Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlpha-Mini: Minichess Agent with Deep Reinforcement Learning
Paper and Code

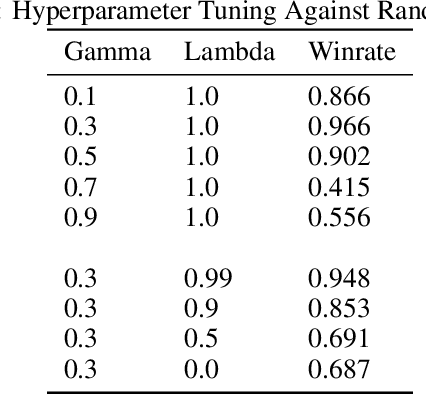
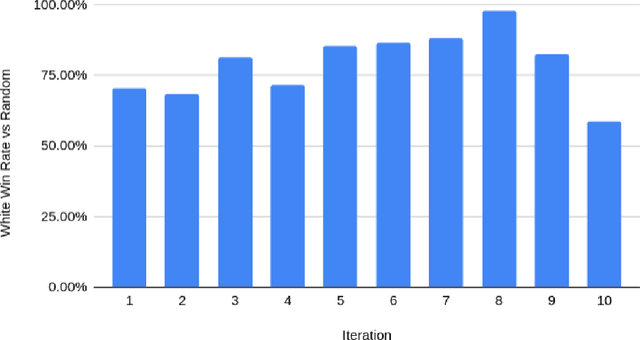
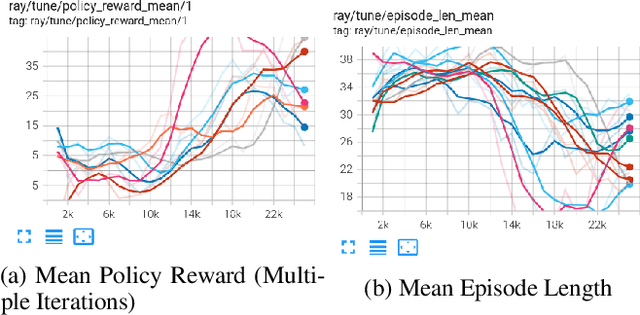
We train an agent to compete in the game of Gardner minichess, a downsized variation of chess played on a 5x5 board. We motivated and applied a SOTA actor-critic method Proximal Policy Optimization with Generalized Advantage Estimation. Our initial task centered around training the agent against a random agent. Once we obtained reasonable performance, we then adopted a version of iterative policy improvement adopted by AlphaGo to pit the agent against increasingly stronger versions of itself, and evaluate the resulting performance gain. The final agent achieves a near (.97) perfect win rate against a random agent. We also explore the effects of pretraining the network using a collection of positions obtained via self-play.
View paper on