 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Split Learning for LLM Fine-Tuning: Models, Systems, and Privacy Optimizations
Apr 27, 2026Fine-tuning unlocks large language models (LLMs) for specialized applications, but its high computational cost often puts it out of reach for resource-constrained organizations. While cloud platforms could provide the needed resources, data privacy concerns make sharing sensitive information with third parties risky. A promising solution is split learning for LLM fine-tuning, which divides the model between clients and a server, allowing collaborative and secure training through exchanged intermediate data, thus enabling resource-constrained participants to adapt LLMs safely. % In light of this, a growing body of literature has emerged to advance this paradigm, introducing varied model methods, system optimizations, and privacy defense-attack techniques for split learning. To bring clarity and direction to the field, a comprehensive survey is needed to classify, compare, and critique these diverse approaches. This paper fills the gap by presenting the first extensive survey dedicated to split learning for LLM fine-tuning. We propose a unified, fine-grained training pipeline to pinpoint key operational components and conduct a systematic review of state-of-the-art work across three core dimensions: model-level optimization, system-level efficiency, and privacy preservation. Through this structured taxonomy, we establish a foundation for advancing scalable, robust, and secure collaborative LLM adaptation.
Secure and Privacy-Preserving Vertical Federated Learning
Apr 15, 2026We propose a novel end-to-end privacy-preserving framework, instantiated by three efficient protocols for different deployment scenarios, covering both input and output privacy, for the vertically split scenario in federated learning (FL), where features are split across clients and labels are not shared by all parties. We do so by distributing the role of the aggregator in FL into multiple servers and having them run secure multiparty computation (MPC) protocols to perform model and feature aggregation and apply differential privacy (DP) to the final released model. While a naive solution would have the clients delegating the entirety of training to run in MPC between the servers, our optimized solution, which supports purely global and also global-local models updates with privacy-preserving, drastically reduces the amount of computation and communication performed using multiparty computation. The experimental results also show the effectiveness of our protocols.
Detecting Data Poisoning in Code Generation LLMs via Black-Box, Vulnerability-Oriented Scanning
Mar 17, 2026Code generation large language models (LLMs) are increasingly integrated into modern software development workflows. Recent work has shown that these models are vulnerable to backdoor and poisoning attacks that induce the generation of insecure code, yet effective defenses remain limited. Existing scanning approaches rely on token-level generation consistency to invert attack targets, which is ineffective for source code where identical semantics can appear in diverse syntactic forms. We present CodeScan, which, to the best of our knowledge, is the first poisoning-scanning framework tailored to code generation models. CodeScan identifies attack targets by analyzing structural similarities across multiple generations conditioned on different clean prompts. It combines iterative divergence analysis with abstract syntax tree (AST)-based normalization to abstract away surface-level variation and unify semantically equivalent code, isolating structures that recur consistently across generations. CodeScan then applies LLM-based vulnerability analysis to determine whether the extracted structures contain security vulnerabilities and flags the model as compromised when such a structure is found. We evaluate CodeScan against four representative attacks under both backdoor and poisoning settings across three real-world vulnerability classes. Experiments on 108 models spanning three architectures and multiple model sizes demonstrate 97%+ detection accuracy with substantially lower false positives than prior methods.
Design of intelligent proofreading system for English translation based on CNN and BERT
Jun 05, 2025Since automatic translations can contain errors that require substantial human post-editing, machine translation proofreading is essential for improving quality. This paper proposes a novel hybrid approach for robust proofreading that combines convolutional neural networks (CNN) with Bidirectional Encoder Representations from Transformers (BERT). In order to extract semantic information from phrases and expressions, CNN uses a variety of convolution kernel filters to capture local n-gram patterns. In the meanwhile, BERT creates context-rich representations of whole sequences by utilizing stacked bidirectional transformer encoders. Using BERT's attention processes, the integrated error detection component relates tokens to spot translation irregularities including word order problems and omissions. The correction module then uses parallel English-German alignment and GRU decoder models in conjunction with translation memory to propose logical modifications that maintain original meaning. A unified end-to-end training process optimized for post-editing performance is applied to the whole pipeline. The multi-domain collection of WMT and the conversational dialogues of Open-Subtitles are two of the English-German parallel corpora used to train the model. Multiple loss functions supervise detection and correction capabilities. Experiments attain a 90% accuracy, 89.37% F1, and 16.24% MSE, exceeding recent proofreading techniques by over 10% overall. Comparative benchmarking demonstrates state-of-the-art performance in identifying and coherently rectifying mistranslations and omissions.
SLVR: Securely Leveraging Client Validation for Robust Federated Learning
Feb 12, 2025Federated Learning (FL) enables collaborative model training while keeping client data private. However, exposing individual client updates makes FL vulnerable to reconstruction attacks. Secure aggregation mitigates such privacy risks but prevents the server from verifying the validity of each client update, creating a privacy-robustness tradeoff. Recent efforts attempt to address this tradeoff by enforcing checks on client updates using zero-knowledge proofs, but they support limited predicates and often depend on public validation data. We propose SLVR, a general framework that securely leverages clients' private data through secure multi-party computation. By utilizing clients' data, SLVR not only eliminates the need for public validation data, but also enables a wider range of checks for robustness, including cross-client accuracy validation. It also adapts naturally to distribution shifts in client data as it can securely refresh its validation data up-to-date. Our empirical evaluations show that SLVR improves robustness against model poisoning attacks, particularly outperforming existing methods by up to 50% under adaptive attacks. Additionally, SLVR demonstrates effective adaptability and stable convergence under various distribution shift scenarios.
Burning the Adversarial Bridges: Robust Windows Malware Detection Against Binary-level Mutations
Oct 05, 2023



Toward robust malware detection, we explore the attack surface of existing malware detection systems. We conduct root-cause analyses of the practical binary-level black-box adversarial malware examples. Additionally, we uncover the sensitivity of volatile features within the detection engines and exhibit their exploitability. Highlighting volatile information channels within the software, we introduce three software pre-processing steps to eliminate the attack surface, namely, padding removal, software stripping, and inter-section information resetting. Further, to counter the emerging section injection attacks, we propose a graph-based section-dependent information extraction scheme for software representation. The proposed scheme leverages aggregated information within various sections in the software to enable robust malware detection and mitigate adversarial settings. Our experimental results show that traditional malware detection models are ineffective against adversarial threats. However, the attack surface can be largely reduced by eliminating the volatile information. Therefore, we propose simple-yet-effective methods to mitigate the impacts of binary manipulation attacks. Overall, our graph-based malware detection scheme can accurately detect malware with an area under the curve score of 88.32\% and a score of 88.19% under a combination of binary manipulation attacks, exhibiting the efficiency of our proposed scheme.
Robust Learning against Logical Adversaries
Jul 01, 2020


Test-time adversarial attacks have posed serious challenges to the robustness of machine learning models, and in many settings the adversarial manipulation needs not be bounded by small $\ell_p$-norms. Motivated by semantic-preserving attacks in security domain, we investigate logical adversaries, a broad class of attackers who create adversarial examples within a reflexive-transitive closure of a logical relation. We analyze the conditions for robustness and propose normalize-and-predict -- a learning framework with provable robustness guarantee. We compare our approach with adversarial training and derive a unified framework that provides the benefits of both approaches.Driven by the theoretical findings, we apply our framework to malware detection. We use our framework to learn new detectors and propose two generic logical attacks to validate model robustness. Experiment results on real-world data set show that attacks using logical relations can evade existing detectors, and our unified framework can significantly enhance model robustness.
Adversarial Examples for Non-Parametric Methods: Attacks, Defenses and Large Sample Limits
Jun 07, 2019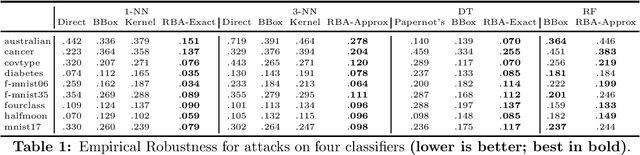
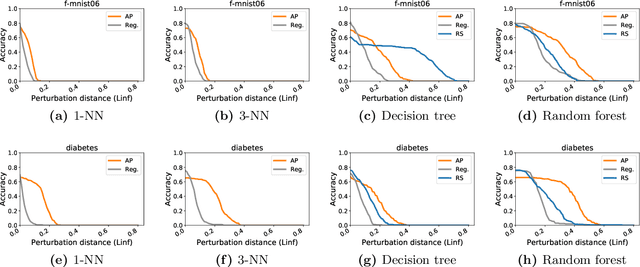
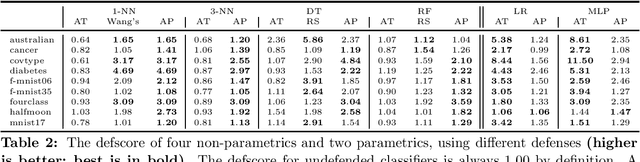
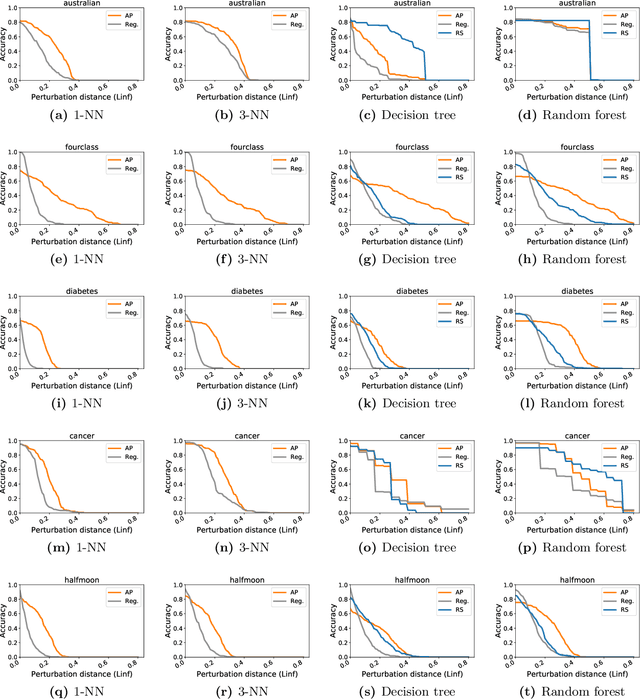
Adversarial examples have received a great deal of recent attention because of their potential to uncover security flaws in machine learning systems. However, most prior work on adversarial examples has been on parametric classifiers, for which generic attack and defense methods are known; non-parametric methods have been only considered on an ad-hoc or classifier-specific basis. In this work, we take a holistic look at adversarial examples for non-parametric methods. We first provide a general region-based attack that applies to a wide range of classifiers, including nearest neighbors, decision trees, and random forests. Motivated by the close connection between non-parametric methods and the Bayes Optimal classifier, we next exhibit a robust analogue to the Bayes Optimal, and we use it to motivate a novel and generic defense that we call adversarial pruning. We empirically show that the region-based attack and adversarial pruning defense are either better than or competitive with existing attacks and defenses for non-parametric methods, while being considerably more generally applicable.
An Investigation of Data Poisoning Defenses for Online Learning
May 28, 2019

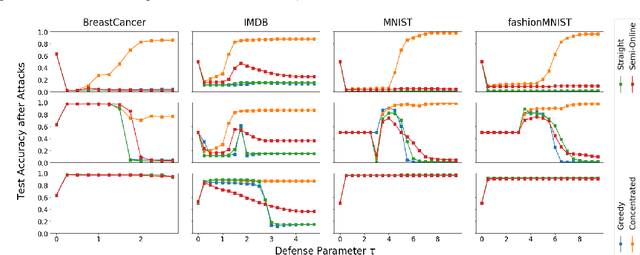
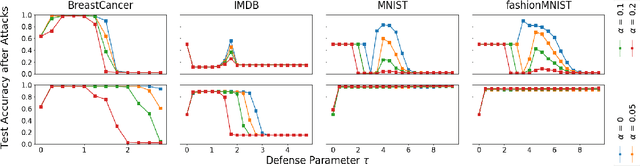
We consider data poisoning attacks, where an adversary can modify a small fraction of training data, with the goal of forcing the trained classifier to have low accuracy. While a body of prior work has developed many attacks and defenses, there is not much general understanding on when various attacks and defenses are effective. In this work, we undertake a rigorous study of defenses against data poisoning in online learning. First, we theoretically analyze four standard defenses and show conditions under which they are effective. Second, motivated by our analysis, we introduce powerful attacks against data-dependent defenses when the adversary can attack the dataset used to initialize them. Finally, we carry out an experimental study which confirms our theoretical findings, shows that the Slab defense is relatively robust, and demonstrates that defenses of moderate strength result in the highest classification accuracy overall.
Data Poisoning Attacks against Online Learning
Aug 27, 2018

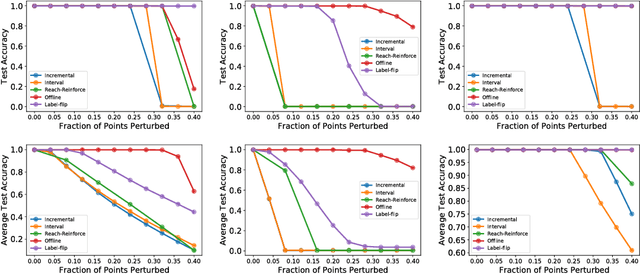

We consider data poisoning attacks, a class of adversarial attacks on machine learning where an adversary has the power to alter a small fraction of the training data in order to make the trained classifier satisfy certain objectives. While there has been much prior work on data poisoning, most of it is in the offline setting, and attacks for online learning, where training data arrives in a streaming manner, are not well understood. In this work, we initiate a systematic investigation of data poisoning attacks for online learning. We formalize the problem into two settings, and we propose a general attack strategy, formulated as an optimization problem, that applies to both with some modifications. We propose three solution strategies, and perform extensive experimental evaluation. Finally, we discuss the implications of our findings for building successful defenses.