 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Nature-Inspired Colony of Artificial Intelligence System with Fast, Detailed, and Organized Learner Agents for Enhancing Diversity and Quality
Apr 07, 2025



The concepts of convolutional neural networks (CNNs) and multi-agent systems are two important areas of research in artificial intelligence (AI). In this paper, we present an approach that builds a CNN-based colony of AI agents to serve as a single system and perform multiple tasks (e.g., predictions or classifications) in an environment. The proposed system impersonates the natural environment of a biological system, like an ant colony or a human colony. The proposed colony of AI that is defined as a role-based system uniquely contributes to accomplish tasks in an environment by incorporating AI agents that are fast learners, detailed learners, and organized learners. These learners can enhance their localized learning and their collective decisions as a single system of colony of AI agents. This approach also enhances the diversity and quality of the colony of AI with the help of Genetic Algorithms and their crossover and mutation mechanisms. The evolution of fast, detailed, and organized learners in the colony of AI is achieved by introducing a unique one-to-one mapping between these learners and the pretrained VGG16, VGG19, and ResNet50 models, respectively. This role-based approach creates two parent-AI agents using the AI models through the processes, called the intra- and inter-marriage of AI, so that they can share their learned knowledge (weights and biases) based on a probabilistic rule and produce diversified child-AI agents to perform new tasks. This process will form a colony of AI that consists of families of multi-model and mixture-model AI agents to improve diversity and quality. Simulations show that the colony of AI, built using the VGG16, VGG19, and ResNet50 models, can provide a single system that generates child-AI agents of excellent predictive performance, ranging between 82% and 95% of F1-scores, to make diversified collective and quality decisions on a task.
LDEB -- Label Digitization with Emotion Binarization and Machine Learning for Emotion Recognition in Conversational Dialogues
Jun 03, 2023Emotion recognition in conversations (ERC) is vital to the advancements of conversational AI and its applications. Therefore, the development of an automated ERC model using the concepts of machine learning (ML) would be beneficial. However, the conversational dialogues present a unique problem where each dialogue depicts nested emotions that entangle the association between the emotional feature descriptors and emotion type (or label). This entanglement that can be multiplied with the presence of data paucity is an obstacle for a ML model. To overcome this problem, we proposed a novel approach called Label Digitization with Emotion Binarization (LDEB) that disentangles the twists by utilizing the text normalization and 7-bit digital encoding techniques and constructs a meaningful feature space for a ML model to be trained. We also utilized the publicly available dataset called the FETA-DailyDialog dataset for feature learning and developed a hierarchical ERC model using random forest (RF) and artificial neural network (ANN) classifiers. Simulations showed that the ANN-based ERC model was able to predict emotion with the best accuracy and precision scores of about 74% and 76%, respectively. Simulations also showed that the ANN-model could reach a training accuracy score of about 98% with 60 epochs. On the other hand, the RF-based ERC model was able to predict emotions with the best accuracy and precision scores of about 78% and 75%, respectively.
Facial Emotion Characterization and Detection using Fourier Transform and Machine Learning
Dec 06, 2021



We present a Fourier-based machine learning technique that characterizes and detects facial emotions. The main challenging task in the development of machine learning (ML) models for classifying facial emotions is the detection of accurate emotional features from a set of training samples, and the generation of feature vectors for constructing a meaningful feature space and building ML models. In this paper, we hypothesis that the emotional features are hidden in the frequency domain; hence, they can be captured by leveraging the frequency domain and masking techniques. We also make use of the conjecture that a facial emotions are convoluted with the normal facial features and the other emotional features; however, they carry linearly separable spatial frequencies (we call computational emotional frequencies). Hence, we propose a technique by leveraging fast Fourier transform (FFT) and rectangular narrow-band frequency kernels, and the widely used Yale-Faces image dataset. We test the hypothesis using the performance scores of the random forest (RF) and the artificial neural network (ANN) classifiers as the measures to validate the effectiveness of the captured emotional frequencies. Our finding is that the computational emotional frequencies discovered by the proposed approach provides meaningful emotional features that help RF and ANN achieve a high precision scores above 93%, on average.
NLRG at SemEval-2021 Task 5: Toxic Spans Detection Leveraging BERT-based Token Classification and Span Prediction Techniques
Feb 24, 2021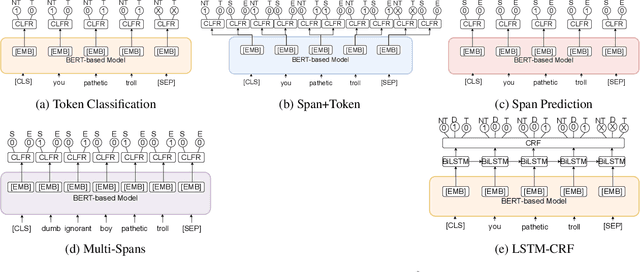
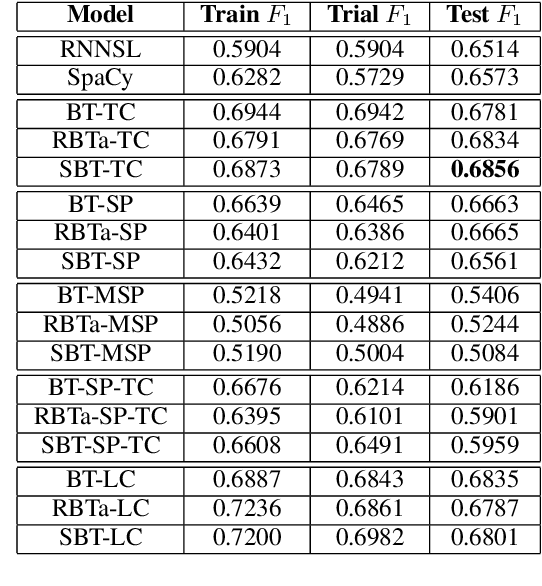


Toxicity detection of text has been a popular NLP task in the recent years. In SemEval-2021 Task-5 Toxic Spans Detection, the focus is on detecting toxic spans within passages. Most state-of-the-art span detection approaches employ various techniques, each of which can be broadly classified into Token Classification or Span Prediction approaches. In our paper, we explore simple versions of both of these approaches and their performance on the task. Specifically, we use BERT-based models -- BERT, RoBERTa, and SpanBERT for both approaches. We also combine these approaches and modify them to bring improvements for Toxic Spans prediction. To this end, we investigate results on four hybrid approaches -- Multi-Span, Span+Token, LSTM-CRF, and a combination of predicted offsets using union/intersection. Additionally, we perform a thorough ablative analysis and analyze our observed results. Our best submission -- a combination of SpanBERT Span Predictor and RoBERTa Token Classifier predictions -- achieves an F1 score of 0.6753 on the test set. Our best post-eval F1 score is 0.6895 on intersection of predicted offsets from top-3 RoBERTa Token Classification checkpoints. These approaches improve the performance by 3% on average than those of the shared baseline models -- RNNSL and SpaCy NER.
A fatal point concept and a low-sensitivity quantitative measure for traffic safety analytics
Nov 28, 2017

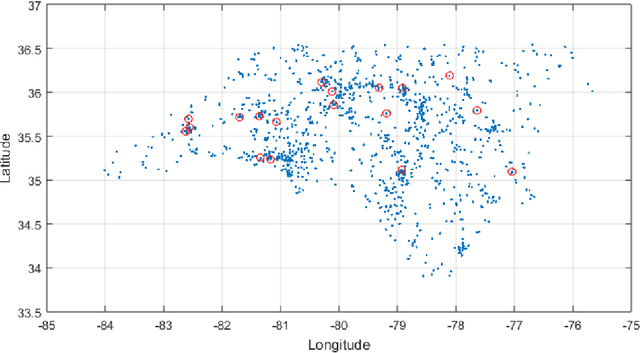

The variability of the clusters generated by clustering techniques in the domain of latitude and longitude variables of fatal crash data are significantly unpredictable. This unpredictability, caused by the randomness of fatal crash incidents, reduces the accuracy of crash frequency (i.e., counts of fatal crashes per cluster) which is used to measure traffic safety in practice. In this paper, a quantitative measure of traffic safety that is not significantly affected by the aforementioned variability is proposed. It introduces a fatal point -- a segment with the highest frequency of fatality -- concept based on cluster characteristics and detects them by imposing rounding errors to the hundredth decimal place of the longitude. The frequencies of the cluster and the cluster's fatal point are combined to construct a low-sensitive quantitative measure of traffic safety for the cluster. The performance of the proposed measure of traffic safety is then studied by varying the parameter k of k-means clustering with the expectation that other clustering techniques can be adopted in a similar fashion. The 2015 North Carolina fatal crash dataset of Fatality Analysis Reporting System (FARS) is used to evaluate the proposed fatal point concept and perform experimental analysis to determine the effectiveness of the proposed measure. The empirical study shows that the average traffic safety, measured by the proposed quantitative measure over several clusters, is not significantly affected by the variability, compared to that of the standard crash frequency.
Elliptical modeling and pattern analysis for perturbation models and classfication
Oct 22, 2017
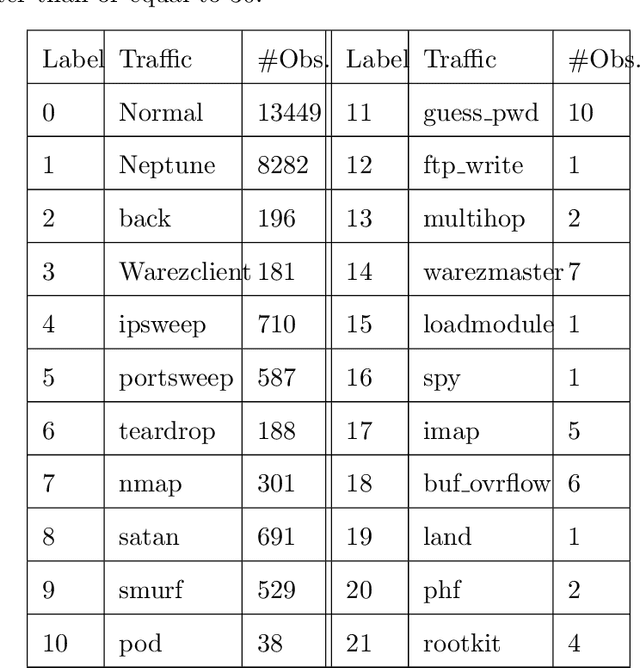


The characteristics (or numerical patterns) of a feature vector in the transform domain of a perturbation model differ significantly from those of its corresponding feature vector in the input domain. These differences - caused by the perturbation techniques used for the transformation of feature patterns - degrade the performance of machine learning techniques in the transform domain. In this paper, we proposed a nonlinear parametric perturbation model that transforms the input feature patterns to a set of elliptical patterns, and studied the performance degradation issues associated with random forest classification technique using both the input and transform domain features. Compared with the linear transformation such as Principal Component Analysis (PCA), the proposed method requires less statistical assumptions and is highly suitable for the applications such as data privacy and security due to the difficulty of inverting the elliptical patterns from the transform domain to the input domain. In addition, we adopted a flexible block-wise dimensionality reduction step in the proposed method to accommodate the possible high-dimensional data in modern applications. We evaluated the empirical performance of the proposed method on a network intrusion data set and a biological data set, and compared the results with PCA in terms of classification performance and data privacy protection (measured by the blind source separation attack and signal interference ratio). Both results confirmed the superior performance of the proposed elliptical transformation.