 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFarsInstruct: Empowering Large Language Models for Persian Instruction Understanding
Jul 15, 2024

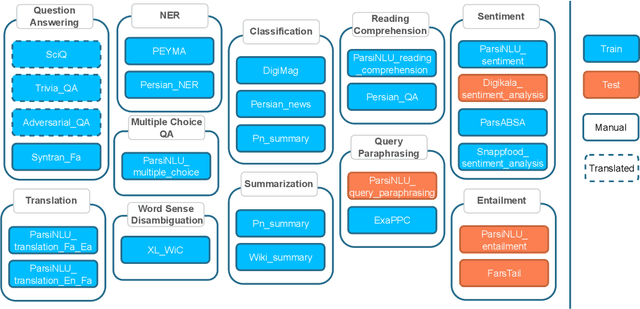

Instruction-tuned large language models, such as T0, have demonstrated remarkable capabilities in following instructions across various domains. However, their proficiency remains notably deficient in many low-resource languages. To address this challenge, we introduce FarsInstruct: a comprehensive instruction dataset designed to enhance the instruction-following ability of large language models specifically for the Persian language, a significant yet underrepresented language globally. FarsInstruct encompasses a wide range of task types and datasets, each containing a mix of straightforward to complex manual written instructions, as well as translations from Public Pool of Prompts, ensuring a rich linguistic and cultural representation. Furthermore, we introduce Co-CoLA, a framework designed to enhance the multi-task adaptability of LoRA-tuned models. Through extensive experimental analyses, our study showcases the effectiveness of FarsInstruct dataset coupled with training by Co-CoLA framework, in improving the performance of large language models within the Persian context. As of the current writing, FarsInstruct comprises more than 200 templates across 21 distinct datasets, and we intend to update it consistently, thus augmenting its applicability.
SELF-VS: Self-supervised Encoding Learning For Video Summarization
Mar 28, 2023Despite its wide range of applications, video summarization is still held back by the scarcity of extensive datasets, largely due to the labor-intensive and costly nature of frame-level annotations. As a result, existing video summarization methods are prone to overfitting. To mitigate this challenge, we propose a novel self-supervised video representation learning method using knowledge distillation to pre-train a transformer encoder. Our method matches its semantic video representation, which is constructed with respect to frame importance scores, to a representation derived from a CNN trained on video classification. Empirical evaluations on correlation-based metrics, such as Kendall's $\tau$ and Spearman's $\rho$ demonstrate the superiority of our approach compared to existing state-of-the-art methods in assigning relative scores to the input frames.