 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Value Function Networks
Paper and Code
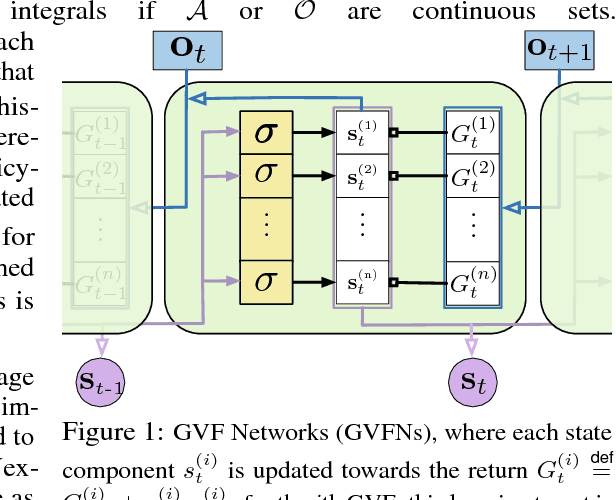
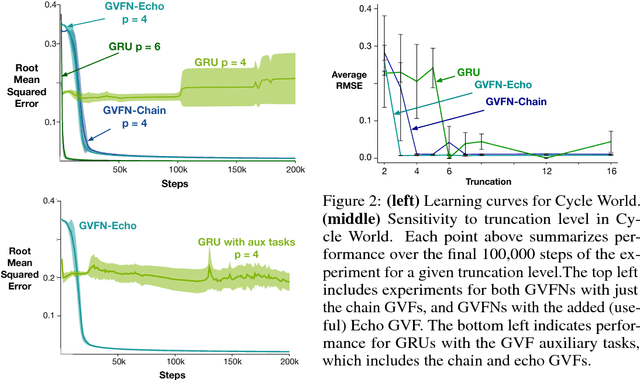
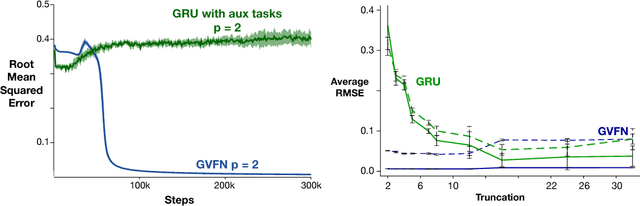
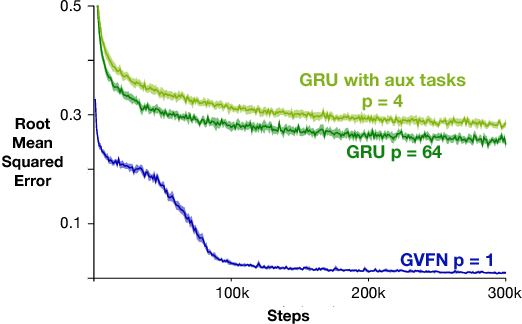
In this paper we show that restricting the representation-layer of a Recurrent Neural Network (RNN) improves accuracy and reduces the depth of recursive training procedures in partially observable domains. Artificial Neural Networks have been shown to learn useful state representations for high-dimensional visual and continuous control domains. If the the tasks at hand exhibits long depends back in time, these instantaneous feed-forward approaches are augmented with recurrent connections and trained with Back-prop Through Time (BPTT). This unrolled training can become computationally prohibitive if the dependency structure is long, and while recent work on LSTMs and GRUs has improved upon naive training strategies, there is still room for improvements in computational efficiency and parameter sensitivity. In this paper we explore a simple modification to the classic RNN structure: restricting the state to be comprised of multi-step General Value Function predictions. We formulate an architecture called General Value Function Networks (GVFNs), and corresponding objective that generalizes beyond previous approaches. We show that our GVFNs are significantly more robust to train, and facilitate accurate prediction with no gradients needed back-in-time in domains with substantial long-term dependences.