 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaplacian Representations for Decision-Time Planning
Feb 04, 2026Planning with a learned model remains a key challenge in model-based reinforcement learning (RL). In decision-time planning, state representations are critical as they must support local cost computation while preserving long-horizon structure. In this paper, we show that the Laplacian representation provides an effective latent space for planning by capturing state-space distances at multiple time scales. This representation preserves meaningful distances and naturally decomposes long-horizon problems into subgoals, also mitigating the compounding errors that arise over long prediction horizons. Building on these properties, we introduce ALPS, a hierarchical planning algorithm, and demonstrate that it outperforms commonly used baselines on a selection of offline goal-conditioned RL tasks from OGBench, a benchmark previously dominated by model-free methods.
Human-like Bots for Tactical Shooters Using Compute-Efficient Sensors
Dec 30, 2024



Artificial intelligence (AI) has enabled agents to master complex video games, from first-person shooters like Counter-Strike to real-time strategy games such as StarCraft II and racing games like Gran Turismo. While these achievements are notable, applying these AI methods in commercial video game production remains challenging due to computational constraints. In commercial scenarios, the majority of computational resources are allocated to 3D rendering, leaving limited capacity for AI methods, which often demand high computational power, particularly those relying on pixel-based sensors. Moreover, the gaming industry prioritizes creating human-like behavior in AI agents to enhance player experience, unlike academic models that focus on maximizing game performance. This paper introduces a novel methodology for training neural networks via imitation learning to play a complex, commercial-standard, VALORANT-like 2v2 tactical shooter game, requiring only modest CPU hardware during inference. Our approach leverages an innovative, pixel-free perception architecture using a small set of ray-cast sensors, which capture essential spatial information efficiently. These sensors allow AI to perform competently without the computational overhead of traditional methods. Models are trained to mimic human behavior using supervised learning on human trajectory data, resulting in realistic and engaging AI agents. Human evaluation tests confirm that our AI agents provide human-like gameplay experiences while operating efficiently under computational constraints. This offers a significant advancement in AI model development for tactical shooter games and possibly other genres.
Continual Auxiliary Task Learning
Feb 22, 2022
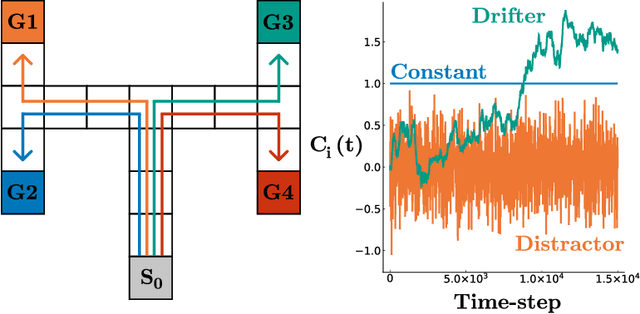
Learning auxiliary tasks, such as multiple predictions about the world, can provide many benefits to reinforcement learning systems. A variety of off-policy learning algorithms have been developed to learn such predictions, but as yet there is little work on how to adapt the behavior to gather useful data for those off-policy predictions. In this work, we investigate a reinforcement learning system designed to learn a collection of auxiliary tasks, with a behavior policy learning to take actions to improve those auxiliary predictions. We highlight the inherent non-stationarity in this continual auxiliary task learning problem, for both prediction learners and the behavior learner. We develop an algorithm based on successor features that facilitates tracking under non-stationary rewards, and prove the separation into learning successor features and rewards provides convergence rate improvements. We conduct an in-depth study into the resulting multi-prediction learning system.
Meta-descent for Online, Continual Prediction
Jul 17, 2019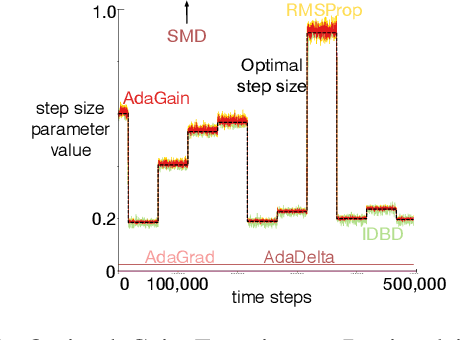
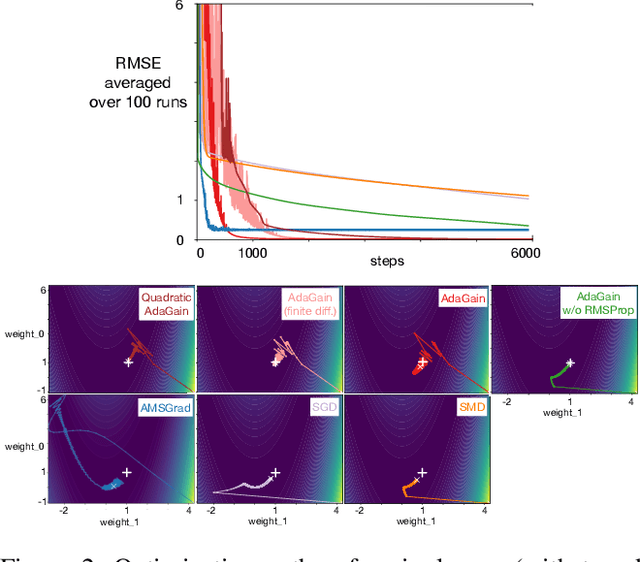
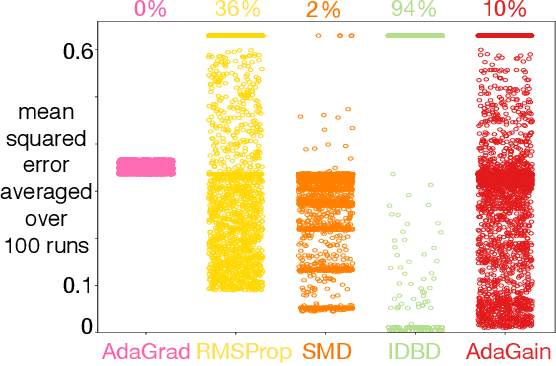
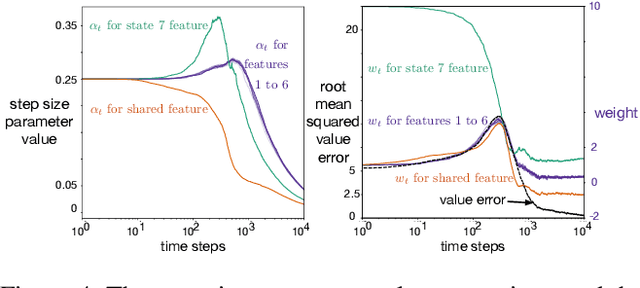
This paper investigates different vector step-size adaptation approaches for non-stationary online, continual prediction problems. Vanilla stochastic gradient descent can be considerably improved by scaling the update with a vector of appropriately chosen step-sizes. Many methods, including AdaGrad, RMSProp, and AMSGrad, keep statistics about the learning process to approximate a second order update---a vector approximation of the inverse Hessian. Another family of approaches use meta-gradient descent to adapt the step-size parameters to minimize prediction error. These meta-descent strategies are promising for non-stationary problems, but have not been as extensively explored as quasi-second order methods. We first derive a general, incremental meta-descent algorithm, called AdaGain, designed to be applicable to a much broader range of algorithms, including those with semi-gradient updates or even those with accelerations, such as RMSProp. We provide an empirical comparison of methods from both families. We conclude that methods from both families can perform well, but in non-stationary prediction problems the meta-descent methods exhibit advantages. Our method is particularly robust across several prediction problems, and is competitive with the state-of-the-art method on a large-scale, time-series prediction problem on real data from a mobile robot.
Importance Resampling for Off-policy Prediction
Jun 11, 2019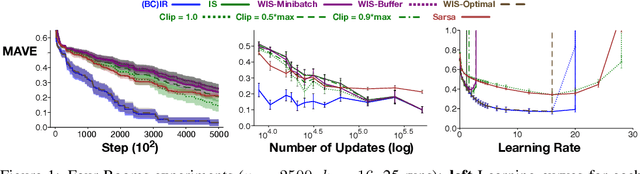
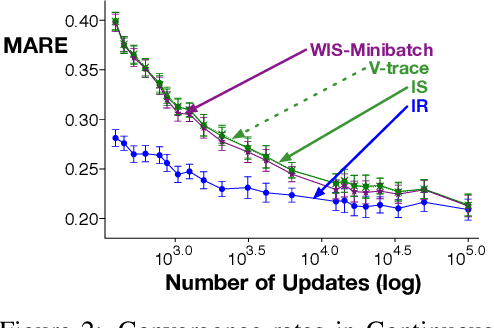
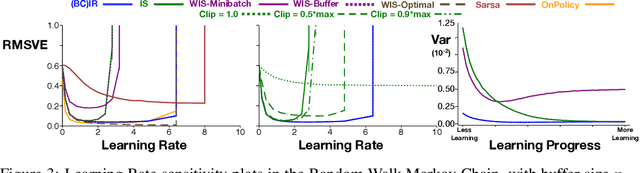
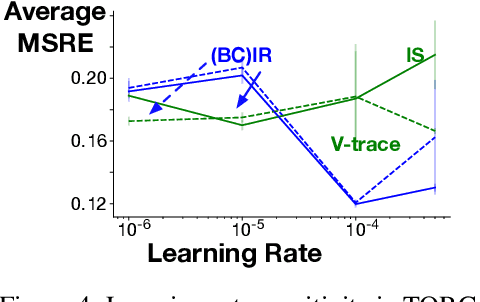
Importance sampling (IS) is a common reweighting strategy for off-policy prediction in reinforcement learning. While it is consistent and unbiased, it can result in high variance updates to the weights for the value function. In this work, we explore a resampling strategy as an alternative to reweighting. We propose Importance Resampling (IR) for off-policy prediction, which resamples experience from a replay buffer and applies standard on-policy updates. The approach avoids using importance sampling ratios in the update, instead correcting the distribution before the update. We characterize the bias and consistency of IR, particularly compared to Weighted IS (WIS). We demonstrate in several microworlds that IR has improved sample efficiency and lower variance updates, as compared to IS and several variance-reduced IS strategies, including variants of WIS and V-trace which clips IS ratios. We also provide a demonstration showing IR improves over IS for learning a value function from images in a racing car simulator.
Context-Dependent Upper-Confidence Bounds for Directed Exploration
Nov 15, 2018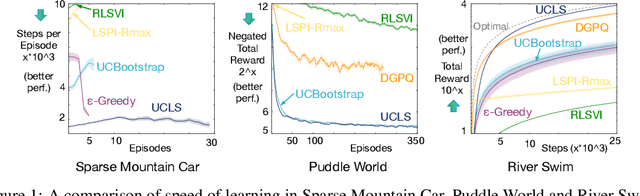
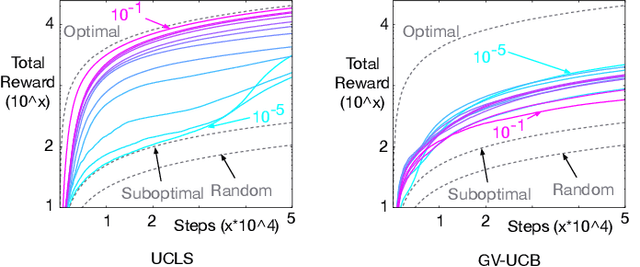
Directed exploration strategies for reinforcement learning are critical for learning an optimal policy in a minimal number of interactions with the environment. Many algorithms use optimism to direct exploration, either through visitation estimates or upper confidence bounds, as opposed to data-inefficient strategies like \epsilon-greedy that use random, undirected exploration. Most data-efficient exploration methods require significant computation, typically relying on a learned model to guide exploration. Least-squares methods have the potential to provide some of the data-efficiency benefits of model-based approaches -- because they summarize past interactions -- with the computation closer to that of model-free approaches. In this work, we provide a novel, computationally efficient, incremental exploration strategy, leveraging this property of least-squares temporal difference learning (LSTD). We derive upper confidence bounds on the action-values learned by LSTD, with context-dependent (or state-dependent) noise variance. Such context-dependent noise focuses exploration on a subset of variable states, and allows for reduced exploration in other states. We empirically demonstrate that our algorithm can converge more quickly than other incremental exploration strategies using confidence estimates on action-values.
General Value Function Networks
Jul 18, 2018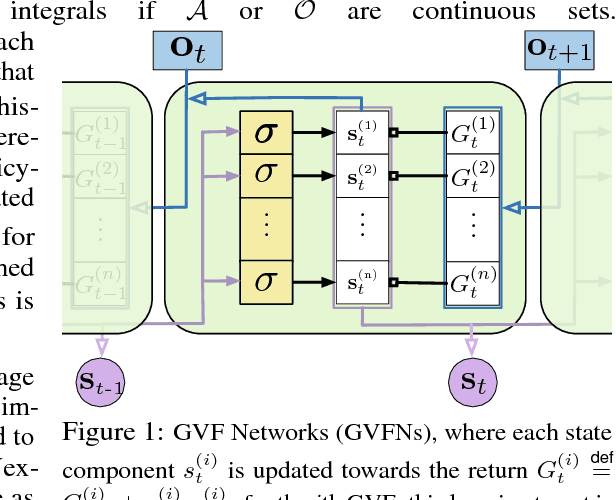
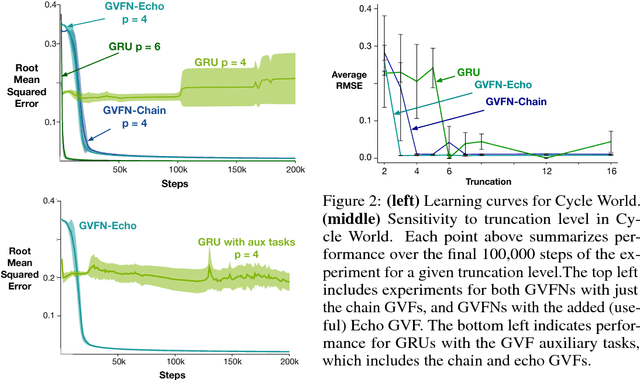
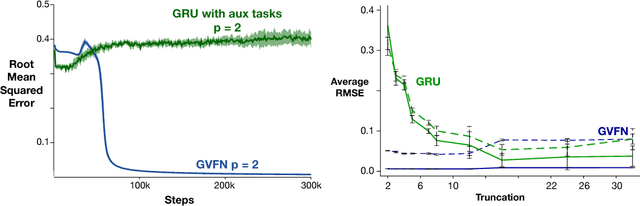
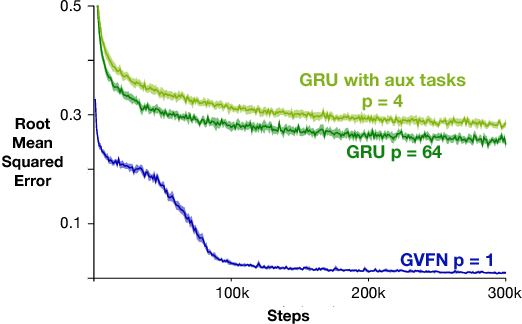
In this paper we show that restricting the representation-layer of a Recurrent Neural Network (RNN) improves accuracy and reduces the depth of recursive training procedures in partially observable domains. Artificial Neural Networks have been shown to learn useful state representations for high-dimensional visual and continuous control domains. If the the tasks at hand exhibits long depends back in time, these instantaneous feed-forward approaches are augmented with recurrent connections and trained with Back-prop Through Time (BPTT). This unrolled training can become computationally prohibitive if the dependency structure is long, and while recent work on LSTMs and GRUs has improved upon naive training strategies, there is still room for improvements in computational efficiency and parameter sensitivity. In this paper we explore a simple modification to the classic RNN structure: restricting the state to be comprised of multi-step General Value Function predictions. We formulate an architecture called General Value Function Networks (GVFNs), and corresponding objective that generalizes beyond previous approaches. We show that our GVFNs are significantly more robust to train, and facilitate accurate prediction with no gradients needed back-in-time in domains with substantial long-term dependences.