 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding trade-offs in classifier bias with quality-diversity optimization: an application to talent management
Nov 25, 2024
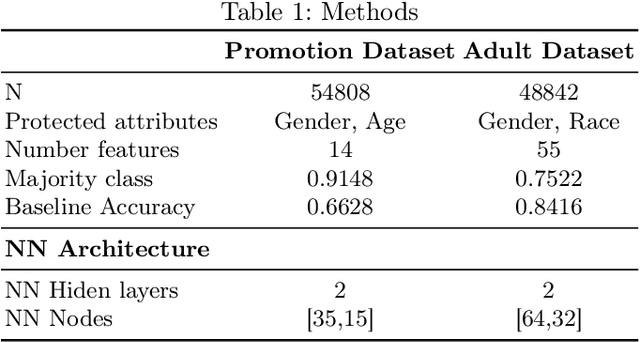


Fairness,the impartial treatment towards individuals or groups regardless of their inherent or acquired characteristics [20], is a critical challenge for the successful implementation of Artificial Intelligence (AI) in multiple fields like finances, human capital, and housing. A major struggle for the development of fair AI models lies in the bias implicit in the data available to train such models. Filtering or sampling the dataset before training can help ameliorate model bias but can also reduce model performance and the bias impact can be opaque. In this paper, we propose a method for visualizing the biases inherent in a dataset and understanding the potential trade-offs between fairness and accuracy. Our method builds on quality-diversity optimization, in particular Covariance Matrix Adaptation Multi-dimensional Archive of Phenotypic Elites (MAP-Elites). Our method provides a visual representation of bias in models, allows users to identify models within a minimal threshold of fairness, and determines the trade-off between fairness and accuracy.
External Stability Auditing to Test the Validity of Personality Prediction in AI Hiring
Jan 23, 2022
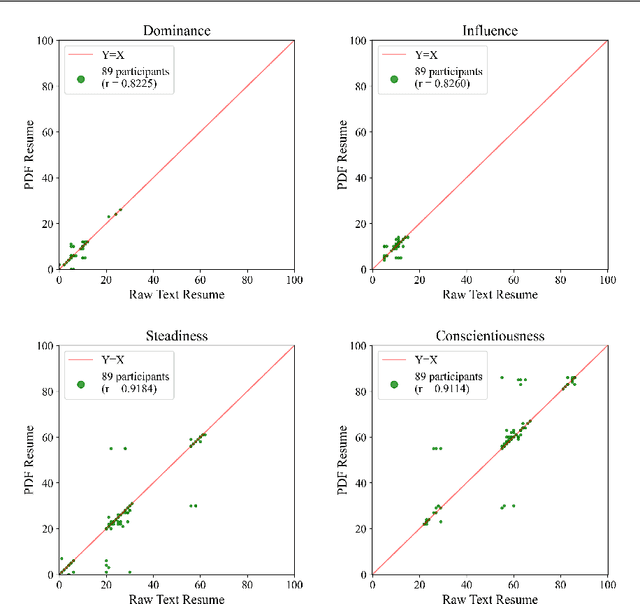
Automated hiring systems are among the fastest-developing of all high-stakes AI systems. Among these are algorithmic personality tests that use insights from psychometric testing, and promise to surface personality traits indicative of future success based on job seekers' resumes or social media profiles. We interrogate the validity of such systems using stability of the outputs they produce, noting that reliability is a necessary, but not a sufficient, condition for validity. Our approach is to (a) develop a methodology for an external audit of stability of predictions made by algorithmic personality tests, and (b) instantiate this methodology in an audit of two systems, Humantic AI and Crystal. Crucially, rather than challenging or affirming the assumptions made in psychometric testing -- that personality is a meaningful and measurable construct, and that personality traits are indicative of future success on the job -- we frame our methodology around testing the underlying assumptions made by the vendors of the algorithmic personality tests themselves. In our audit of Humantic AI and Crystal, we find that both systems show substantial instability with respect to key facets of measurement, and so cannot be considered valid testing instruments. For example, Crystal frequently computes different personality scores if the same resume is given in PDF vs. in raw text format, violating the assumption that the output of an algorithmic personality test is stable across job-irrelevant variations in the input. Among other notable findings is evidence of persistent -- and often incorrect -- data linkage by Humantic AI.