 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-preserving feature selection: A survey and proposing a new set of protocols
Aug 17, 2020
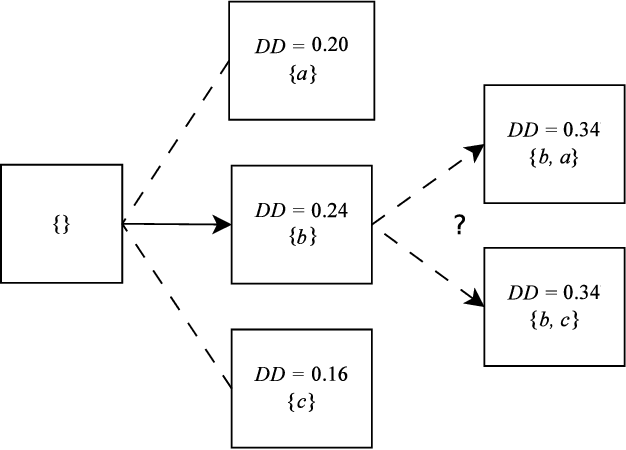
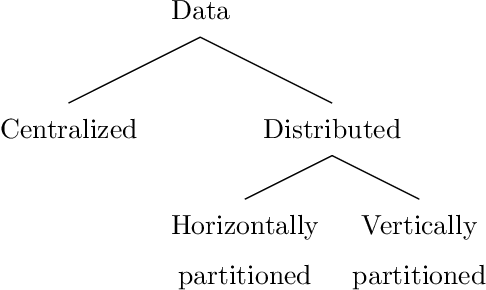
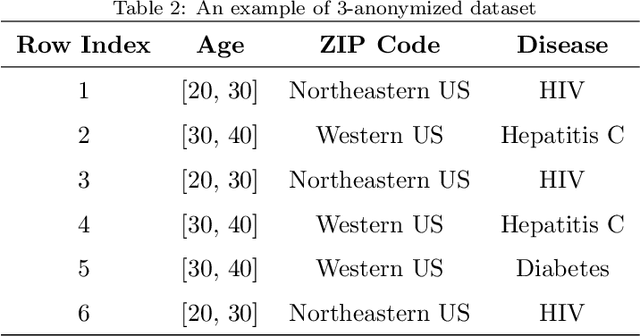
Feature selection is the process of sieving features, in which informative features are separated from the redundant and irrelevant ones. This process plays an important role in machine learning, data mining and bioinformatics. However, traditional feature selection methods are only capable of processing centralized datasets and are not able to satisfy today's distributed data processing needs. These needs require a new category of data processing algorithms called privacy-preserving feature selection, which protects users' data by not revealing any part of the data neither in the intermediate processing nor in the final results. This is vital for the datasets which contain individuals' data, such as medical datasets. Therefore, it is rational to either modify the existing algorithms or propose new ones to not only introduce the capability of being applied to distributed datasets, but also act responsibly in handling users' data by protecting their privacy. In this paper, we will review three privacy-preserving feature selection methods and provide suggestions to improve their performance when any gap is identified. We will also propose a privacy-preserving feature selection method based on the rough set feature selection. The proposed method is capable of processing both horizontally and vertically partitioned datasets in two- and multi-parties scenarios.
A Fuzzy-Rough based Binary Shuffled Frog Leaping Algorithm for Feature Selection
Jul 31, 2018

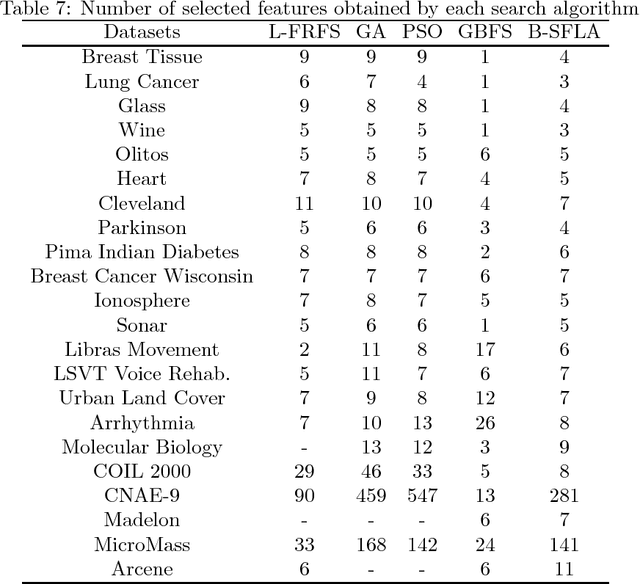

Feature selection and attribute reduction are crucial problems, and widely used techniques in the field of machine learning, data mining and pattern recognition to overcome the well-known phenomenon of the Curse of Dimensionality, by either selecting a subset of features or removing unrelated ones. This paper presents a new feature selection method that efficiently carries out attribute reduction, thereby selecting the most informative features of a dataset. It consists of two components: 1) a measure for feature subset evaluation, and 2) a search strategy. For the evaluation measure, we have employed the fuzzy-rough dependency degree (FRFDD) in the lower approximation-based fuzzy-rough feature selection (L-FRFS) due to its effectiveness in feature selection. As for the search strategy, a new version of a binary shuffled frog leaping algorithm is proposed (B-SFLA). The new feature selection method is obtained by hybridizing the B-SFLA with the FRDD. Non-parametric statistical tests are conducted to compare the proposed approach with several existing methods over twenty two datasets, including nine high dimensional and large ones, from the UCI repository. The experimental results demonstrate that the B-SFLA approach significantly outperforms other metaheuristic methods in terms of the number of selected features and the classification accuracy.