) it improves the localization of adversarial patches, using an autoencoder that is able to complete patch regions from high entropy kernels. Jedi achieves high-precision adversarial patch localization, which we show is critical to successfully repair the images. Since Jedi relies on an input entropy analysis, it is model-agnostic, and can be applied on pre-trained off-the-shelf models without changes to the training or inference of the protected models. Jedi detects on average 90% of adversarial patches across different benchmarks and recovers up to 94% of successful patch attacks (Compared to 75% and 65% for LGS and Jujutsu, respectively).
Adversarial Attacks in a Multi-view Setting: An Empirical Study of the Adversarial Patches Inter-view Transferability
Oct 10, 2021

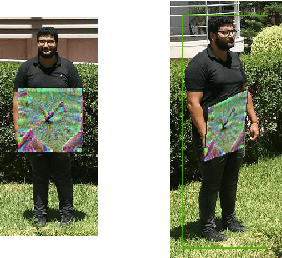

While machine learning applications are getting mainstream owing to a demonstrated efficiency in solving complex problems, they suffer from inherent vulnerability to adversarial attacks. Adversarial attacks consist of additive noise to an input which can fool a detector. Recently, successful real-world printable adversarial patches were proven efficient against state-of-the-art neural networks. In the transition from digital noise based attacks to real-world physical attacks, the myriad of factors affecting object detection will also affect adversarial patches. Among these factors, view angle is one of the most influential, yet under-explored. In this paper, we study the effect of view angle on the effectiveness of an adversarial patch. To this aim, we propose the first approach that considers a multi-view context by combining existing adversarial patches with a perspective geometric transformation in order to simulate the effect of view angle changes. Our approach has been evaluated on two datasets: the first dataset which contains most real world constraints of a multi-view context, and the second dataset which empirically isolates the effect of view angle. The experiments show that view angle significantly affects the performance of adversarial patches, where in some cases the patch loses most of its effectiveness. We believe that these results motivate taking into account the effect of view angles in future adversarial attacks, and open up new opportunities for adversarial defenses.