 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Learning of Compact Models via Task-Specific Meta Distillation
Oct 18, 2022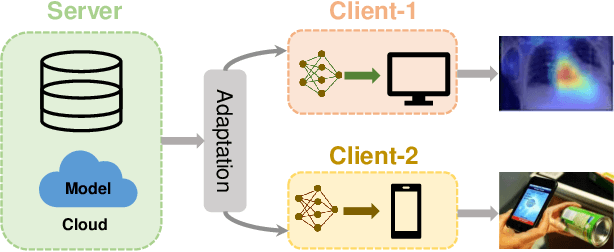
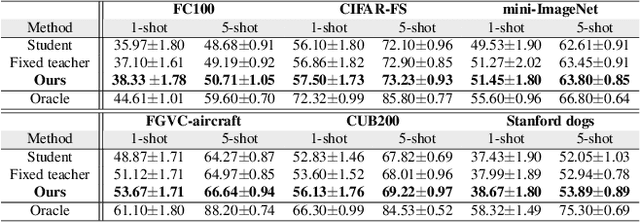
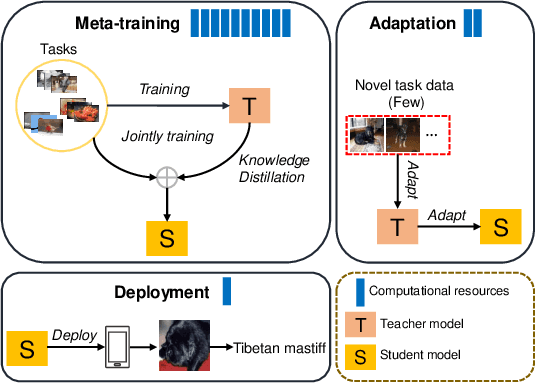
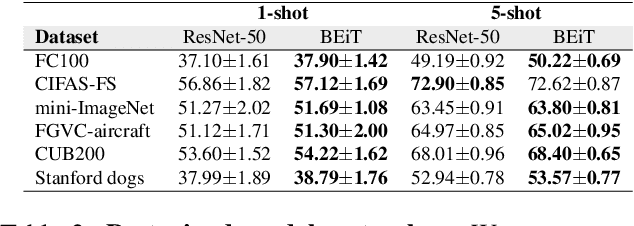
We consider a new problem of few-shot learning of compact models. Meta-learning is a popular approach for few-shot learning. Previous work in meta-learning typically assumes that the model architecture during meta-training is the same as the model architecture used for final deployment. In this paper, we challenge this basic assumption. For final deployment, we often need the model to be small. But small models usually do not have enough capacity to effectively adapt to new tasks. In the mean time, we often have access to the large dataset and extensive computing power during meta-training since meta-training is typically performed on a server. In this paper, we propose task-specific meta distillation that simultaneously learns two models in meta-learning: a large teacher model and a small student model. These two models are jointly learned during meta-training. Given a new task during meta-testing, the teacher model is first adapted to this task, then the adapted teacher model is used to guide the adaptation of the student model. The adapted student model is used for final deployment. We demonstrate the effectiveness of our approach in few-shot image classification using model-agnostic meta-learning (MAML). Our proposed method outperforms other alternatives on several benchmark datasets.
Unsupervised Learning of Camera Pose with Compositional Re-estimation
Jan 17, 2020
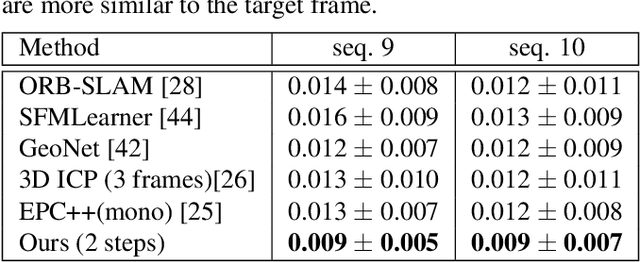
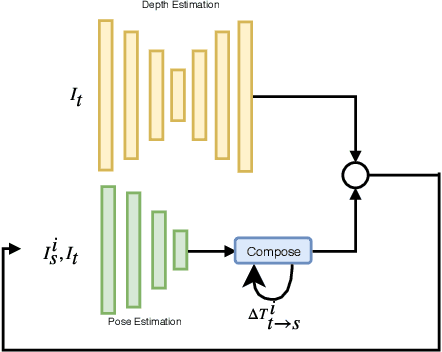
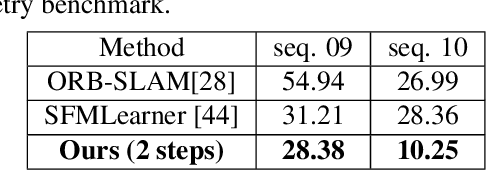
We consider the problem of unsupervised camera pose estimation. Given an input video sequence, our goal is to estimate the camera pose (i.e. the camera motion) between consecutive frames. Traditionally, this problem is tackled by placing strict constraints on the transformation vector or by incorporating optical flow through a complex pipeline. We propose an alternative approach that utilizes a compositional re-estimation process for camera pose estimation. Given an input, we first estimate a depth map. Our method then iteratively estimates the camera motion based on the estimated depth map. Our approach significantly improves the predicted camera motion both quantitatively and visually. Furthermore, the re-estimation resolves the problem of out-of-boundaries pixels in a novel and simple way. Another advantage of our approach is that it is adaptable to other camera pose estimation approaches. Experimental analysis on KITTI benchmark dataset demonstrates that our method outperforms existing state-of-the-art approaches in unsupervised camera ego-motion estimation.
Towards Shape Biased Unsupervised Representation Learning for Domain Generalization
Sep 18, 2019
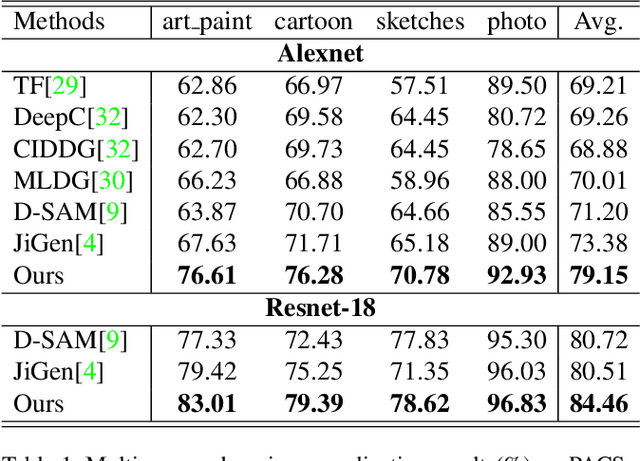
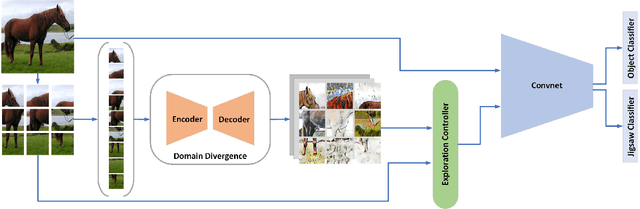
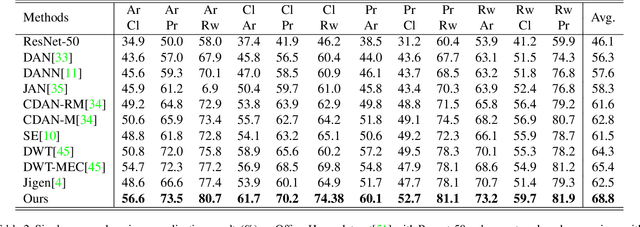
It is known that, without awareness of the process, our brain appears to focus on the general shape of objects rather than superficial statistics of context. On the other hand, learning autonomously allows discovering invariant regularities which help generalization. In this work, we propose a learning framework to improve the shape bias property of self-supervised methods. Our method learns semantic and shape biased representations by integrating domain diversification and jigsaw puzzles. The first module enables the model to create a dynamic environment across arbitrary domains and provides a domain exploration vs. exploitation trade-off, while the second module allows the model to explore this environment autonomously. This universal framework does not require prior knowledge of the domain of interest. Extensive experiments are conducted on several domain generalization datasets, namely, PACS, Office-Home, VLCS, and Digits. We show that our framework outperforms state-of-the-art domain generalization methods by a large margin.
Crowd Counting Using Scale-Aware Attention Networks
Mar 05, 2019

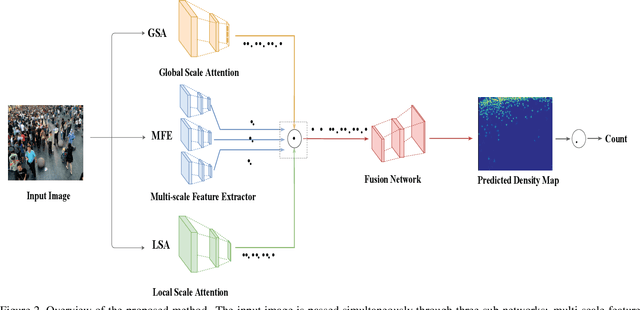
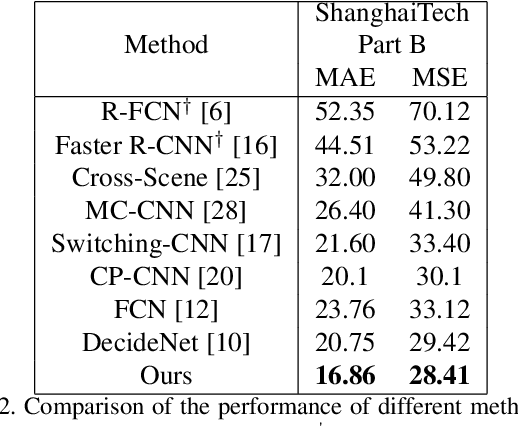
In this paper, we consider the problem of crowd counting in images. Given an image of a crowded scene, our goal is to estimate the density map of this image, where each pixel value in the density map corresponds to the crowd density at the corresponding location in the image. Given the estimated density map, the final crowd count can be obtained by summing over all values in the density map. One challenge of crowd counting is the scale variation in images. In this work, we propose a novel scale-aware attention network to address this challenge. Using the attention mechanism popular in recent deep learning architectures, our model can automatically focus on certain global and local scales appropriate for the image. By combining these global and local scale attention, our model outperforms other state-of-the-art methods for crowd counting on several benchmark datasets.