 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware Acceleration of Sparse and Irregular Tensor Computations of ML Models: A Survey and Insights
Paper and Code
Jul 02, 2020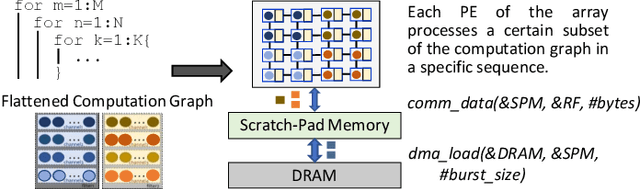


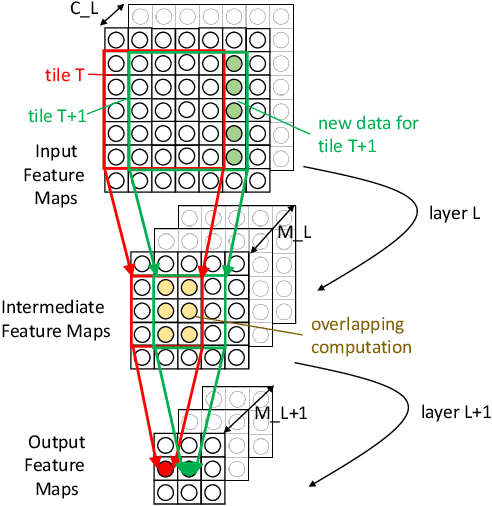
Machine learning (ML) models are widely used in many domains including media processing and generation, computer vision, medical diagnosis, embedded systems, high-performance and scientific computing, and recommendation systems. For efficiently processing these computational- and memory-intensive applications, tensors of these over-parameterized models are compressed by leveraging sparsity, size reduction, and quantization of tensors. Unstructured sparsity and tensors with varying dimensions yield irregular-shaped computation, communication, and memory access patterns; processing them on hardware accelerators in a conventional manner does not inherently leverage acceleration opportunities. This paper provides a comprehensive survey on how to efficiently execute sparse and irregular tensor computations of ML models on hardware accelerators. In particular, it discusses additional enhancement modules in architecture design and software support; categorizes different hardware designs and acceleration techniques and analyzes them in terms of hardware and execution costs; highlights further opportunities in terms of hardware/software/algorithm co-design optimizations and joint optimizations among described hardware and software enhancement modules. The takeaways from this paper include: understanding the key challenges in accelerating sparse, irregular-shaped, and quantized tensors; understanding enhancements in acceleration systems for supporting their efficient computations; analyzing trade-offs in opting for a specific type of design enhancement; understanding how to map and compile models with sparse tensors on the accelerators; understanding recent design trends for efficient accelerations and further opportunities.