 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElliptical modeling and pattern analysis for perturbation models and classfication
Paper and Code
Oct 22, 2017
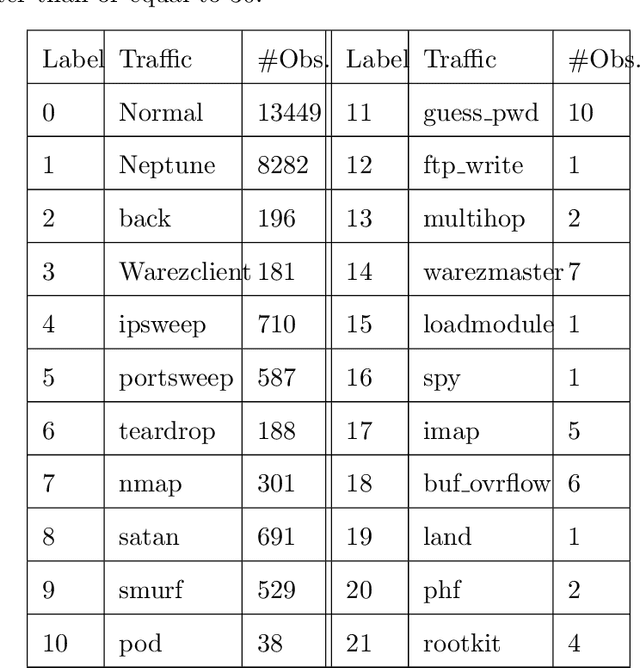


The characteristics (or numerical patterns) of a feature vector in the transform domain of a perturbation model differ significantly from those of its corresponding feature vector in the input domain. These differences - caused by the perturbation techniques used for the transformation of feature patterns - degrade the performance of machine learning techniques in the transform domain. In this paper, we proposed a nonlinear parametric perturbation model that transforms the input feature patterns to a set of elliptical patterns, and studied the performance degradation issues associated with random forest classification technique using both the input and transform domain features. Compared with the linear transformation such as Principal Component Analysis (PCA), the proposed method requires less statistical assumptions and is highly suitable for the applications such as data privacy and security due to the difficulty of inverting the elliptical patterns from the transform domain to the input domain. In addition, we adopted a flexible block-wise dimensionality reduction step in the proposed method to accommodate the possible high-dimensional data in modern applications. We evaluated the empirical performance of the proposed method on a network intrusion data set and a biological data set, and compared the results with PCA in terms of classification performance and data privacy protection (measured by the blind source separation attack and signal interference ratio). Both results confirmed the superior performance of the proposed elliptical transformation.