 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Multitask Prompted Training Enables Zero-Shot Task Generalization
Oct 15, 2021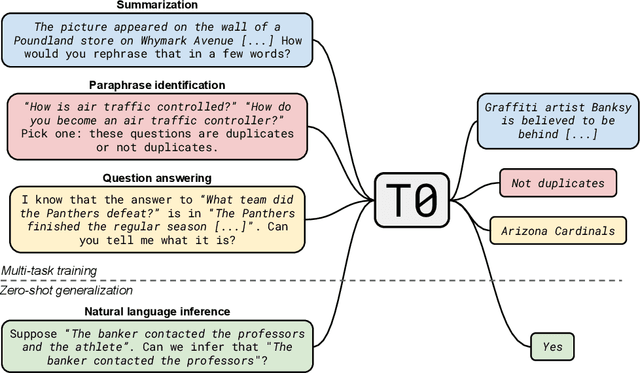


Large language models have recently been shown to attain reasonable zero-shot generalization on a diverse set of tasks. It has been hypothesized that this is a consequence of implicit multitask learning in language model training. Can zero-shot generalization instead be directly induced by explicit multitask learning? To test this question at scale, we develop a system for easily mapping general natural language tasks into a human-readable prompted form. We convert a large set of supervised datasets, each with multiple prompts using varying natural language. These prompted datasets allow for benchmarking the ability of a model to perform completely unseen tasks specified in natural language. We fine-tune a pretrained encoder-decoder model on this multitask mixture covering a wide variety of tasks. The model attains strong zero-shot performance on several standard datasets, often outperforming models 16x its size. Further, our approach attains strong performance on a subset of tasks from the BIG-Bench benchmark, outperforming models 6x its size. All prompts and trained models are available at github.com/bigscience-workshop/promptsource/.
DRIFT: A Toolkit for Diachronic Analysis of Scientific Literature
Jul 16, 2021


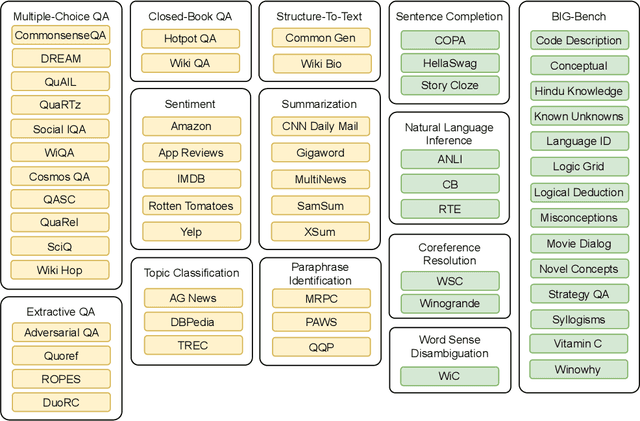
In this work, we present to the NLP community, and to the wider research community as a whole, an application for the diachronic analysis of research corpora. We open source an easy-to-use tool coined: DRIFT, which allows researchers to track research trends and development over the years. The analysis methods are collated from well-cited research works, with a few of our own methods added for good measure. Succinctly put, some of the analysis methods are: keyword extraction, word clouds, predicting declining/stagnant/growing trends using Productivity, tracking bi-grams using Acceleration plots, finding the Semantic Drift of words, tracking trends using similarity, etc. To demonstrate the utility and efficacy of our tool, we perform a case study on the cs.CL corpus of the arXiv repository and draw inferences from the analysis methods. The toolkit and the associated code are available here: https://github.com/rajaswa/DRIFT.
Superpixel-based Domain-Knowledge Infusion in Computer Vision
May 20, 2021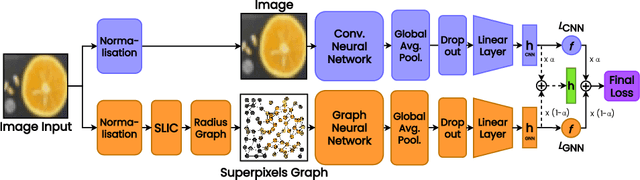

Superpixels are higher-order perceptual groups of pixels in an image, often carrying much more information than raw pixels. There is an inherent relational structure to the relationship among different superpixels of an image. This relational information can convey some form of domain information about the image, e.g. relationship between superpixels representing two eyes in a cat image. Our interest in this paper is to construct computer vision models, specifically those based on Deep Neural Networks (DNNs) to incorporate these superpixels information. We propose a methodology to construct a hybrid model that leverages (a) Convolutional Neural Network (CNN) to deal with spatial information in an image, and (b) Graph Neural Network (GNN) to deal with relational superpixel information in the image. The proposed deep model is learned using a generic hybrid loss function that we call a `hybrid' loss. We evaluate the predictive performance of our proposed hybrid vision model on four popular image classification datasets: MNIST, FMNIST, CIFAR-10 and CIFAR-100. Moreover, we evaluate our method on three real-world classification tasks: COVID-19 X-Ray Detection, LFW Face Recognition, and SOCOFing Fingerprint Identification. The results demonstrate that the relational superpixel information provided via a GNN could improve the performance of standard CNN-based vision systems.
LRG at TREC 2020: Document Ranking with XLNet-Based Models
Mar 06, 2021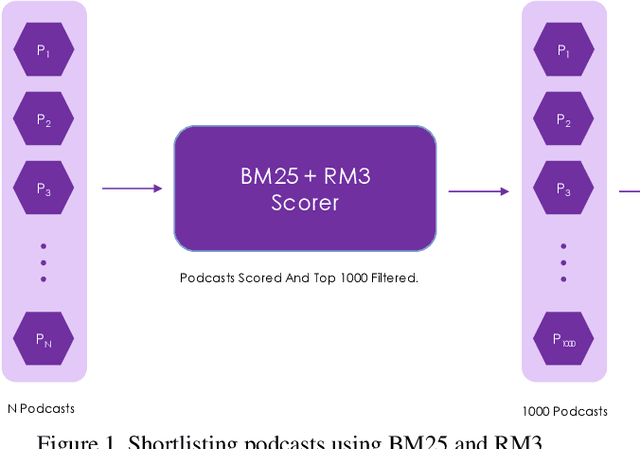

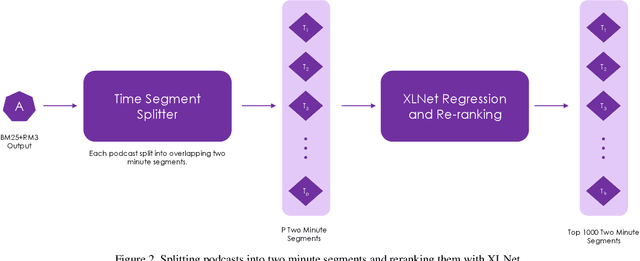
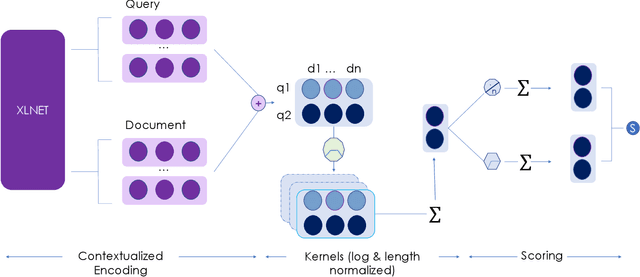
Establishing a good information retrieval system in popular mediums of entertainment is a quickly growing area of investigation for companies and researchers alike. We delve into the domain of information retrieval for podcasts. In Spotify's Podcast Challenge, we are given a user's query with a description to find the most relevant short segment from the given dataset having all the podcasts. Previous techniques that include solely classical Information Retrieval (IR) techniques, perform poorly when descriptive queries are presented. On the other hand, models which exclusively rely on large neural networks tend to perform better. The downside to this technique is that a considerable amount of time and computing power are required to infer the result. We experiment with two hybrid models which first filter out the best podcasts based on user's query with a classical IR technique, and then perform re-ranking on the shortlisted documents based on the detailed description using a transformer-based model.
* Published at TREC 2020
LRG at SemEval-2021 Task 4: Improving Reading Comprehension with Abstract Words using Augmentation, Linguistic Features and Voting
Feb 24, 2021
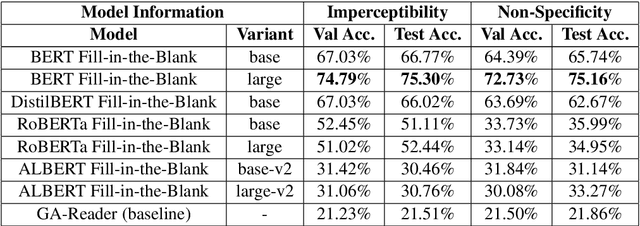
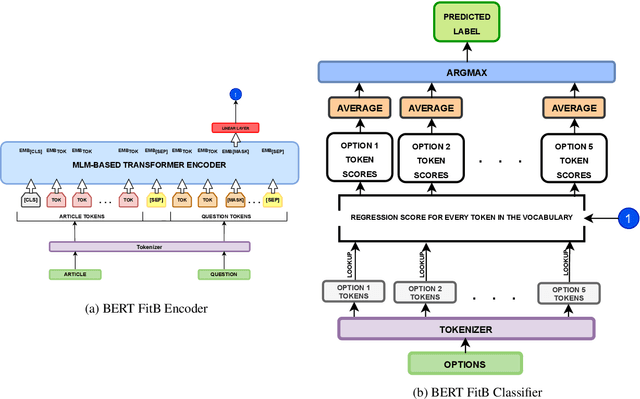
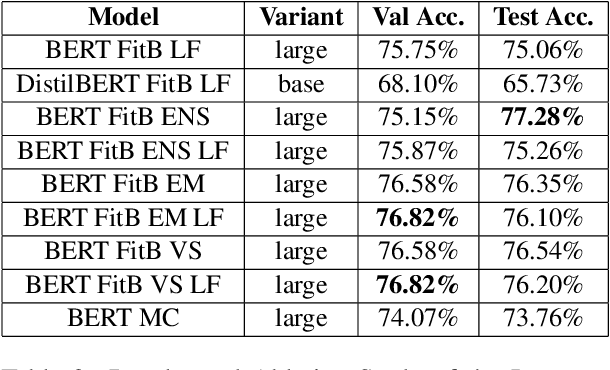
In this article, we present our methodologies for SemEval-2021 Task-4: Reading Comprehension of Abstract Meaning. Given a fill-in-the-blank-type question and a corresponding context, the task is to predict the most suitable word from a list of 5 options. There are three sub-tasks within this task: Imperceptibility (subtask-I), Non-Specificity (subtask-II), and Intersection (subtask-III). We use encoders of transformers-based models pre-trained on the masked language modelling (MLM) task to build our Fill-in-the-blank (FitB) models. Moreover, to model imperceptibility, we define certain linguistic features, and to model non-specificity, we leverage information from hypernyms and hyponyms provided by a lexical database. Specifically, for non-specificity, we try out augmentation techniques, and other statistical techniques. We also propose variants, namely Chunk Voting and Max Context, to take care of input length restrictions for BERT, etc. Additionally, we perform a thorough ablation study, and use Integrated Gradients to explain our predictions on a few samples. Our best submissions achieve accuracies of 75.31% and 77.84%, on the test sets for subtask-I and subtask-II, respectively. For subtask-III, we achieve accuracies of 65.64% and 62.27%.
NLRG at SemEval-2021 Task 5: Toxic Spans Detection Leveraging BERT-based Token Classification and Span Prediction Techniques
Feb 24, 2021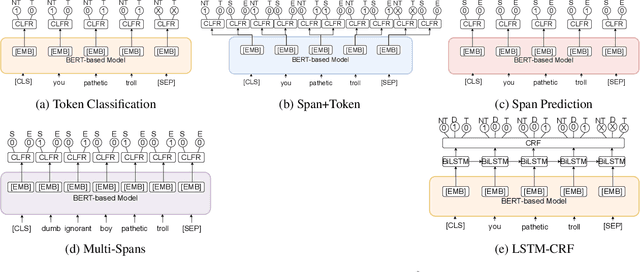
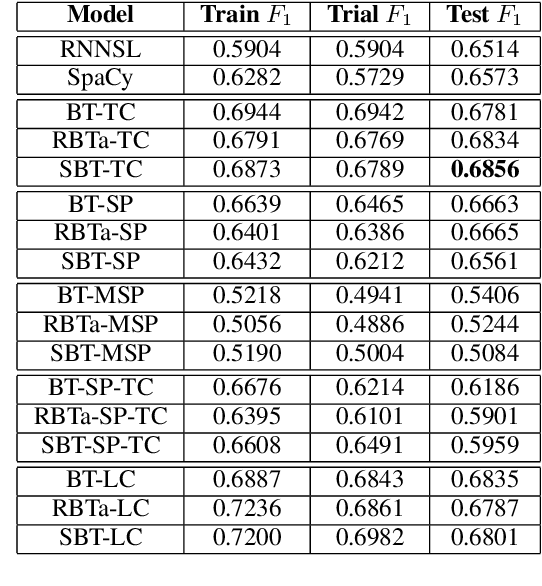


Toxicity detection of text has been a popular NLP task in the recent years. In SemEval-2021 Task-5 Toxic Spans Detection, the focus is on detecting toxic spans within passages. Most state-of-the-art span detection approaches employ various techniques, each of which can be broadly classified into Token Classification or Span Prediction approaches. In our paper, we explore simple versions of both of these approaches and their performance on the task. Specifically, we use BERT-based models -- BERT, RoBERTa, and SpanBERT for both approaches. We also combine these approaches and modify them to bring improvements for Toxic Spans prediction. To this end, we investigate results on four hybrid approaches -- Multi-Span, Span+Token, LSTM-CRF, and a combination of predicted offsets using union/intersection. Additionally, we perform a thorough ablative analysis and analyze our observed results. Our best submission -- a combination of SpanBERT Span Predictor and RoBERTa Token Classifier predictions -- achieves an F1 score of 0.6753 on the test set. Our best post-eval F1 score is 0.6895 on intersection of predicted offsets from top-3 RoBERTa Token Classification checkpoints. These approaches improve the performance by 3% on average than those of the shared baseline models -- RNNSL and SpaCy NER.