 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Speech Scoring System Under The Lens: Evaluating and interpreting the linguistic cues for language proficiency
Nov 30, 2021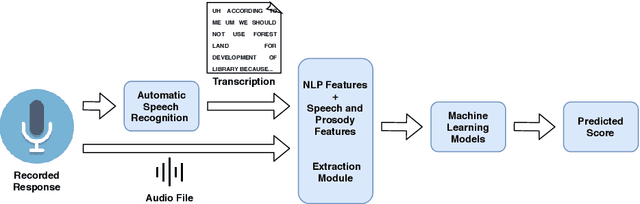
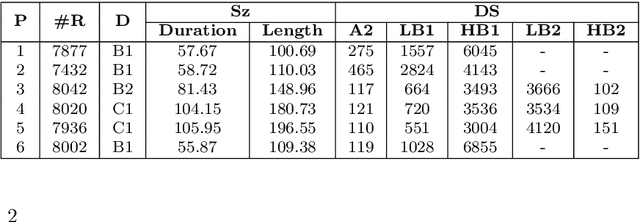
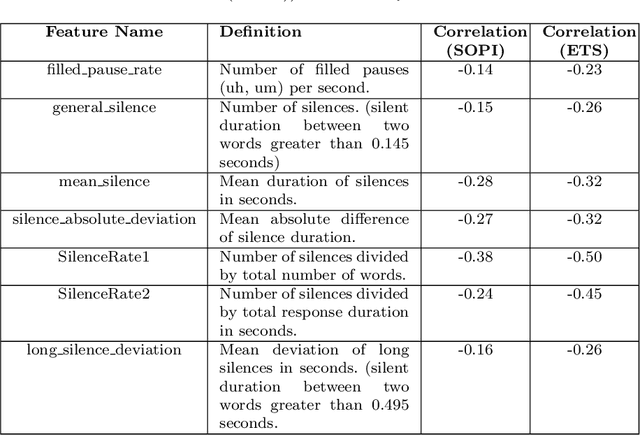
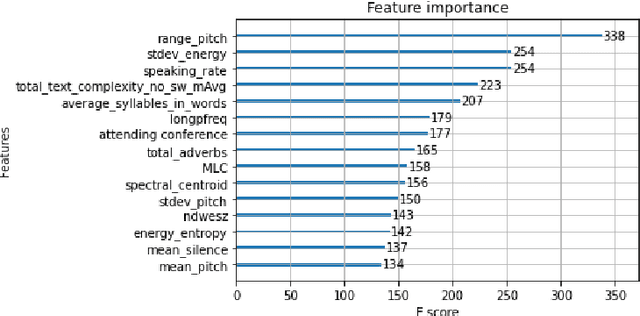
English proficiency assessments have become a necessary metric for filtering and selecting prospective candidates for both academia and industry. With the rise in demand for such assessments, it has become increasingly necessary to have the automated human-interpretable results to prevent inconsistencies and ensure meaningful feedback to the second language learners. Feature-based classical approaches have been more interpretable in understanding what the scoring model learns. Therefore, in this work, we utilize classical machine learning models to formulate a speech scoring task as both a classification and a regression problem, followed by a thorough study to interpret and study the relation between the linguistic cues and the English proficiency level of the speaker. First, we extract linguist features under five categories (fluency, pronunciation, content, grammar and vocabulary, and acoustic) and train models to grade responses. In comparison, we find that the regression-based models perform equivalent to or better than the classification approach. Second, we perform ablation studies to understand the impact of each of the feature and feature categories on the performance of proficiency grading. Further, to understand individual feature contributions, we present the importance of top features on the best performing algorithm for the grading task. Third, we make use of Partial Dependence Plots and Shapley values to explore feature importance and conclude that the best performing trained model learns the underlying rubrics used for grading the dataset used in this study.
Towards Modelling Coherence in Spoken Discourse
Dec 31, 2020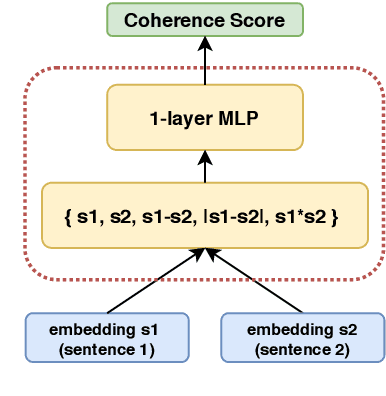
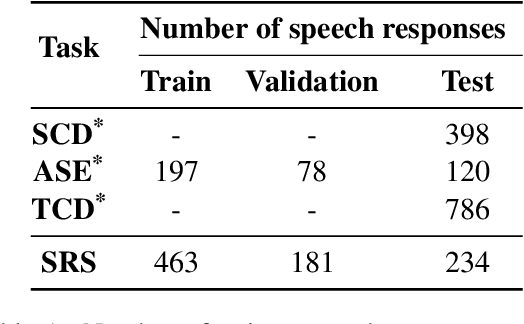
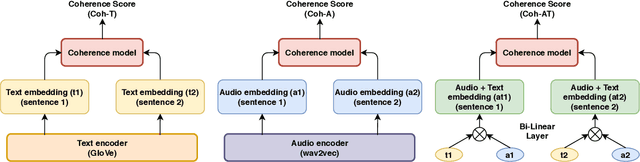
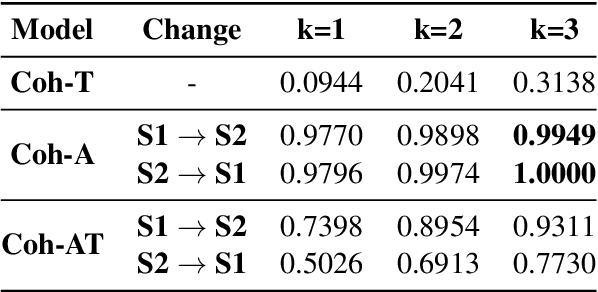
While there has been significant progress towards modelling coherence in written discourse, the work in modelling spoken discourse coherence has been quite limited. Unlike the coherence in text, coherence in spoken discourse is also dependent on the prosodic and acoustic patterns in speech. In this paper, we model coherence in spoken discourse with audio-based coherence models. We perform experiments with four coherence-related tasks with spoken discourses. In our experiments, we evaluate machine-generated speech against the speech delivered by expert human speakers. We also compare the spoken discourses generated by human language learners of varying language proficiency levels. Our results show that incorporating the audio modality along with the text benefits the coherence models in performing downstream coherence related tasks with spoken discourses.
audino: A Modern Annotation Tool for Audio and Speech
Jun 09, 2020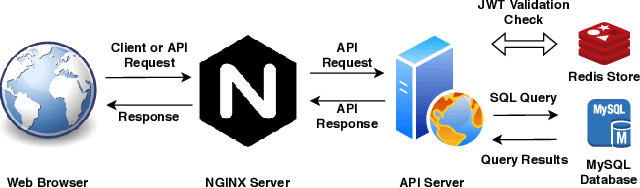
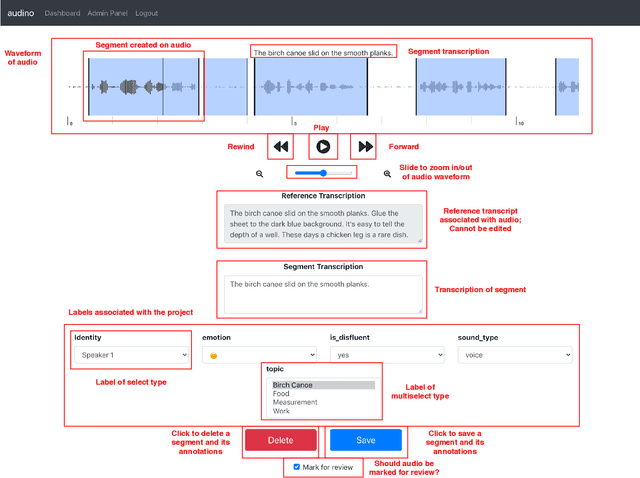
In this paper, we introduce a collaborative and modern annotation tool for audio and speech: audino. The tool allows annotators to define and describe temporal segmentation in audios. These segments can be labelled and transcribed easily using a dynamically generated form. An admin can centrally control user roles and project assignment through the admin dashboard. The dashboard also enables describing labels and their values. The annotations can easily be exported in JSON format for further processing. The tool allows audio data to be uploaded and assigned to a user through a key-based API. The flexibility available in the annotation tool enables annotation for Speech Scoring, Voice Activity Detection (VAD), Speaker Diarisation, Speaker Identification, Speech Recognition, Emotion Recognition tasks and more. The MIT open source license allows it to be used for academic and commercial projects.
Multi-modal Automated Speech Scoring using Attention Fusion
May 17, 2020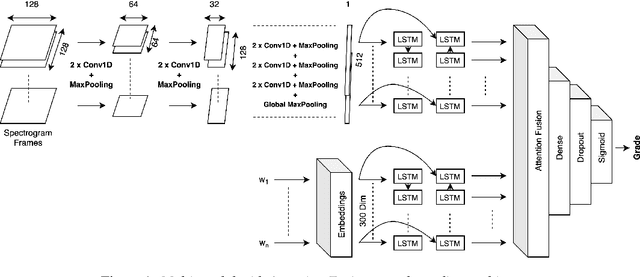

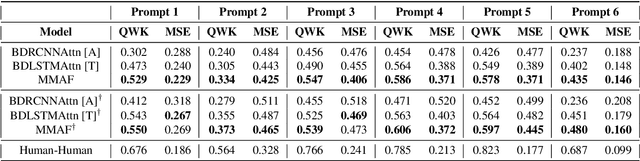

In this study, we propose a novel multi-modal end-to-end neural approach for automated assessment of non-native English speakers' spontaneous speech using attention fusion. The pipeline employs Bi-directional Recurrent Convolutional Neural Networks and Bi-directional Long Short-Term Memory Neural Networks to encode acoustic and lexical cues from spectrograms and transcriptions, respectively. Attention fusion is performed on these learned predictive features to learn complex interactions between different modalities before final scoring. We compare our model with strong baselines and find combined attention to both lexical and acoustic cues significantly improves the overall performance of the system. Further, we present a qualitative and quantitative analysis of our model.