 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior of k-NN as an Instance-Based Explanation Method
Paper and Code
Sep 14, 2021

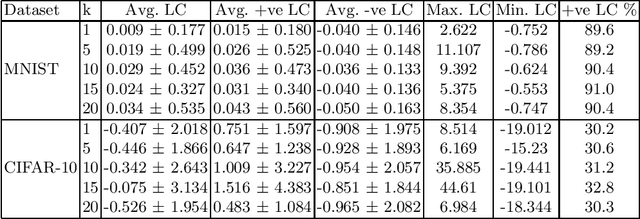

Adoption of DL models in critical areas has led to an escalating demand for sound explanation methods. Instance-based explanation methods are a popular type that return selective instances from the training set to explain the predictions for a test sample. One way to connect these explanations with prediction is to ask the following counterfactual question - how does the loss and prediction for a test sample change when explanations are removed from the training set? Our paper answers this question for k-NNs which are natural contenders for an instance-based explanation method. We first demonstrate empirically that the representation space induced by last layer of a neural network is the best to perform k-NN in. Using this layer, we conduct our experiments and compare them to influence functions (IFs) ~\cite{koh2017understanding} which try to answer a similar question. Our evaluations do indicate change in loss and predictions when explanations are removed but we do not find a trend between $k$ and loss or prediction change. We find significant stability in the predictions and loss of MNIST vs. CIFAR-10. Surprisingly, we do not observe much difference in the behavior of k-NNs vs. IFs on this question. We attribute this to training set subsampling for IFs.