 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient On-Chip Implementation of 4D Radar-Based 3D Object Detection on Hailo-8L
May 01, 2025

4D radar has attracted attention in autonomous driving due to its ability to enable robust 3D object detection even under adverse weather conditions. To practically deploy such technologies, it is essential to achieve real-time processing within low-power embedded environments. Addressing this, we present the first on-chip implementation of a 4D radar-based 3D object detection model on the Hailo-8L AI accelerator. Although conventional 3D convolutional neural network (CNN) architectures require 5D inputs, the Hailo-8L only supports 4D tensors, posing a significant challenge. To overcome this limitation, we introduce a tensor transformation method that reshapes 5D inputs into 4D formats during the compilation process, enabling direct deployment without altering the model structure. The proposed system achieves 46.47% AP_3D and 52.75% AP_BEV, maintaining comparable accuracy to GPU-based models while achieving an inference speed of 13.76 Hz. These results demonstrate the applicability of 4D radar-based perception technologies to autonomous driving systems.
Availability-aware Sensor Fusion via Unified Canonical Space for 4D Radar, LiDAR, and Camera
Mar 10, 2025
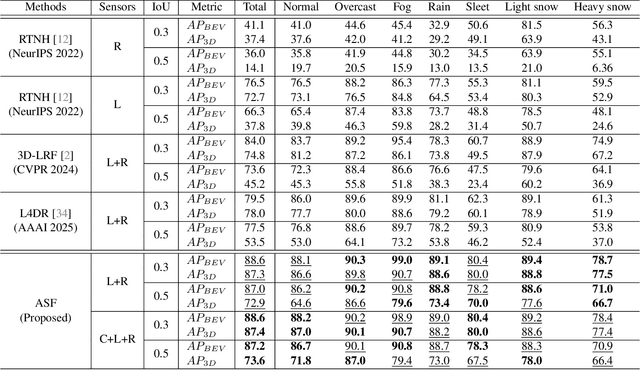


Sensor fusion of camera, LiDAR, and 4-dimensional (4D) Radar has brought a significant performance improvement in autonomous driving (AD). However, there still exist fundamental challenges: deeply coupled fusion methods assume continuous sensor availability, making them vulnerable to sensor degradation and failure, whereas sensor-wise cross-attention fusion methods struggle with computational cost and unified feature representation. This paper presents availability-aware sensor fusion (ASF), a novel method that employs unified canonical projection (UCP) to enable consistency in all sensor features for fusion and cross-attention across sensors along patches (CASAP) to enhance robustness of sensor fusion against sensor degradation and failure. As a result, the proposed ASF shows a superior object detection performance to the existing state-of-the-art fusion methods under various weather and sensor degradation (or failure) conditions; Extensive experiments on the K-Radar dataset demonstrate that ASF achieves improvements of 9.7% in AP BEV (87.2%) and 20.1% in AP 3D (73.6%) in object detection at IoU=0.5, while requiring a low computational cost. The code will be available at https://github.com/kaist-avelab/K-Radar.
4D Radar Ground Truth Augmentation with LiDAR-to-4D Radar Data Synthesis
Mar 05, 2025
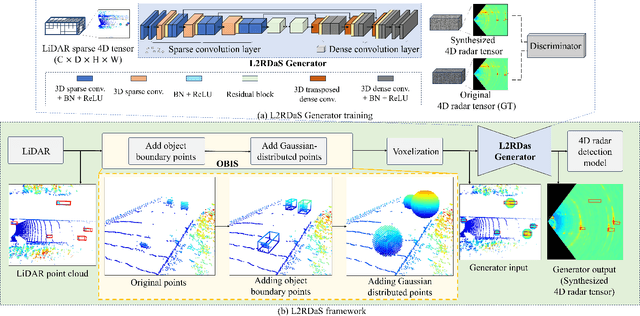


Ground truth augmentation (GT-Aug) is a common method for LiDAR-based object detection, as it enhances object density by leveraging ground truth bounding boxes (GT bboxes). However, directly applying GT-Aug to 4D Radar tensor data overlooks important measurements outside the GT bboxes-such as sidelobes-leading to synthetic distributions that deviate from real-world 4D Radar data. To address this limitation, we propose 4D Radar Ground Truth Augmentation (4DR GT-Aug). Our approach first augments LiDAR data and then converts it to 4D Radar data via a LiDAR-to-4D Radar data synthesis (L2RDaS) module, which explicitly accounts for measurements both inside and outside GT bboxes. In doing so, it produces 4D Radar data distributions that more closely resemble real-world measurements, thereby improving object detection accuracy. Experiments on the K-Radar dataset show that the proposed method achieves improved performance compared to conventional GT-Aug in object detection for 4D Radar. The implementation code is available at https://github.com/kaist-avelab/K-Radar.
A Novel Multi-Teacher Knowledge Distillation for Real-Time Object Detection using 4D Radar
Feb 10, 2025



Accurate 3D object detection is crucial for safe autonomous navigation, requiring reliable performance across diverse weather conditions. While LiDAR performance deteriorates in challenging weather, Radar systems maintain their reliability. Traditional Radars have limitations due to their lack of elevation data, but the recent 4D Radars overcome this by measuring elevation alongside range, azimuth, and Doppler velocity, making them invaluable for autonomous vehicles. The primary challenge in utilizing 4D Radars is the sparsity of their point clouds. Previous works address this by developing architectures that better capture semantics and context in sparse point cloud, largely drawing from LiDAR-based approaches. However, these methods often overlook a unique advantage of 4D Radars: the dense Radar tensor, which encapsulates power measurements across three spatial dimensions and the Doppler dimension. Our paper leverages this tensor to tackle the sparsity issue. We introduce a novel knowledge distillation framework that enables a student model to densify its sparse input in the latent space by emulating an ensemble of teacher models. Our experiments demonstrate a 25% performance improvement over the state-of-the-art RTNH model on the K-Radar dataset. Notably, this improvement is achieved while still maintaining a real-time inference speed.
4DR P2T: 4D Radar Tensor Synthesis with Point Clouds
Feb 08, 2025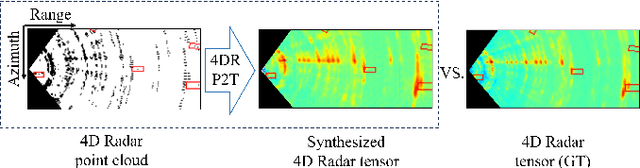
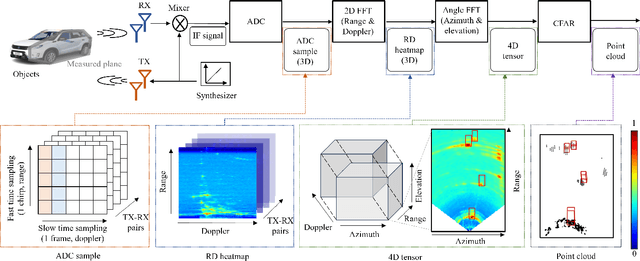
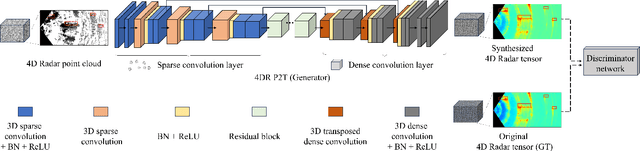
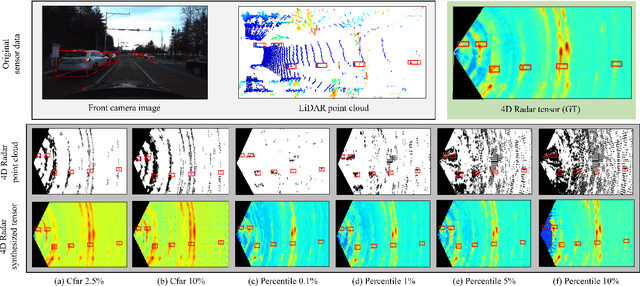
In four-dimensional (4D) Radar-based point cloud generation, clutter removal is commonly performed using the constant false alarm rate (CFAR) algorithm. However, CFAR may not fully capture the spatial characteristics of objects. To address limitation, this paper proposes the 4D Radar Point-to-Tensor (4DR P2T) model, which generates tensor data suitable for deep learning applications while minimizing measurement loss. Our method employs a conditional generative adversarial network (cGAN), modified to effectively process 4D Radar point cloud data and generate tensor data. Experimental results on the K-Radar dataset validate the effectiveness of the 4DR P2T model, achieving an average PSNR of 30.39dB and SSIM of 0.96. Additionally, our analysis of different point cloud generation methods highlights that the 5% percentile method provides the best overall performance, while the 1% percentile method optimally balances data volume reduction and performance, making it well-suited for deep learning applications.
Bayesian Approximation-Based Trajectory Prediction and Tracking with 4D Radar
Feb 03, 2025



Accurate 3D multi-object tracking (MOT) is vital for autonomous vehicles, yet LiDAR and camera-based methods degrade in adverse weather. Meanwhile, Radar-based solutions remain robust but often suffer from limited vertical resolution and simplistic motion models. Existing Kalman filter-based approaches also rely on fixed noise covariance, hampering adaptability when objects make sudden maneuvers. We propose Bayes-4DRTrack, a 4D Radar-based MOT framework that adopts a transformer-based motion prediction network to capture nonlinear motion dynamics and employs Bayesian approximation in both detection and prediction steps. Moreover, our two-stage data association leverages Doppler measurements to better distinguish closely spaced targets. Evaluated on the K-Radar dataset (including adverse weather scenarios), Bayes-4DRTrack demonstrates a 5.7% gain in Average Multi-Object Tracking Accuracy (AMOTA) over methods with traditional motion models and fixed noise covariance. These results showcase enhanced robustness and accuracy in demanding, real-world conditions.
Open-Source Autonomous Driving Software Platforms: Comparison of Autoware and Apollo
Jan 31, 2025



Full-stack autonomous driving system spans diverse technological domains-including perception, planning, and control-that each require in-depth research. Moreover, validating such technologies of the system necessitates extensive supporting infrastructure, from simulators and sensors to high-definition maps. These complexities with barrier to entry pose substantial limitations for individual developers and research groups. Recently, open-source autonomous driving software platforms have emerged to address this challenge by providing autonomous driving technologies and practical supporting infrastructure for implementing and evaluating autonomous driving functionalities. Among the prominent open-source platforms, Autoware and Apollo are frequently adopted in both academia and industry. While previous studies have assessed each platform independently, few have offered a quantitative and detailed head-to-head comparison of their capabilities. In this paper, we systematically examine the core modules of Autoware and Apollo and evaluate their middleware performance to highlight key differences. These insights serve as a practical reference for researchers and engineers, guiding them in selecting the most suitable platform for their specific development environments and advancing the field of full-stack autonomous driving system.
RTNH+: Enhanced 4D Radar Object Detection Network using Combined CFAR-based Two-level Preprocessing and Vertical Encoding
Oct 19, 2023



Four-dimensional (4D) Radar is a useful sensor for 3D object detection and the relative radial speed estimation of surrounding objects under various weather conditions. However, since Radar measurements are corrupted with invalid components such as noise, interference, and clutter, it is necessary to employ a preprocessing algorithm before the 3D object detection with neural networks. In this paper, we propose RTNH+ that is an enhanced version of RTNH, a 4D Radar object detection network, by two novel algorithms. The first algorithm is the combined constant false alarm rate (CFAR)-based two-level preprocessing (CCTP) algorithm that generates two filtered measurements of different characteristics using the same 4D Radar measurements, which can enrich the information of the input to the 4D Radar object detection network. The second is the vertical encoding (VE) algorithm that effectively encodes vertical features of the road objects from the CCTP outputs. We provide details of the RTNH+, and demonstrate that RTNH+ achieves significant performance improvement of 10.14\% in ${{AP}_{3D}^{IoU=0.3}}$ and 16.12\% in ${{AP}_{3D}^{IoU=0.5}}$ over RTNH.
Enhanced K-Radar: Optimal Density Reduction to Improve Detection Performance and Accessibility of 4D Radar Tensor-based Object Detection
Mar 11, 2023Recent works have shown the superior robustness of four-dimensional (4D) Radar-based three-dimensional (3D) object detection in adverse weather conditions. However, processing 4D Radar data remains a challenge due to the large data size, which require substantial amount of memory for computing and storage. In previous work, an online density reduction is performed on the 4D Radar Tensor (4DRT) to reduce the data size, in which the density reduction level is chosen arbitrarily. However, the impact of density reduction on the detection performance and memory consumption remains largely unknown. In this paper, we aim to address this issue by conducting extensive hyperparamter tuning on the density reduction level. Experimental results show that increasing the density level from 0.01% to 50% of the original 4DRT density level proportionally improves the detection performance, at a cost of memory consumption. However, when the density level is increased beyond 5%, only the memory consumption increases, while the detection performance oscillates below the peak point. In addition to the optimized density hyperparameter, we also introduce 4D Sparse Radar Tensor (4DSRT), a new representation for 4D Radar data with offline density reduction, leading to a significantly reduced raw data size. An optimized development kit for training the neural networks is also provided, which along with the utilization of 4DSRT, improves training speed by a factor of 17.1 compared to the state-of-the-art 4DRT-based neural networks. All codes are available at: https://github.com/kaist-avelab/K-Radar.
Row-wise LiDAR Lane Detection Network with Lane Correlation Refinement
Oct 17, 2022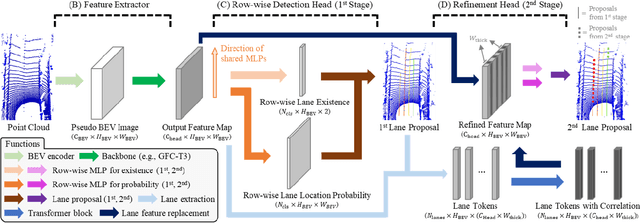
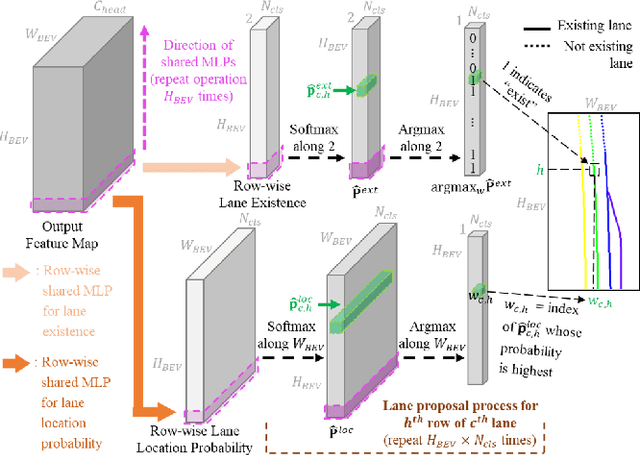


Lane detection is one of the most important functions for autonomous driving. In recent years, deep learning-based lane detection networks with RGB camera images have shown promising performance. However, camera-based methods are inherently vulnerable to adverse lighting conditions such as poor or dazzling lighting. Unlike camera, LiDAR sensor is robust to the lighting conditions. In this work, we propose a novel two-stage LiDAR lane detection network with row-wise detection approach. The first-stage network produces lane proposals through a global feature correlator backbone and a row-wise detection head. Meanwhile, the second-stage network refines the feature map of the first-stage network via attention-based mechanism between the local features around the lane proposals, and outputs a set of new lane proposals. Experimental results on the K-Lane dataset show that the proposed network advances the state-of-the-art in terms of F1-score with 30% less GFLOPs. In addition, the second-stage network is found to be especially robust to lane occlusions, thus, demonstrating the robustness of the proposed network for driving in crowded environments.