 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Learning of Mallows Block Model
Jun 03, 2019The Mallows model, introduced in the seminal paper of Mallows 1957, is one of the most fundamental ranking distribution over the symmetric group $S_m$. To analyze more complex ranking data, several studies considered the Generalized Mallows model defined by Fligner and Verducci 1986. Despite the significant research interest of ranking distributions, the exact sample complexity of estimating the parameters of a Mallows and a Generalized Mallows Model is not well-understood. The main result of the paper is a tight sample complexity bound for learning Mallows and Generalized Mallows Model. We approach the learning problem by analyzing a more general model which interpolates between the single parameter Mallows Model and the $m$ parameter Mallows model. We call our model Mallows Block Model -- referring to the Block Models that are a popular model in theoretical statistics. Our sample complexity analysis gives tight bound for learning the Mallows Block Model for any number of blocks. We provide essentially matching lower bounds for our sample complexity results. As a corollary of our analysis, it turns out that, if the central ranking is known, one single sample from the Mallows Block Model is sufficient to estimate the spread parameters with error that goes to zero as the size of the permutations goes to infinity. In addition, we calculate the exact rate of the parameter estimation error.
Bandit Multiclass Linear Classification: Efficient Algorithms for the Separable Case
Feb 06, 2019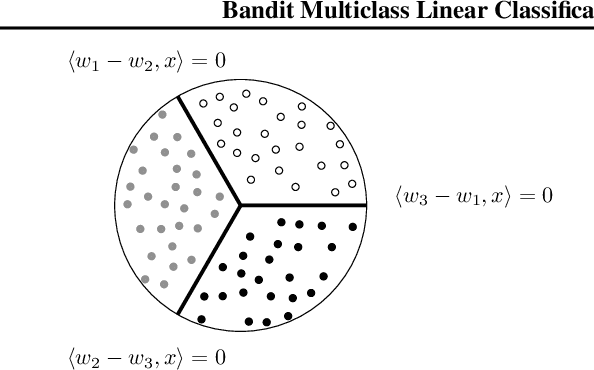
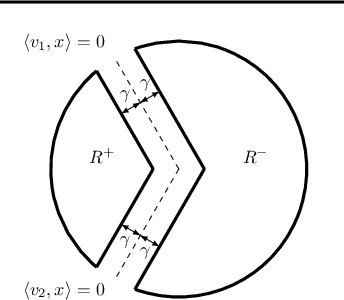

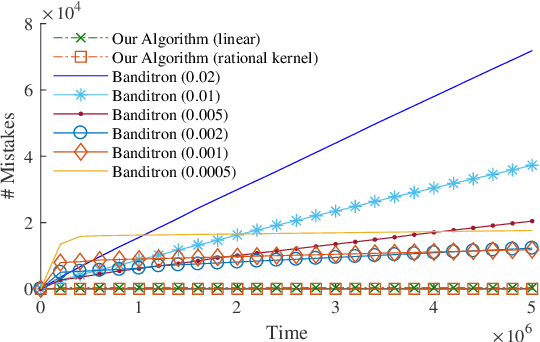
We study the problem of efficient online multiclass linear classification with bandit feedback, where all examples belong to one of $K$ classes and lie in the $d$-dimensional Euclidean space. Previous works have left open the challenge of designing efficient algorithms with finite mistake bounds when the data is linearly separable by a margin $\gamma$. In this work, we take a first step towards this problem. We consider two notions of linear separability, \emph{strong} and \emph{weak}. 1. Under the strong linear separability condition, we design an efficient algorithm that achieves a near-optimal mistake bound of $O\left( K/\gamma^2 \right)$. 2. Under the more challenging weak linear separability condition, we design an efficient algorithm with a mistake bound of $\min (2^{\widetilde{O}(K \log^2 (1/\gamma))}, 2^{\widetilde{O}(\sqrt{1/\gamma} \log K)})$. Our algorithm is based on kernel Perceptron, which is inspired by the work of \citet{Klivans-Servedio-2008} on improperly learning intersection of halfspaces.
The information-theoretic value of unlabeled data in semi-supervised learning
Jan 16, 2019
We quantify the separation between the numbers of labeled examples required to learn in two settings: Settings with and without the knowledge of the distribution of the unlabeled data. More specifically, we prove a separation by $\Theta(\log n)$ multiplicative factor for the class of projections over the Boolean hypercube of dimension $n$. We prove that there is no separation for the class of all functions on domain of any size. Learning with the knowledge of the distribution (a.k.a. fixed-distribution learning) can be viewed as an idealized scenario of semi-supervised learning where the number of unlabeled data points is so great that the unlabeled distribution is known exactly. For this reason, we call the separation the value of unlabeled data.
Finite Sample Analyses for TD with Function Approximation
Dec 11, 2017

TD(0) is one of the most commonly used algorithms in reinforcement learning. Despite this, there is no existing finite sample analysis for TD(0) with function approximation, even for the linear case. Our work is the first to provide such results. Existing convergence rates for Temporal Difference (TD) methods apply only to somewhat modified versions, e.g., projected variants or ones where stepsizes depend on unknown problem parameters. Our analyses obviate these artificial alterations by exploiting strong properties of TD(0). We provide convergence rates both in expectation and with high-probability. The two are obtained via different approaches that use relatively unknown, recently developed stochastic approximation techniques.