 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Attention-aware Rendering for Virtual and Augmented Reality
Feb 02, 2023


Foveated graphics is a promising approach to solving the bandwidth challenges of immersive virtual and augmented reality displays by exploiting the falloff in spatial acuity in the periphery of the visual field. However, the perceptual models used in these applications neglect the effects of higher-level cognitive processing, namely the allocation of visual attention, and are thus overestimating sensitivity in the periphery in many scenarios. Here, we introduce the first attention-aware model of contrast sensitivity. We conduct user studies to measure contrast sensitivity under different attention distributions and show that sensitivity in the periphery drops significantly when the user is required to allocate attention to the fovea. We motivate the development of future foveation models with another user study and demonstrate that tolerance for foveation in the periphery is significantly higher when the user is concentrating on a task in the fovea. Analysis of our model predicts potential bandwidth savings over 9 times higher than those afforded by current models. As such, our work forms the foundation for attention-aware foveated graphics techniques.
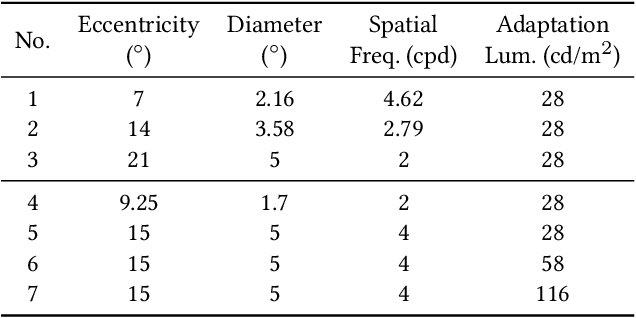
A Perceptual Model for Eccentricity-dependent Spatio-temporal Flicker Fusion and its Applications to Foveated Graphics
May 26, 2021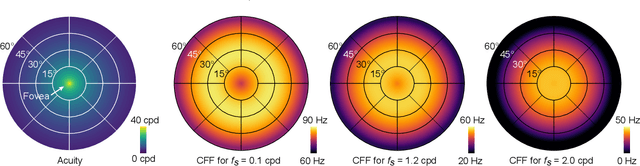
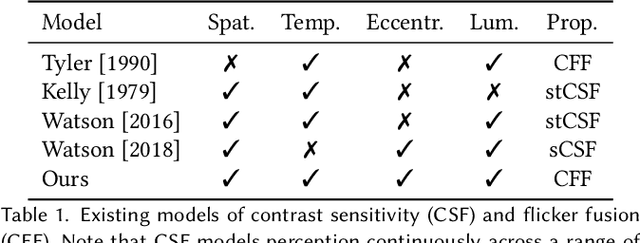

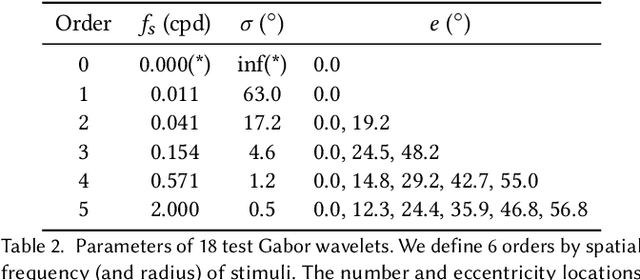
Virtual and augmented reality (VR/AR) displays strive to provide a resolution, framerate and field of view that matches the perceptual capabilities of the human visual system, all while constrained by limited compute budgets and transmission bandwidths of wearable computing systems. Foveated graphics techniques have emerged that could achieve these goals by exploiting the falloff of spatial acuity in the periphery of the visual field. However, considerably less attention has been given to temporal aspects of human vision, which also vary across the retina. This is in part due to limitations of current eccentricity-dependent models of the visual system. We introduce a new model, experimentally measuring and computationally fitting eccentricity-dependent critical flicker fusion thresholds jointly for both space and time. In this way, our model is unique in enabling the prediction of temporal information that is imperceptible for a certain spatial frequency, eccentricity, and range of luminance levels. We validate our model with an image quality user study, and use it to predict potential bandwidth savings 7x higher than those afforded by current spatial-only foveated models. As such, this work forms the enabling foundation for new temporally foveated graphics techniques.