 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Speech Scoring System Under The Lens: Evaluating and interpreting the linguistic cues for language proficiency
Nov 30, 2021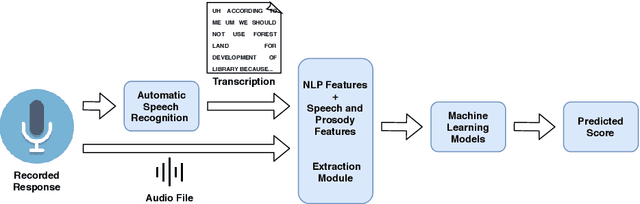
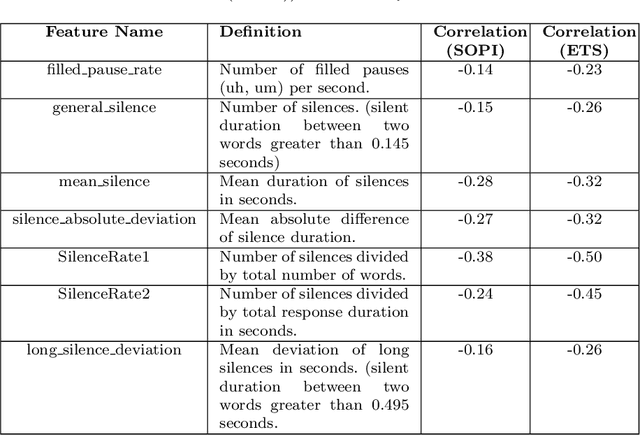
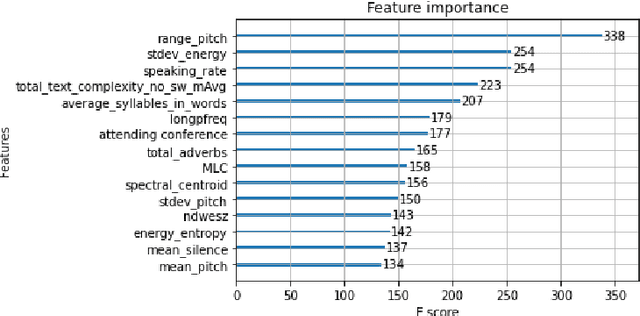
English proficiency assessments have become a necessary metric for filtering and selecting prospective candidates for both academia and industry. With the rise in demand for such assessments, it has become increasingly necessary to have the automated human-interpretable results to prevent inconsistencies and ensure meaningful feedback to the second language learners. Feature-based classical approaches have been more interpretable in understanding what the scoring model learns. Therefore, in this work, we utilize classical machine learning models to formulate a speech scoring task as both a classification and a regression problem, followed by a thorough study to interpret and study the relation between the linguistic cues and the English proficiency level of the speaker. First, we extract linguist features under five categories (fluency, pronunciation, content, grammar and vocabulary, and acoustic) and train models to grade responses. In comparison, we find that the regression-based models perform equivalent to or better than the classification approach. Second, we perform ablation studies to understand the impact of each of the feature and feature categories on the performance of proficiency grading. Further, to understand individual feature contributions, we present the importance of top features on the best performing algorithm for the grading task. Third, we make use of Partial Dependence Plots and Shapley values to explore feature importance and conclude that the best performing trained model learns the underlying rubrics used for grading the dataset used in this study.
N-Best ASR Transformer: Enhancing SLU Performance using Multiple ASR Hypotheses
Jun 11, 2021
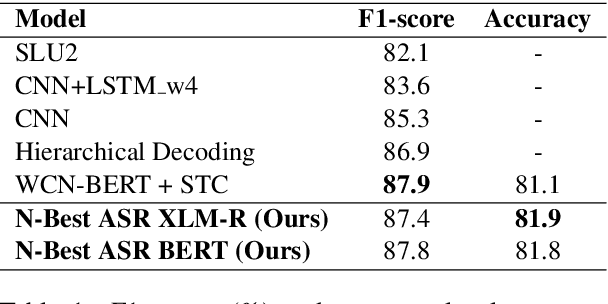
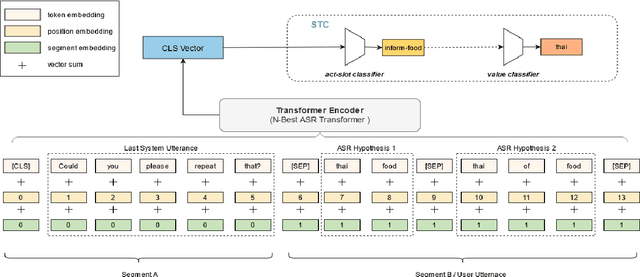
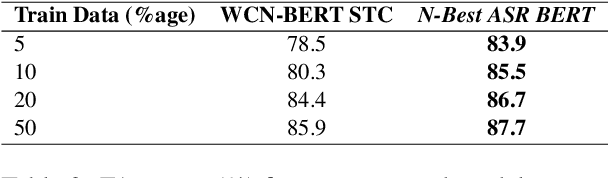
Spoken Language Understanding (SLU) systems parse speech into semantic structures like dialog acts and slots. This involves the use of an Automatic Speech Recognizer (ASR) to transcribe speech into multiple text alternatives (hypotheses). Transcription errors, common in ASRs, impact downstream SLU performance negatively. Approaches to mitigate such errors involve using richer information from the ASR, either in form of N-best hypotheses or word-lattices. We hypothesize that transformer models learn better with a simpler utterance representation using the concatenation of the N-best ASR alternatives, where each alternative is separated by a special delimiter [SEP]. In our work, we test our hypothesis by using concatenated N-best ASR alternatives as the input to transformer encoder models, namely BERT and XLM-RoBERTa, and achieve performance equivalent to the prior state-of-the-art model on DSTC2 dataset. We also show that our approach significantly outperforms the prior state-of-the-art when subjected to the low data regime. Additionally, this methodology is accessible to users of third-party ASR APIs which do not provide word-lattice information.
audino: A Modern Annotation Tool for Audio and Speech
Jun 09, 2020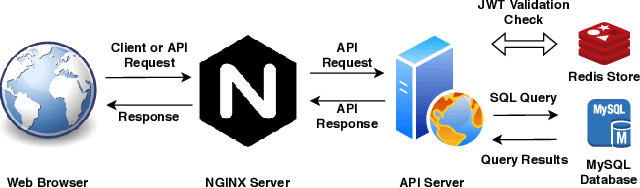
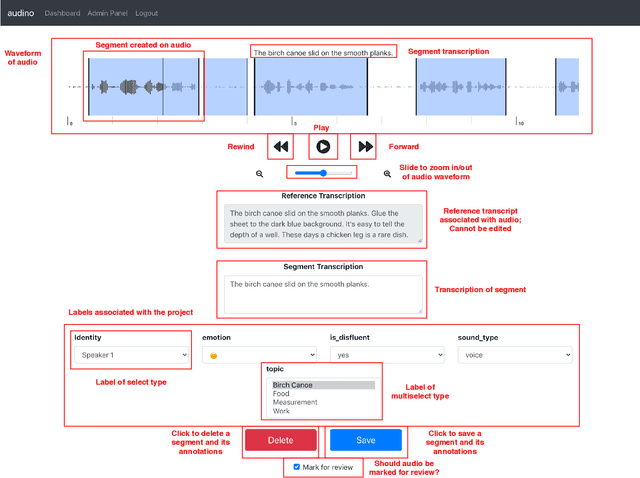
In this paper, we introduce a collaborative and modern annotation tool for audio and speech: audino. The tool allows annotators to define and describe temporal segmentation in audios. These segments can be labelled and transcribed easily using a dynamically generated form. An admin can centrally control user roles and project assignment through the admin dashboard. The dashboard also enables describing labels and their values. The annotations can easily be exported in JSON format for further processing. The tool allows audio data to be uploaded and assigned to a user through a key-based API. The flexibility available in the annotation tool enables annotation for Speech Scoring, Voice Activity Detection (VAD), Speaker Diarisation, Speaker Identification, Speech Recognition, Emotion Recognition tasks and more. The MIT open source license allows it to be used for academic and commercial projects.