 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiminishing the Effect of Adversarial Perturbations via Refining Feature Representation
Paper and Code
Jul 01, 2019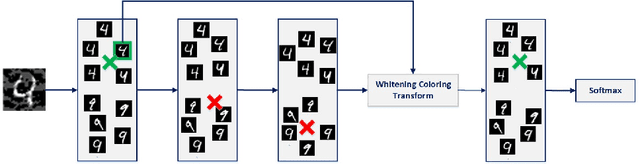

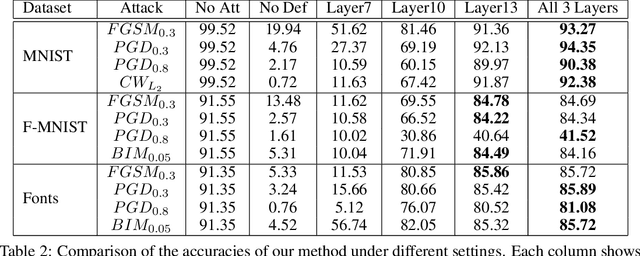

Deep neural networks are highly vulnerable to adversarial examples, which imposes severe security issues for these state-of-the-art models. Many defense methods have been proposed to mitigate this problem. However, a lot of them depend on modification or additional training of the target model. In this work, we analytically investigate each layer representation of non-perturbed and perturbed images and show the effect of perturbations on each of these representations. Accordingly, a method based on whitening coloring transform is proposed in order to diminish the misrepresentation of any desirable layer caused by adversaries. Our method can be applied to any layer of any arbitrary model without the need of any modification or additional training. Due to the fact that full whitening of the layer representation is not easily differentiable, our proposed method is superbly robust against white-box attacks. Furthermore, we demonstrate the strength of our method against some state-of-the-art black-box attacks such as Carlini-Wagner L2 attack and we show that our method is able to defend against some non-constrained attacks.