 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Stage Pretraining for Molecular Property Prediction in the Wild
Nov 05, 2024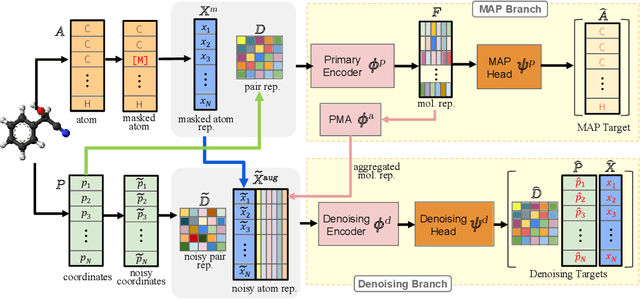

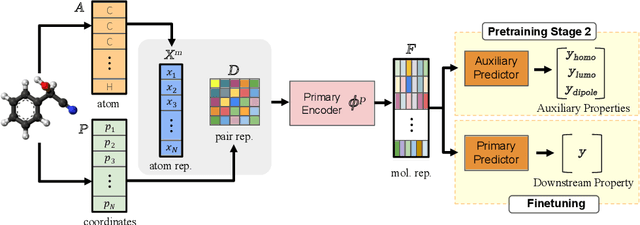
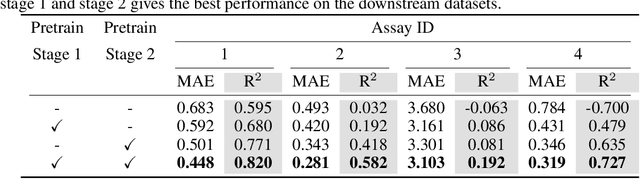
Accurate property prediction is crucial for accelerating the discovery of new molecules. Although deep learning models have achieved remarkable success, their performance often relies on large amounts of labeled data that are expensive and time-consuming to obtain. Thus, there is a growing need for models that can perform well with limited experimentally-validated data. In this work, we introduce MoleVers, a versatile pretrained model designed for various types of molecular property prediction in the wild, i.e., where experimentally-validated molecular property labels are scarce. MoleVers adopts a two-stage pretraining strategy. In the first stage, the model learns molecular representations from large unlabeled datasets via masked atom prediction and dynamic denoising, a novel task enabled by a new branching encoder architecture. In the second stage, MoleVers is further pretrained using auxiliary labels obtained with inexpensive computational methods, enabling supervised learning without the need for costly experimental data. This two-stage framework allows MoleVers to learn representations that generalize effectively across various downstream datasets. We evaluate MoleVers on a new benchmark comprising 22 molecular datasets with diverse types of properties, the majority of which contain 50 or fewer training labels reflecting real-world conditions. MoleVers achieves state-of-the-art results on 20 out of the 22 datasets, and ranks second among the remaining two, highlighting its ability to bridge the gap between data-hungry models and real-world conditions where practically-useful labels are scarce.
Enhancing Performance of Point Cloud Completion Networks with Consistency Loss
Oct 09, 2024Point cloud completion networks are conventionally trained to minimize the disparities between the completed point cloud and the ground-truth counterpart. However, an incomplete object-level point cloud can have multiple valid completion solutions when it is examined in isolation. This one-to-many mapping issue can cause contradictory supervision signals to the network because the loss function may produce different values for identical input-output pairs of the network. In many cases, this issue could adversely affect the network optimization process. In this work, we propose to enhance the conventional learning objective using a novel completion consistency loss to mitigate the one-to-many mapping problem. Specifically, the proposed consistency loss ensure that a point cloud completion network generates a coherent completion solution for incomplete objects originating from the same source point cloud. Experimental results across multiple well-established datasets and benchmarks demonstrated the proposed completion consistency loss have excellent capability to enhance the completion performance of various existing networks without any modification to the design of the networks. The proposed consistency loss enhances the performance of the point completion network without affecting the inference speed, thereby increasing the accuracy of point cloud completion. Notably, a state-of-the-art point completion network trained with the proposed consistency loss can achieve state-of-the-art accuracy on the challenging new MVP dataset. The code and result of experiment various point completion models using proposed consistency loss will be available at: https://github.com/kaist-avelab/ConsistencyLoss .
TrustMol: Trustworthy Inverse Molecular Design via Alignment with Molecular Dynamics
Feb 26, 2024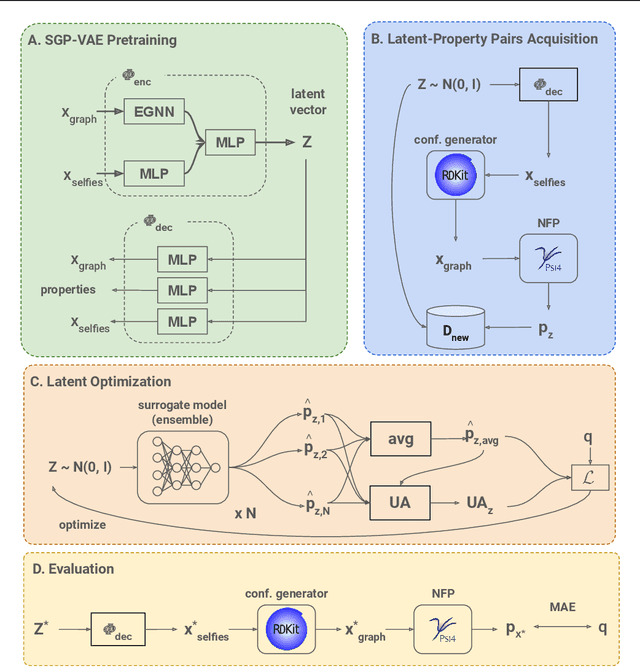
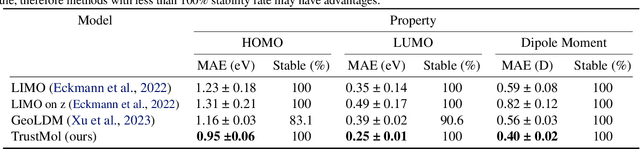
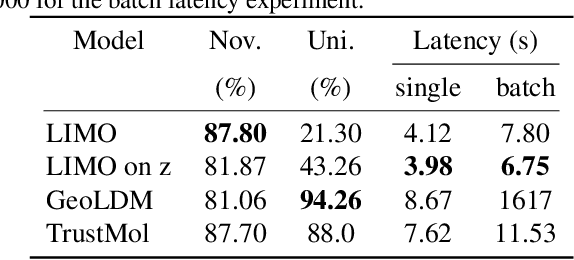

Data-driven generation of molecules with desired properties, also known as inverse molecular design (IMD), has attracted significant attention in recent years. Despite the significant progress in the accuracy and diversity of solutions, existing IMD methods lag behind in terms of trustworthiness. The root issue is that the design process of these methods is increasingly more implicit and indirect, and this process is also isolated from the native forward process (NFP), the ground-truth function that models the molecular dynamics. Following this insight, we propose TrustMol, an IMD method built to be trustworthy. For this purpose, TrustMol relies on a set of technical novelties including a new variational autoencoder network. Moreover, we propose a latent-property pairs acquisition method to effectively navigate the complexities of molecular latent optimization, a process that seems intuitive yet challenging due to the high-frequency and discontinuous nature of molecule space. TrustMol also integrates uncertainty-awareness into molecular latent optimization. These lead to improvements in both explainability and reliability of the IMD process. We validate the trustworthiness of TrustMol through a wide range of experiments.
Enhanced K-Radar: Optimal Density Reduction to Improve Detection Performance and Accessibility of 4D Radar Tensor-based Object Detection
Mar 11, 2023Recent works have shown the superior robustness of four-dimensional (4D) Radar-based three-dimensional (3D) object detection in adverse weather conditions. However, processing 4D Radar data remains a challenge due to the large data size, which require substantial amount of memory for computing and storage. In previous work, an online density reduction is performed on the 4D Radar Tensor (4DRT) to reduce the data size, in which the density reduction level is chosen arbitrarily. However, the impact of density reduction on the detection performance and memory consumption remains largely unknown. In this paper, we aim to address this issue by conducting extensive hyperparamter tuning on the density reduction level. Experimental results show that increasing the density level from 0.01% to 50% of the original 4DRT density level proportionally improves the detection performance, at a cost of memory consumption. However, when the density level is increased beyond 5%, only the memory consumption increases, while the detection performance oscillates below the peak point. In addition to the optimized density hyperparameter, we also introduce 4D Sparse Radar Tensor (4DSRT), a new representation for 4D Radar data with offline density reduction, leading to a significantly reduced raw data size. An optimized development kit for training the neural networks is also provided, which along with the utilization of 4DSRT, improves training speed by a factor of 17.1 compared to the state-of-the-art 4DRT-based neural networks. All codes are available at: https://github.com/kaist-avelab/K-Radar.
Row-wise LiDAR Lane Detection Network with Lane Correlation Refinement
Oct 17, 2022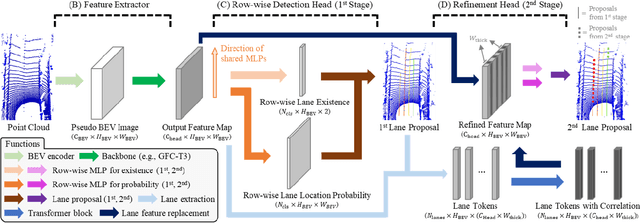
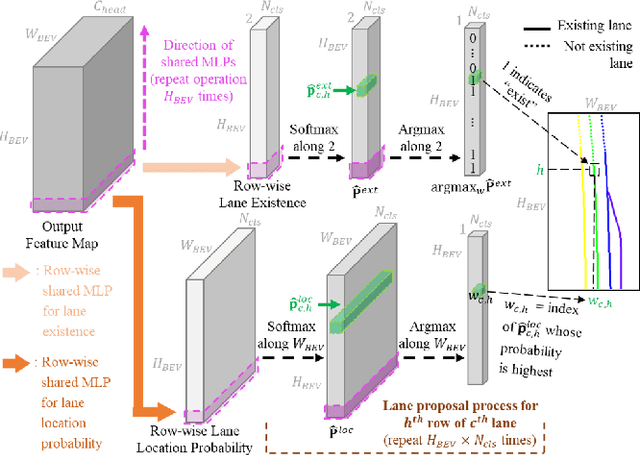


Lane detection is one of the most important functions for autonomous driving. In recent years, deep learning-based lane detection networks with RGB camera images have shown promising performance. However, camera-based methods are inherently vulnerable to adverse lighting conditions such as poor or dazzling lighting. Unlike camera, LiDAR sensor is robust to the lighting conditions. In this work, we propose a novel two-stage LiDAR lane detection network with row-wise detection approach. The first-stage network produces lane proposals through a global feature correlator backbone and a row-wise detection head. Meanwhile, the second-stage network refines the feature map of the first-stage network via attention-based mechanism between the local features around the lane proposals, and outputs a set of new lane proposals. Experimental results on the K-Lane dataset show that the proposed network advances the state-of-the-art in terms of F1-score with 30% less GFLOPs. In addition, the second-stage network is found to be especially robust to lane occlusions, thus, demonstrating the robustness of the proposed network for driving in crowded environments.
K-Radar: 4D Radar Object Detection Dataset and Benchmark for Autonomous Driving in Various Weather Conditions
Jun 16, 2022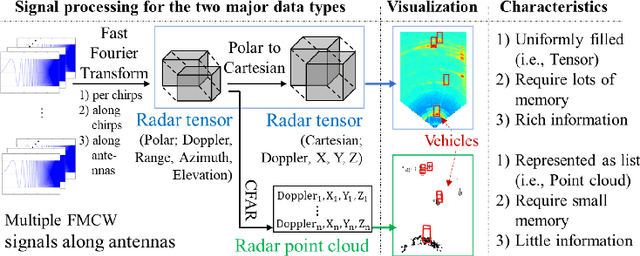
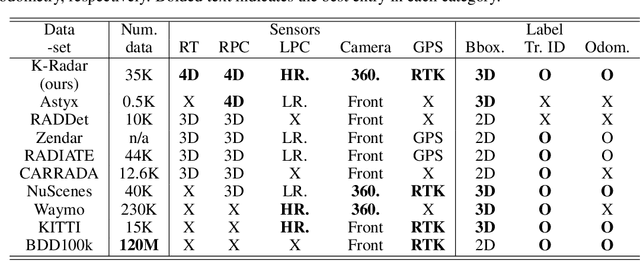


Unlike RGB cameras that use visible light bands (384$\sim$769 THz) and Lidar that use infrared bands (361$\sim$331 THz), Radars use relatively longer wavelength radio bands (77$\sim$81 GHz), resulting in robust measurements in adverse weathers. Unfortunately, existing Radar datasets only contain a relatively small number of samples compared to the existing camera and Lidar datasets. This may hinder the development of sophisticated data-driven deep learning techniques for Radar-based perception. Moreover, most of the existing Radar datasets only provide 3D Radar tensor (3DRT) data that contain power measurements along the Doppler, range, and azimuth dimensions. As there is no elevation information, it is challenging to estimate the 3D bounding box of an object from 3DRT. In this work, we introduce KAIST-Radar (K-Radar), a novel large-scale object detection dataset and benchmark that contains 35K frames of 4D Radar tensor (4DRT) data with power measurements along the Doppler, range, azimuth, and elevation dimensions, together with carefully annotated 3D bounding box labels of objects on the roads. K-Radar includes challenging driving conditions such as adverse weathers (fog, rain, and snow) on various road structures (urban, suburban roads, alleyways, and highways). In addition to the 4DRT, we provide auxiliary measurements from carefully calibrated high-resolution Lidars, surround stereo cameras, and RTK-GPS. We also provide 4DRT-based object detection baseline neural networks (baseline NNs) and show that the height information is crucial for 3D object detection. And by comparing the baseline NN with a similarly-structured Lidar-based neural network, we demonstrate that 4D Radar is a more robust sensor for adverse weather conditions. All codes are available at https://github.com/kaist-avelab/k-radar.
Advanced Feature Learning on Point Clouds using Multi-resolution Features and Learnable Pooling
May 20, 2022
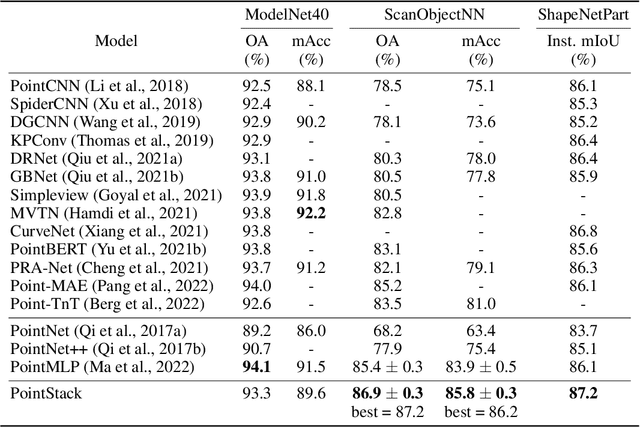


Existing point cloud feature learning networks often incorporate sequences of sampling, neighborhood grouping, neighborhood-wise feature learning, and feature aggregation to learn high-semantic point features that represent the global context of a point cloud. Unfortunately, the compounded loss of information concerning granularity and non-maximum point features due to sampling and max pooling could adversely affect the high-semantic point features from existing networks such that they are insufficient to represent the local context of a point cloud, which in turn may hinder the network in distinguishing fine shapes. To cope with this problem, we propose a novel point cloud feature learning network, PointStack, using multi-resolution feature learning and learnable pooling (LP). The multi-resolution feature learning is realized by aggregating point features of various resolutions in the multiple layers, so that the final point features contain both high-semantic and high-resolution information. On the other hand, the LP is used as a generalized pooling function that calculates the weighted sum of multi-resolution point features through the attention mechanism with learnable queries, in order to extract all possible information from all available point features. Consequently, PointStack is capable of extracting high-semantic point features with minimal loss of information concerning granularity and non-maximum point features. Therefore, the final aggregated point features can effectively represent both global and local contexts of a point cloud. In addition, both the global structure and the local shape details of a point cloud can be well comprehended by the network head, which enables PointStack to advance the state-of-the-art of feature learning on point clouds. The codes are available at https://github.com/kaist-avelab/PointStack.
Mixer-based lidar lane detection network and dataset for urban roads
Oct 21, 2021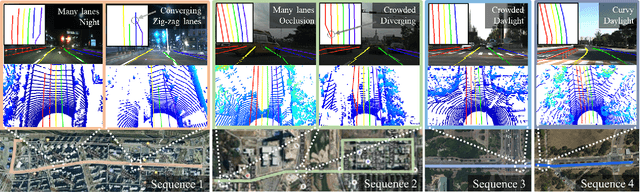
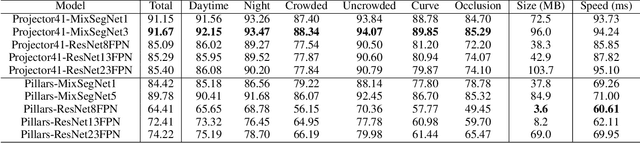
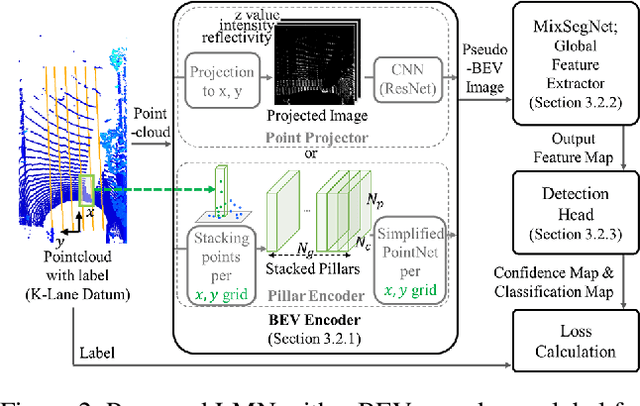

Accurate lane detection under various road conditions is a critical function for autonomous driving. Generally, when detected lane lines from a front camera image are projected into a birds-eye view (BEV) for motion planning, the resulting lane lines are often distorted. And convolutional neural network (CNN)-based feature extractors often lose resolution when increasing the receptive field to detect global features such as lane lines. However, Lidar point cloud has little image distortion in the BEV-projection. Since lane lines are thin and stretch over entire BEV image while occupying only a small portion, lane lines should be detected as a global feature with high resolution. In this paper, we propose Lane Mixer Network (LMN) that extracts local features from Lidar point cloud, recognizes global features, and detects lane lines using a BEV encoder, a Mixer-based global feature extractor, and a detection head, respectively. In addition, we provide a world-first large urban lane dataset for Lidar, K-Lane, which has maximum 6 lanes under various urban road conditions. We demonstrate that the proposed LMN achieves the state-of-the-art performance, an F1 score of 91.67%, with K-Lane. The K-Lane, LMN training code, pre-trained models, and total dataset development platform are available at github.