 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIzhikevich-Inspired Temporal Dynamics for Enhancing Privacy, Efficiency, and Transferability in Spiking Neural Networks
May 07, 2025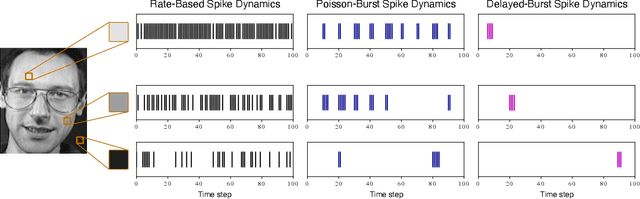
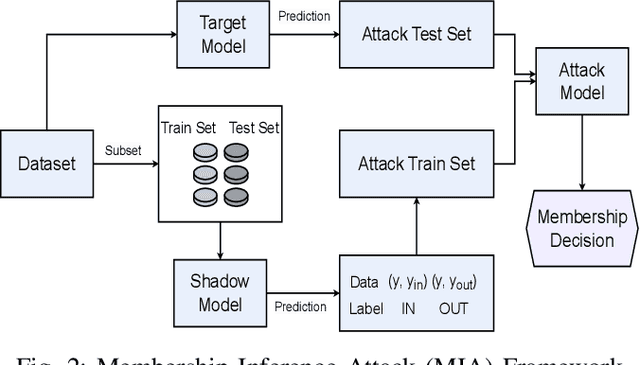
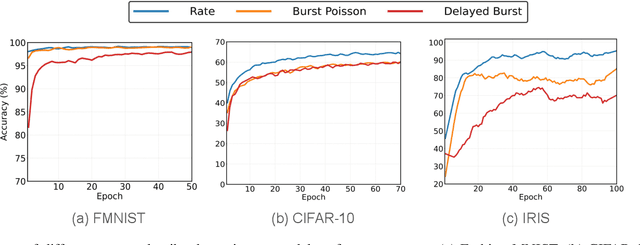
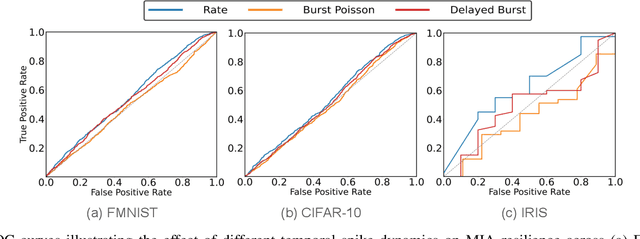
Biological neurons exhibit diverse temporal spike patterns, which are believed to support efficient, robust, and adaptive neural information processing. While models such as Izhikevich can replicate a wide range of these firing dynamics, their complexity poses challenges for directly integrating them into scalable spiking neural networks (SNN) training pipelines. In this work, we propose two probabilistically driven, input-level temporal spike transformations: Poisson-Burst and Delayed-Burst that introduce biologically inspired temporal variability directly into standard Leaky Integrate-and-Fire (LIF) neurons. This enables scalable training and systematic evaluation of how spike timing dynamics affect privacy, generalization, and learning performance. Poisson-Burst modulates burst occurrence based on input intensity, while Delayed-Burst encodes input strength through burst onset timing. Through extensive experiments across multiple benchmarks, we demonstrate that Poisson-Burst maintains competitive accuracy and lower resource overhead while exhibiting enhanced privacy robustness against membership inference attacks, whereas Delayed-Burst provides stronger privacy protection at a modest accuracy trade-off. These findings highlight the potential of biologically grounded temporal spike dynamics in improving the privacy, generalization and biological plausibility of neuromorphic learning systems.
On the Privacy-Preserving Properties of Spiking Neural Networks with Unique Surrogate Gradients and Quantization Levels
Feb 25, 2025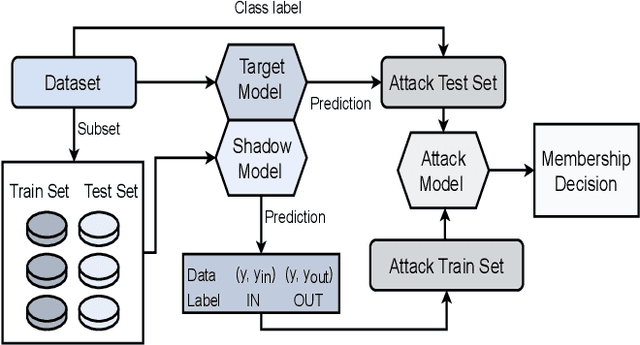
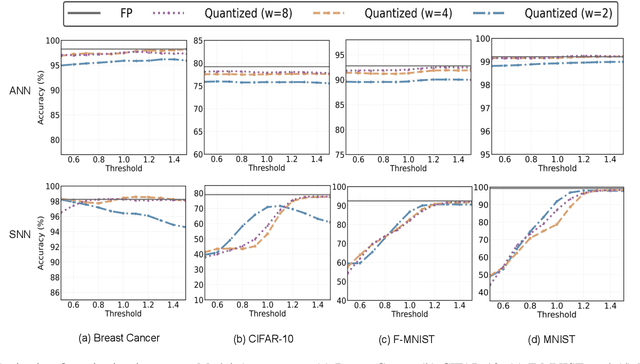
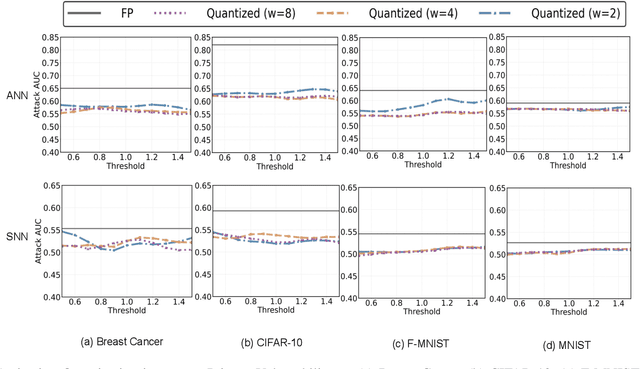
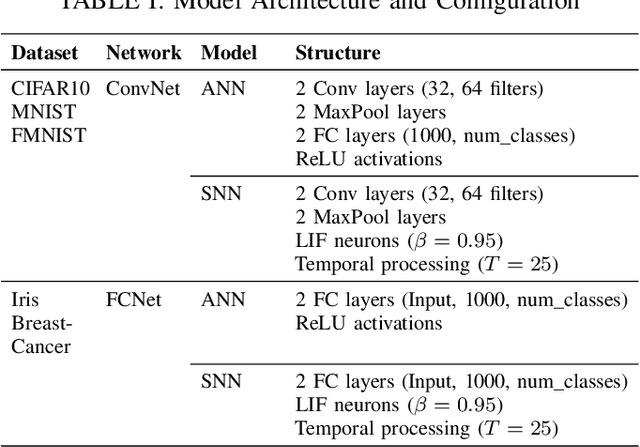
As machine learning models increasingly process sensitive data, understanding their vulnerability to privacy attacks is vital. Membership inference attacks (MIAs) exploit model responses to infer whether specific data points were used during training, posing a significant privacy risk. Prior research suggests that spiking neural networks (SNNs), which rely on event-driven computation and discrete spike-based encoding, exhibit greater resilience to MIAs than artificial neural networks (ANNs). This resilience stems from their non-differentiable activations and inherent stochasticity, which obscure the correlation between model responses and individual training samples. To enhance privacy in SNNs, we explore two techniques: quantization and surrogate gradients. Quantization, which reduces precision to limit information leakage, has improved privacy in ANNs. Given SNNs' sparse and irregular activations, quantization may further disrupt the activation patterns exploited by MIAs. We assess the vulnerability of SNNs and ANNs under weight and activation quantization across multiple datasets, using the attack model's receiver operating characteristic (ROC) curve area under the curve (AUC) metric, where lower values indicate stronger privacy, and evaluate the privacy-accuracy trade-off. Our findings show that quantization enhances privacy in both architectures with minimal performance loss, though full-precision SNNs remain more resilient than quantized ANNs. Additionally, we examine the impact of surrogate gradients on privacy in SNNs. Among five evaluated gradients, spike rate escape provides the best privacy-accuracy trade-off, while arctangent increases vulnerability to MIAs. These results reinforce SNNs' inherent privacy advantages and demonstrate that quantization and surrogate gradient selection significantly influence privacy-accuracy trade-offs in SNNs.
Do Spikes Protect Privacy? Investigating Black-Box Model Inversion Attacks in Spiking Neural Networks
Feb 08, 2025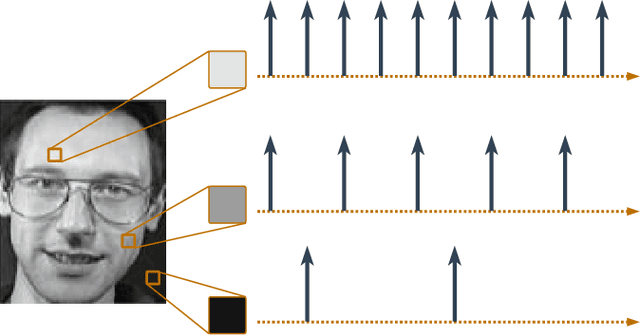
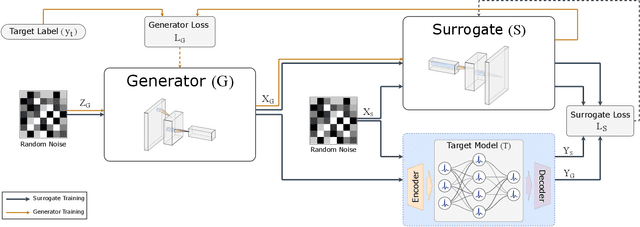


As machine learning models become integral to security-sensitive applications, concerns over data leakage from adversarial attacks continue to rise. Model Inversion (MI) attacks pose a significant privacy threat by enabling adversaries to reconstruct training data from model outputs. While MI attacks on Artificial Neural Networks (ANNs) have been widely studied, Spiking Neural Networks (SNNs) remain largely unexplored in this context. Due to their event-driven and discrete computations, SNNs introduce fundamental differences in information processing that may offer inherent resistance to such attacks. A critical yet underexplored aspect of this threat lies in black-box settings, where attackers operate through queries without direct access to model parameters or gradients-representing a more realistic adversarial scenario in deployed systems. This work presents the first study of black-box MI attacks on SNNs. We adapt a generative adversarial MI framework to the spiking domain by incorporating rate-based encoding for input transformation and decoding mechanisms for output interpretation. Our results show that SNNs exhibit significantly greater resistance to MI attacks than ANNs, as demonstrated by degraded reconstructions, increased instability in attack convergence, and overall reduced attack effectiveness across multiple evaluation metrics. Further analysis suggests that the discrete and temporally distributed nature of SNN decision boundaries disrupts surrogate modeling, limiting the attacker's ability to approximate the target model.
Are Neuromorphic Architectures Inherently Privacy-preserving? An Exploratory Study
Nov 10, 2024
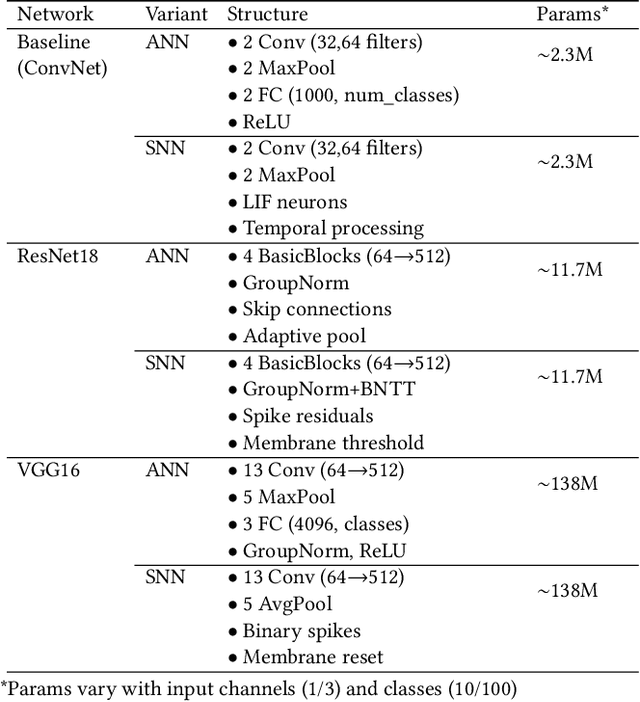
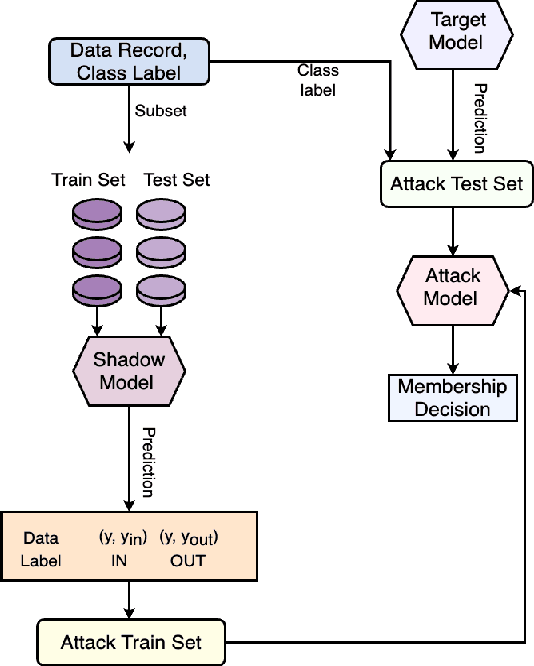
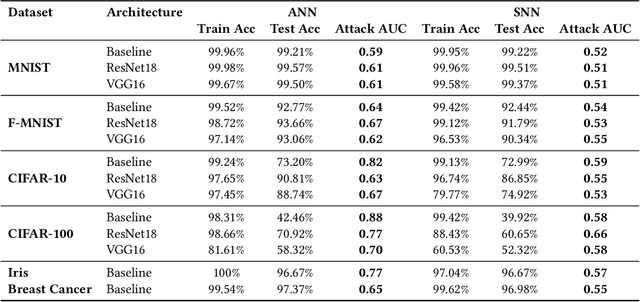
While machine learning (ML) models are becoming mainstream, especially in sensitive application areas, the risk of data leakage has become a growing concern. Attacks like membership inference (MIA) have shown that trained models can reveal sensitive data, jeopardizing confidentiality. While traditional Artificial Neural Networks (ANNs) dominate ML applications, neuromorphic architectures, specifically Spiking Neural Networks (SNNs), are emerging as promising alternatives due to their low power consumption and event-driven processing, akin to biological neurons. Privacy in ANNs is well-studied; however, little work has explored the privacy-preserving properties of SNNs. This paper examines whether SNNs inherently offer better privacy. Using MIAs, we assess the privacy resilience of SNNs versus ANNs across diverse datasets. We analyze the impact of learning algorithms (surrogate gradient and evolutionary), frameworks (snnTorch, TENNLab, LAVA), and parameters on SNN privacy. Our findings show that SNNs consistently outperform ANNs in privacy preservation, with evolutionary algorithms offering additional resilience. For instance, on CIFAR-10, SNNs achieve an AUC of 0.59, significantly lower than ANNs' 0.82, and on CIFAR-100, SNNs maintain an AUC of 0.58 compared to ANNs' 0.88. Additionally, we explore the privacy-utility trade-off with Differentially Private Stochastic Gradient Descent (DPSGD), finding that SNNs sustain less accuracy loss than ANNs under similar privacy constraints.
Bangla sign language recognition using concatenated BdSL network
Jul 25, 2021



Sign language is the only medium of communication for the hearing impaired and the deaf and dumb community. Communication with the general mass is thus always a challenge for this minority group. Especially in Bangla sign language (BdSL), there are 38 alphabets with some having nearly identical symbols. As a result, in BdSL recognition, the posture of hand is an important factor in addition to visual features extracted from traditional Convolutional Neural Network (CNN). In this paper, a novel architecture "Concatenated BdSL Network" is proposed which consists of a CNN based image network and a pose estimation network. While the image network gets the visual features, the relative positions of hand keypoints are taken by the pose estimation network to obtain the additional features to deal with the complexity of the BdSL symbols. A score of 91.51% was achieved by this novel approach in test set and the effectiveness of the additional pose estimation network is suggested by the experimental results.
Semantically Sensible Video Captioning (SSVC)
Sep 15, 2020



Video captioning, i.e. the task of generating captions from video sequences creates a bridge between the Natural Language Processing and Computer Vision domains of computer science. Generating a semantically accurate description of a video is an arduous task. Considering the complexity of the problem, the results obtained in recent researches are quite outstanding. But still there is plenty of scope for improvement. This paper addresses this scope and proposes a novel solution. Most video captioning models comprise of two sequential/recurrent layers - one as a video-to-context encoder and the other as a context-to-caption decoder. This paper proposes a novel architecture, SSVC (Semantically Sensible Video Captioning) which modifies the context generation mechanism by using two novel approaches - "stacked attention" and "spatial hard pull". For evaluating the proposed architecture, along with the BLEU scoring metric for quantitative analysis, we have used a human evaluation metric for qualitative analysis. This paper refers to this proposed human evaluation metric as the Semantic Sensibility (SS) scoring metric. SS score overcomes the shortcomings of common automated scoring metrics. This paper reports that the use of the aforementioned novelties improves the performance of the state-of-the-art architectures.