 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiGDA: Hierarchical Graph of Nodes to Learn Local-to-Global Topology for Semi-Supervised Domain Adaptation
Dec 16, 2024The enhanced representational power and broad applicability of deep learning models have attracted significant interest from the research community in recent years. However, these models often struggle to perform effectively under domain shift conditions, where the training data (the source domain) is related to but exhibits different distributions from the testing data (the target domain). To address this challenge, previous studies have attempted to reduce the domain gap between source and target data by incorporating a few labeled target samples during training - a technique known as semi-supervised domain adaptation (SSDA). While this strategy has demonstrated notable improvements in classification performance, the network architectures used in these approaches primarily focus on exploiting the features of individual images, leaving room for improvement in capturing rich representations. In this study, we introduce a Hierarchical Graph of Nodes designed to simultaneously present representations at both feature and category levels. At the feature level, we introduce a local graph to identify the most relevant patches within an image, facilitating adaptability to defined main object representations. At the category level, we employ a global graph to aggregate the features from samples within the same category, thereby enriching overall representations. Extensive experiments on widely used SSDA benchmark datasets, including Office-Home, DomainNet, and VisDA2017, demonstrate that both quantitative and qualitative results substantiate the effectiveness of HiGDA, establishing it as a new state-of-the-art method.
Learning CNN on ViT: A Hybrid Model to Explicitly Class-specific Boundaries for Domain Adaptation
Apr 02, 2024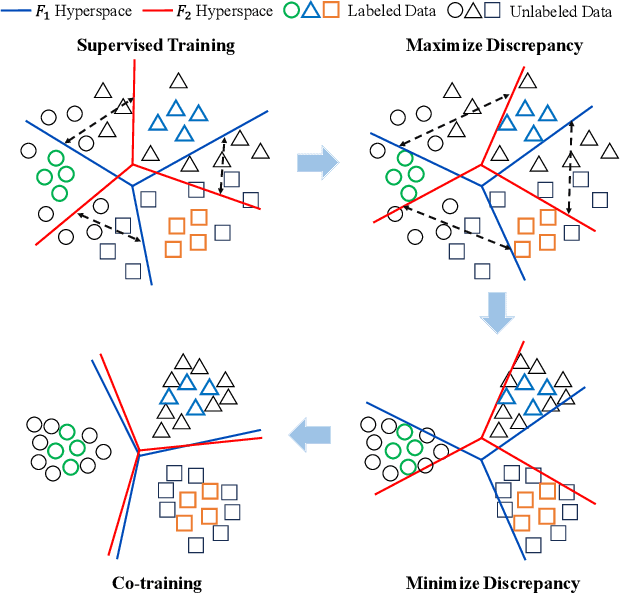
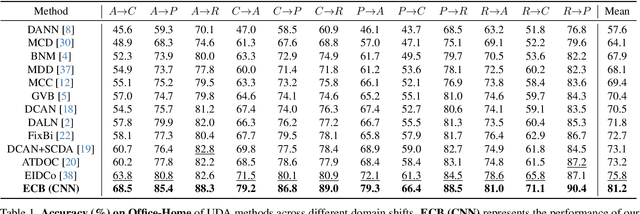
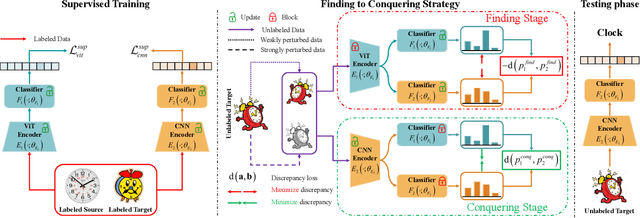
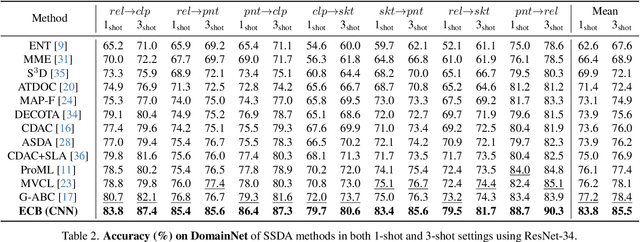
Most domain adaptation (DA) methods are based on either a convolutional neural networks (CNNs) or a vision transformers (ViTs). They align the distribution differences between domains as encoders without considering their unique characteristics. For instance, ViT excels in accuracy due to its superior ability to capture global representations, while CNN has an advantage in capturing local representations. This fact has led us to design a hybrid method to fully take advantage of both ViT and CNN, called Explicitly Class-specific Boundaries (ECB). ECB learns CNN on ViT to combine their distinct strengths. In particular, we leverage ViT's properties to explicitly find class-specific decision boundaries by maximizing the discrepancy between the outputs of the two classifiers to detect target samples far from the source support. In contrast, the CNN encoder clusters target features based on the previously defined class-specific boundaries by minimizing the discrepancy between the probabilities of the two classifiers. Finally, ViT and CNN mutually exchange knowledge to improve the quality of pseudo labels and reduce the knowledge discrepancies of these models. Compared to conventional DA methods, our ECB achieves superior performance, which verifies its effectiveness in this hybrid model. The project website can be found https://dotrannhattuong.github.io/ECB/website/.