 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVyākarana: A Colorless Green Benchmark for Syntactic Evaluation in Indic Languages
Mar 01, 2021


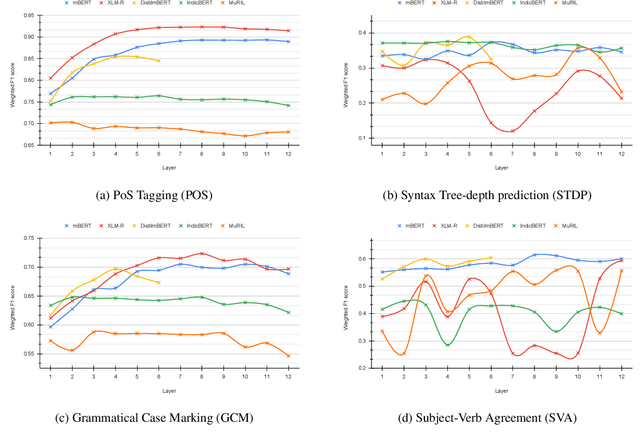
While there has been significant progress towards developing NLU datasets and benchmarks for Indic languages, syntactic evaluation has been relatively less explored. Unlike English, Indic languages have rich morphosyntax, grammatical genders, free linear word-order, and highly inflectional morphology. In this paper, we introduce Vy\=akarana: a benchmark of gender-balanced Colorless Green sentences in Indic languages for syntactic evaluation of multilingual language models. The benchmark comprises four syntax-related tasks: PoS Tagging, Syntax Tree-depth Prediction, Grammatical Case Marking, and Subject-Verb Agreement. We use the datasets from the evaluation tasks to probe five multilingual language models of varying architectures for syntax in Indic languages. Our results show that the token-level and sentence-level representations from the Indic language models (IndicBERT and MuRIL) do not capture the syntax in Indic languages as efficiently as the other highly multilingual language models. Further, our layer-wise probing experiments reveal that while mBERT, DistilmBERT, and XLM-R localize the syntax in middle layers, the Indic language models do not show such syntactic localization.
LRG at SemEval-2020 Task 7: Assessing the Ability of BERT and Derivative Models to Perform Short-Edits based Humor Grading
May 31, 2020

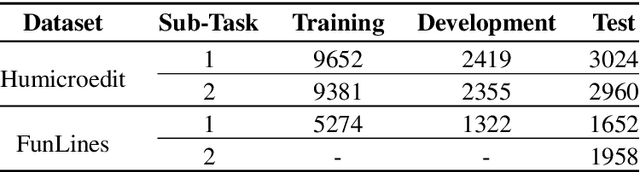

In this paper, we assess the ability of BERT and its derivative models (RoBERTa, DistilBERT, and ALBERT) for short-edits based humor grading. We test these models for humor grading and classification tasks on the Humicroedit and the FunLines dataset. We perform extensive experiments with these models to test their language modeling and generalization abilities via zero-shot inference and cross-dataset inference based approaches. Further, we also inspect the role of self-attention layers in humor-grading by performing a qualitative analysis over the self-attention weights from the final layer of the trained BERT model. Our experiments show that all the pre-trained BERT derivative models show significant generalization capabilities for humor-grading related tasks.