 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMay the Noise be with you: Adversarial Training without Adversarial Examples
Dec 12, 2023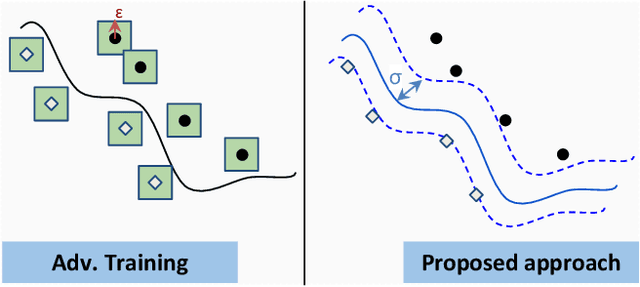
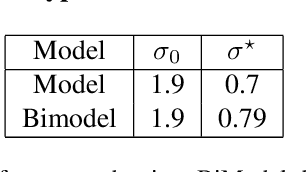
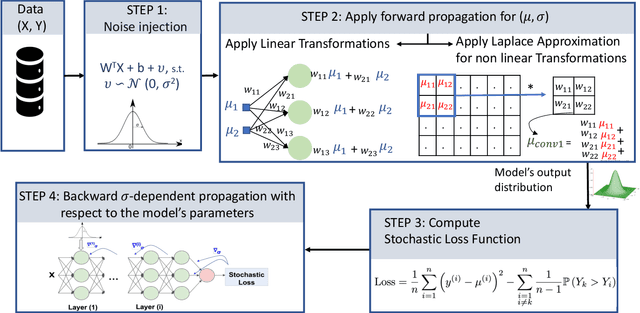
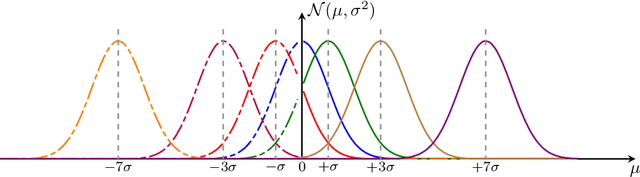
In this paper, we investigate the following question: Can we obtain adversarially-trained models without training on adversarial examples? Our intuition is that training a model with inherent stochasticity, i.e., optimizing the parameters by minimizing a stochastic loss function, yields a robust expectation function that is non-stochastic. In contrast to related methods that introduce noise at the input level, our proposed approach incorporates inherent stochasticity by embedding Gaussian noise within the layers of the NN model at training time. We model the propagation of noise through the layers, introducing a closed-form stochastic loss function that encapsulates a noise variance parameter. Additionally, we contribute a formalized noise-aware gradient, enabling the optimization of model parameters while accounting for stochasticity. Our experimental results confirm that the expectation model of a stochastic architecture trained on benign distribution is adversarially robust. Interestingly, we find that the impact of the applied Gaussian noise's standard deviation on both robustness and baseline accuracy closely mirrors the impact of the noise magnitude employed in adversarial training. Our work contributes adversarially trained networks using a completely different approach, with empirically similar robustness to adversarial training.
Exploring Machine Learning Privacy/Utility trade-off from a hyperparameters Lens
Mar 03, 2023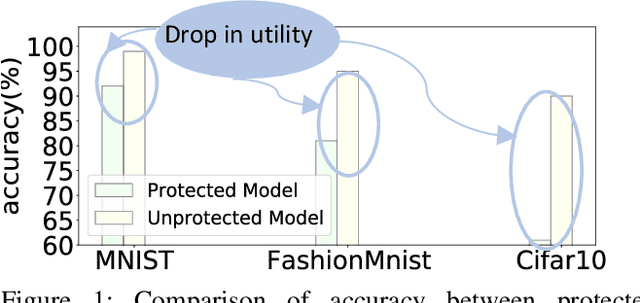
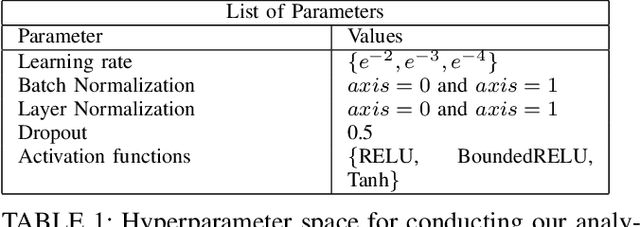
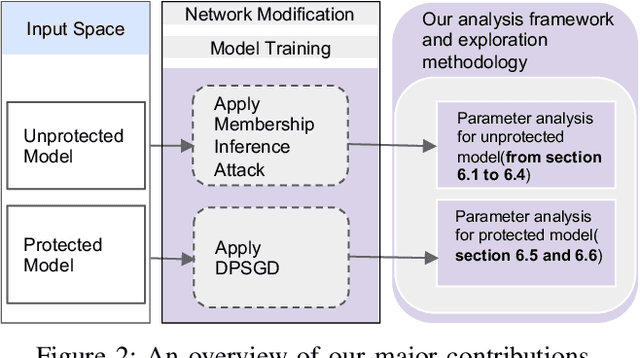
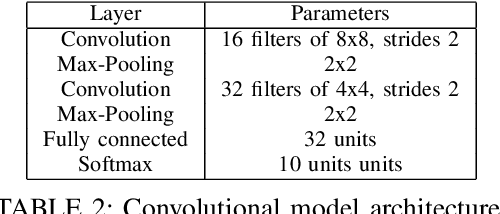
Machine Learning (ML) architectures have been applied to several applications that involve sensitive data, where a guarantee of users' data privacy is required. Differentially Private Stochastic Gradient Descent (DPSGD) is the state-of-the-art method to train privacy-preserving models. However, DPSGD comes at a considerable accuracy loss leading to sub-optimal privacy/utility trade-offs. Towards investigating new ground for better privacy-utility trade-off, this work questions; (i) if models' hyperparameters have any inherent impact on ML models' privacy-preserving properties, and (ii) if models' hyperparameters have any impact on the privacy/utility trade-off of differentially private models. We propose a comprehensive design space exploration of different hyperparameters such as the choice of activation functions, the learning rate and the use of batch normalization. Interestingly, we found that utility can be improved by using Bounded RELU as activation functions with the same privacy-preserving characteristics. With a drop-in replacement of the activation function, we achieve new state-of-the-art accuracy on MNIST (96.02\%), FashionMnist (84.76\%), and CIFAR-10 (44.42\%) without any modification of the learning procedure fundamentals of DPSGD.