 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarkovian Agents for Truthful Language Modeling
Apr 29, 2024Chain-of-Thought (CoT) reasoning could in principle enable a deeper understanding of a language model's (LM) internal reasoning. However, prior work suggests that some LMs answer questions similarly despite changes in their CoT, suggesting that those models are not truly using the CoT. We propose a training method to produce CoTs that are sufficient alone for predicting future text, independent of other context. This methodology gives a guarantee that if the LM can predict future tokens, then it must have used the CoT to understand its context. We formalize the idea that the truthfulness of a sender to a receiver LM is the degree to which the sender helps the receiver predict their future observations. Then we define a "Markovian" LM as one which predicts future text given only a CoT as context. We derive a "Markovian training" procedure by applying our definition of truthfulness to a Markovian LM and optimizing via policy gradient and Proximal Policy Optimization (PPO). We demonstrate the effectiveness of our training algorithm on long-context arithmetic problems, show that the model utilizes the CoT, and validate that the generated CoT is meaningful and usable by other models.
SuperHF: Supervised Iterative Learning from Human Feedback
Oct 25, 2023


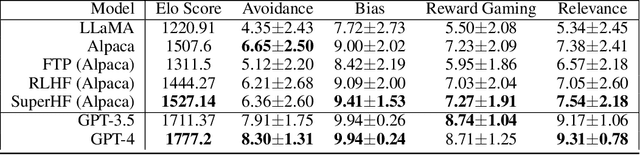
While large language models demonstrate remarkable capabilities, they often present challenges in terms of safety, alignment with human values, and stability during training. Here, we focus on two prevalent methods used to align these models, Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). SFT is simple and robust, powering a host of open-source models, while RLHF is a more sophisticated method used in top-tier models like ChatGPT but also suffers from instability and susceptibility to reward hacking. We propose a novel approach, Supervised Iterative Learning from Human Feedback (SuperHF), which seeks to leverage the strengths of both methods. Our hypothesis is two-fold: that the reward model used in RLHF is critical for efficient data use and model generalization and that the use of Proximal Policy Optimization (PPO) in RLHF may not be necessary and could contribute to instability issues. SuperHF replaces PPO with a simple supervised loss and a Kullback-Leibler (KL) divergence prior. It creates its own training data by repeatedly sampling a batch of model outputs and filtering them through the reward model in an online learning regime. We then break down the reward optimization problem into three components: robustly optimizing the training rewards themselves, preventing reward hacking-exploitation of the reward model that degrades model performance-as measured by a novel METEOR similarity metric, and maintaining good performance on downstream evaluations. Our experimental results show SuperHF exceeds PPO-based RLHF on the training objective, easily and favorably trades off high reward with low reward hacking, improves downstream calibration, and performs the same on our GPT-4 based qualitative evaluation scheme all the while being significantly simpler to implement, highlighting SuperHF's potential as a competitive language model alignment technique.
Do Neural Networks Generalize from Self-Averaging Sub-classifiers in the Same Way As Adaptive Boosting?
Feb 14, 2023In recent years, neural networks (NNs) have made giant leaps in a wide variety of domains. NNs are often referred to as black box algorithms due to how little we can explain their empirical success. Our foundational research seeks to explain why neural networks generalize. A recent advancement derived a mutual information measure for explaining the performance of deep NNs through a sequence of increasingly complex functions. We show deep NNs learn a series of boosted classifiers whose generalization is popularly attributed to self-averaging over an increasing number of interpolating sub-classifiers. To our knowledge, we are the first authors to establish the connection between generalization in boosted classifiers and generalization in deep NNs. Our experimental evidence and theoretical analysis suggest NNs trained with dropout exhibit similar self-averaging behavior over interpolating sub-classifiers as cited in popular explanations for the post-interpolation generalization phenomenon in boosting.