 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReturn Augmented Decision Transformer for Off-Dynamics Reinforcement Learning
Paper and Code
Oct 30, 2024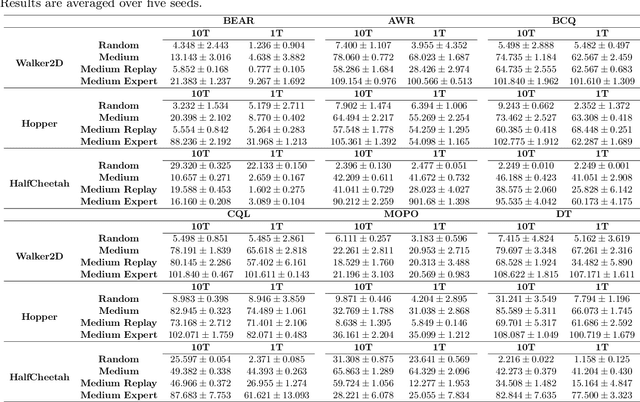
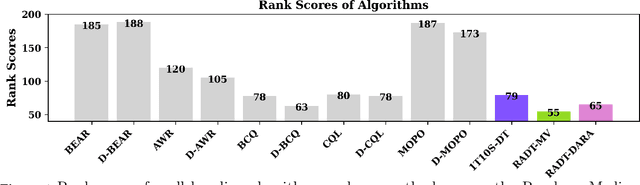


We study offline off-dynamics reinforcement learning (RL) to utilize data from an easily accessible source domain to enhance policy learning in a target domain with limited data. Our approach centers on return-conditioned supervised learning (RCSL), particularly focusing on the decision transformer (DT), which can predict actions conditioned on desired return guidance and complete trajectory history. Previous works tackle the dynamics shift problem by augmenting the reward in the trajectory from the source domain to match the optimal trajectory in the target domain. However, this strategy can not be directly applicable in RCSL owing to (1) the unique form of the RCSL policy class, which explicitly depends on the return, and (2) the absence of a straightforward representation of the optimal trajectory distribution. We propose the Return Augmented Decision Transformer (RADT) method, where we augment the return in the source domain by aligning its distribution with that in the target domain. We provide the theoretical analysis demonstrating that the RCSL policy learned from RADT achieves the same level of suboptimality as would be obtained without a dynamics shift. We introduce two practical implementations RADT-DARA and RADT-MV respectively. Extensive experiments conducted on D4RL datasets reveal that our methods generally outperform dynamic programming based methods in off-dynamics RL scenarios.