 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Semantic Grounding in Language Models of Code with Representational Similarity Analysis
Jul 15, 2022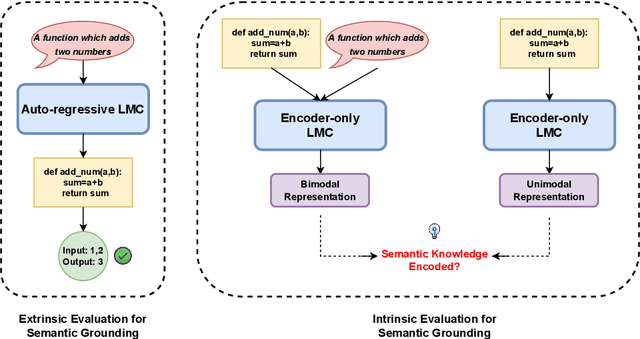

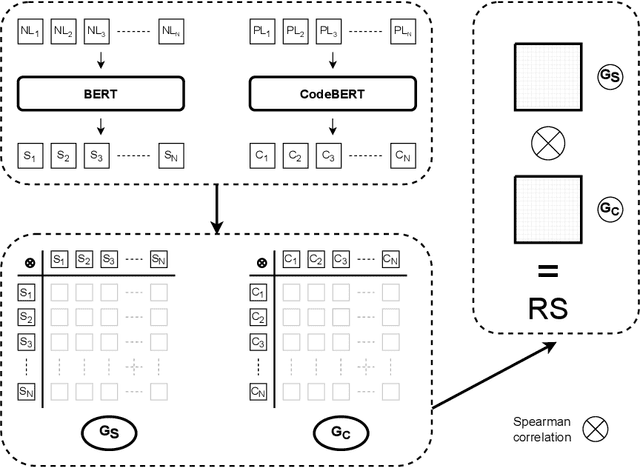
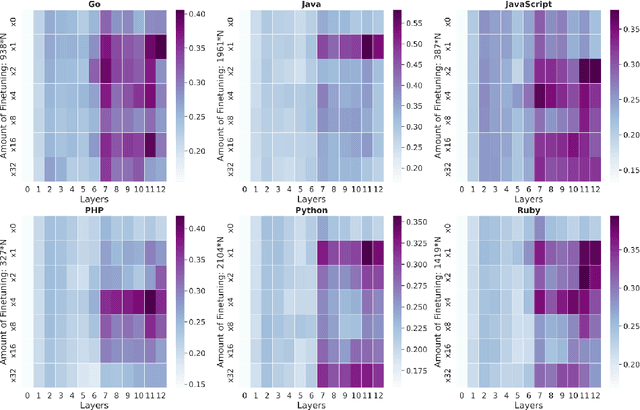
Representational Similarity Analysis is a method from cognitive neuroscience, which helps in comparing representations from two different sources of data. In this paper, we propose using Representational Similarity Analysis to probe the semantic grounding in language models of code. We probe representations from the CodeBERT model for semantic grounding by using the data from the IBM CodeNet dataset. Through our experiments, we show that current pre-training methods do not induce semantic grounding in language models of code, and instead focus on optimizing form-based patterns. We also show that even a little amount of fine-tuning on semantically relevant tasks increases the semantic grounding in CodeBERT significantly. Our ablations with the input modality to the CodeBERT model show that using bimodal inputs (code and natural language) over unimodal inputs (only code) gives better semantic grounding and sample efficiency during semantic fine-tuning. Finally, our experiments with semantic perturbations in code reveal that CodeBERT is able to robustly distinguish between semantically correct and incorrect code.
DRIFT: A Toolkit for Diachronic Analysis of Scientific Literature
Jul 16, 2021
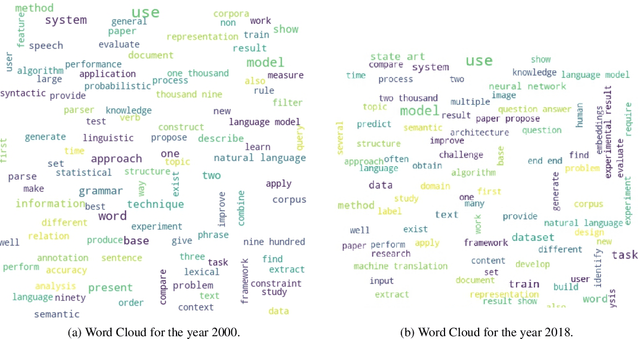


In this work, we present to the NLP community, and to the wider research community as a whole, an application for the diachronic analysis of research corpora. We open source an easy-to-use tool coined: DRIFT, which allows researchers to track research trends and development over the years. The analysis methods are collated from well-cited research works, with a few of our own methods added for good measure. Succinctly put, some of the analysis methods are: keyword extraction, word clouds, predicting declining/stagnant/growing trends using Productivity, tracking bi-grams using Acceleration plots, finding the Semantic Drift of words, tracking trends using similarity, etc. To demonstrate the utility and efficacy of our tool, we perform a case study on the cs.CL corpus of the arXiv repository and draw inferences from the analysis methods. The toolkit and the associated code are available here: https://github.com/rajaswa/DRIFT.
Using Diachronic Distributed Word Representations as Models of Lexical Development in Children
May 11, 2021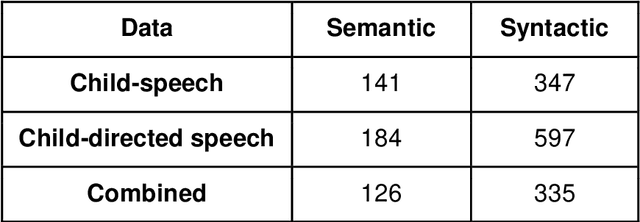
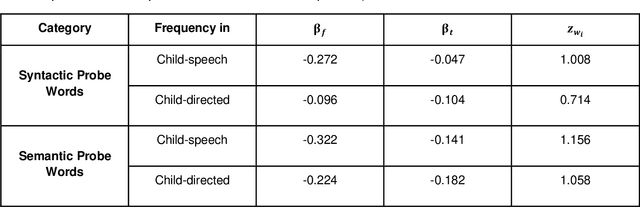
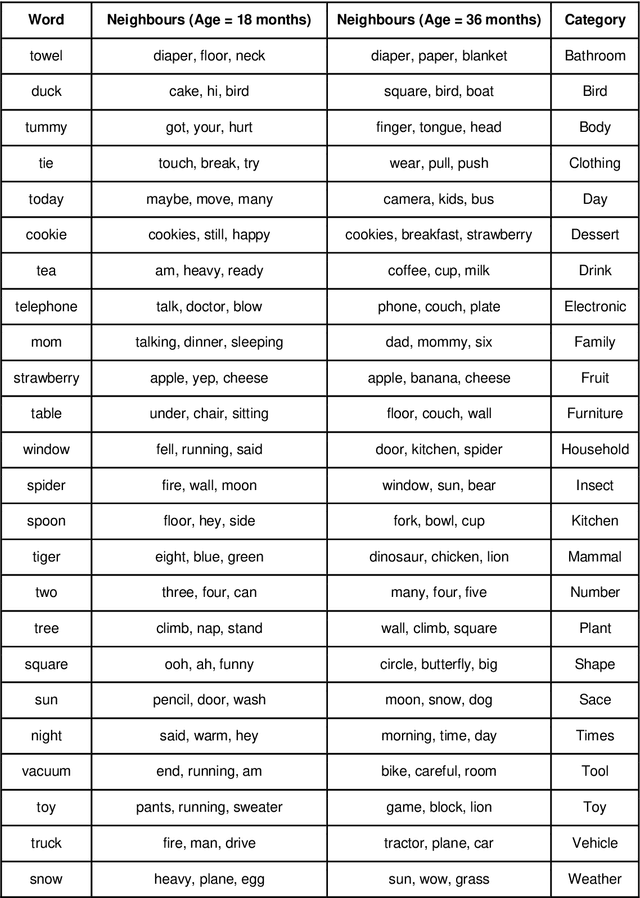

Recent work has shown that distributed word representations can encode abstract semantic and syntactic information from child-directed speech. In this paper, we use diachronic distributed word representations to perform temporal modeling and analysis of lexical development in children. Unlike all previous work, we use temporally sliced speech corpus to learn distributed word representations of child and child-directed speech. Through our modeling experiments, we demonstrate the dynamics of growing lexical knowledge in children over time, as compared against a saturated level of lexical knowledge in child-directed adult speech. We also fit linear mixed-effects models with the rate of semantic change in the diachronic representations and word frequencies. This allows us to inspect the role of word frequencies towards lexical development in children. Further, we perform a qualitative analysis of the diachronic representations from our model, which reveals the categorization and word associations in the mental lexicon of children.
Vyākarana: A Colorless Green Benchmark for Syntactic Evaluation in Indic Languages
Mar 01, 2021


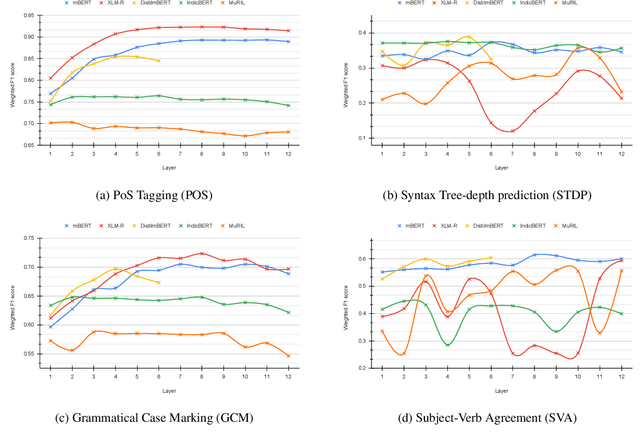
While there has been significant progress towards developing NLU datasets and benchmarks for Indic languages, syntactic evaluation has been relatively less explored. Unlike English, Indic languages have rich morphosyntax, grammatical genders, free linear word-order, and highly inflectional morphology. In this paper, we introduce Vy\=akarana: a benchmark of gender-balanced Colorless Green sentences in Indic languages for syntactic evaluation of multilingual language models. The benchmark comprises four syntax-related tasks: PoS Tagging, Syntax Tree-depth Prediction, Grammatical Case Marking, and Subject-Verb Agreement. We use the datasets from the evaluation tasks to probe five multilingual language models of varying architectures for syntax in Indic languages. Our results show that the token-level and sentence-level representations from the Indic language models (IndicBERT and MuRIL) do not capture the syntax in Indic languages as efficiently as the other highly multilingual language models. Further, our layer-wise probing experiments reveal that while mBERT, DistilmBERT, and XLM-R localize the syntax in middle layers, the Indic language models do not show such syntactic localization.
Towards Modelling Coherence in Spoken Discourse
Dec 31, 2020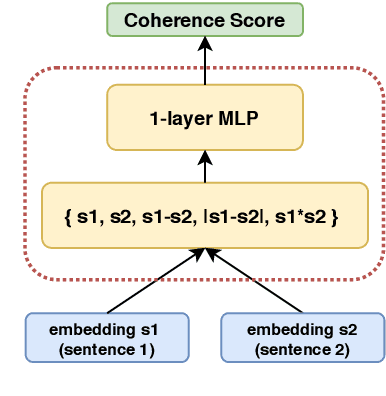
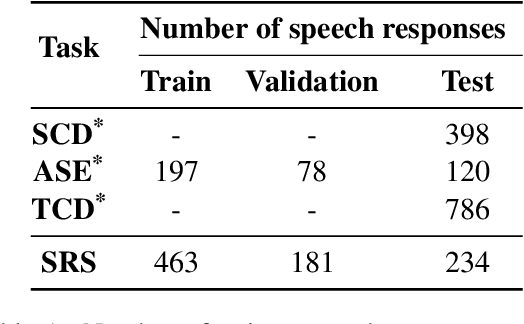
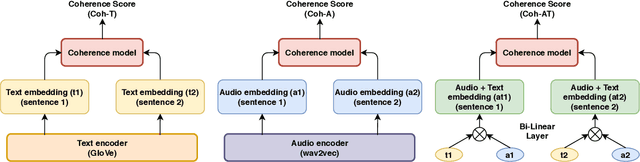
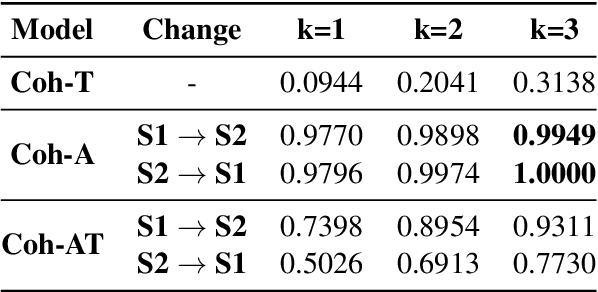
While there has been significant progress towards modelling coherence in written discourse, the work in modelling spoken discourse coherence has been quite limited. Unlike the coherence in text, coherence in spoken discourse is also dependent on the prosodic and acoustic patterns in speech. In this paper, we model coherence in spoken discourse with audio-based coherence models. We perform experiments with four coherence-related tasks with spoken discourses. In our experiments, we evaluate machine-generated speech against the speech delivered by expert human speakers. We also compare the spoken discourses generated by human language learners of varying language proficiency levels. Our results show that incorporating the audio modality along with the text benefits the coherence models in performing downstream coherence related tasks with spoken discourses.
CNRL at SemEval-2020 Task 5: Modelling Causal Reasoning in Language with Multi-Head Self-Attention Weights based Counterfactual Detection
May 31, 2020



In this paper, we describe an approach for modelling causal reasoning in natural language by detecting counterfactuals in text using multi-head self-attention weights. We use pre-trained transformer models to extract contextual embeddings and self-attention weights from the text. We show the use of convolutional layers to extract task-specific features from these self-attention weights. Further, we describe a fine-tuning approach with a common base model for knowledge sharing between the two closely related sub-tasks for counterfactual detection. We analyze and compare the performance of various transformer models in our experiments. Finally, we perform a qualitative analysis with the multi-head self-attention weights to interpret our models' dynamics.
LRG at SemEval-2020 Task 7: Assessing the Ability of BERT and Derivative Models to Perform Short-Edits based Humor Grading
May 31, 2020

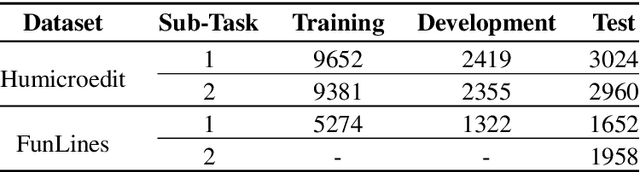

In this paper, we assess the ability of BERT and its derivative models (RoBERTa, DistilBERT, and ALBERT) for short-edits based humor grading. We test these models for humor grading and classification tasks on the Humicroedit and the FunLines dataset. We perform extensive experiments with these models to test their language modeling and generalization abilities via zero-shot inference and cross-dataset inference based approaches. Further, we also inspect the role of self-attention layers in humor-grading by performing a qualitative analysis over the self-attention weights from the final layer of the trained BERT model. Our experiments show that all the pre-trained BERT derivative models show significant generalization capabilities for humor-grading related tasks.
BPGC at SemEval-2020 Task 11: Propaganda Detection in News Articles with Multi-Granularity Knowledge Sharing and Linguistic Features based Ensemble Learning
May 31, 2020
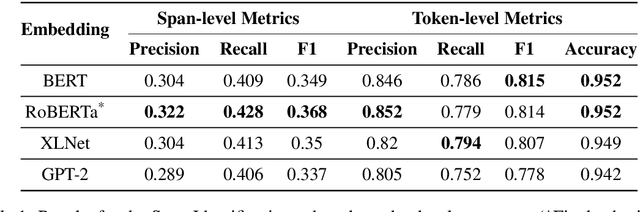
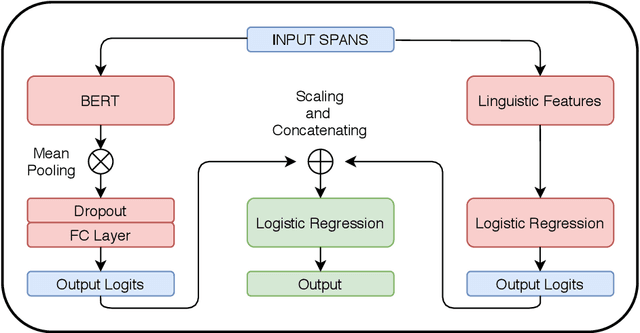
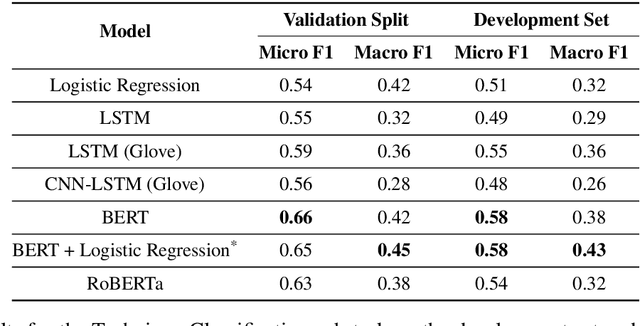
Propaganda spreads the ideology and beliefs of like-minded people, brainwashing their audiences, and sometimes leading to violence. SemEval 2020 Task-11 aims to design automated systems for news propaganda detection. Task-11 consists of two sub-tasks, namely, Span Identification - given any news article, the system tags those specific fragments which contain at least one propaganda technique; and Technique Classification - correctly classify a given propagandist statement amongst 14 propaganda techniques. For sub-task 1, we use contextual embeddings extracted from pre-trained transformer models to represent the text data at various granularities and propose a multi-granularity knowledge sharing approach. For sub-task 2, we use an ensemble of BERT and logistic regression classifiers with linguistic features. Our results reveal that the linguistic features are the strong indicators for covering minority classes in a highly imbalanced dataset.