 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterNet: Unsupervised Cross-modal Homography Estimation Based on Interleaved Modality Transfer and Self-supervised Homography Prediction
Sep 26, 2024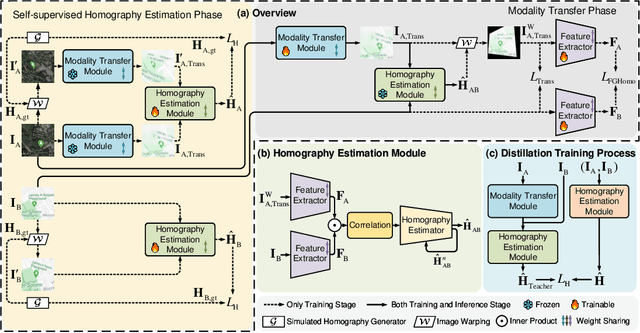
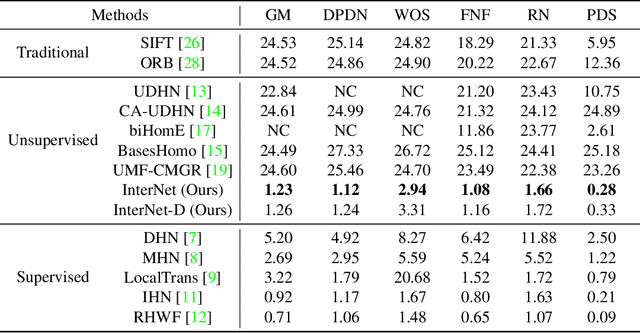


We propose a novel unsupervised cross-modal homography estimation framework, based on interleaved modality transfer and self-supervised homography prediction, named InterNet. InterNet integrates modality transfer and self-supervised homography estimation, introducing an innovative interleaved optimization framework to alternately promote both components. The modality transfer gradually narrows the modality gaps, facilitating the self-supervised homography estimation to fully leverage the synthetic intra-modal data. The self-supervised homography estimation progressively achieves reliable predictions, thereby providing robust cross-modal supervision for the modality transfer. To further boost the estimation accuracy, we also formulate a fine-grained homography feature loss to improve the connection between two components. Furthermore, we employ a simple yet effective distillation training technique to reduce model parameters and improve cross-domain generalization ability while maintaining comparable performance. Experiments reveal that InterNet achieves the state-of-the-art (SOTA) performance among unsupervised methods, and even outperforms many supervised methods such as MHN and LocalTrans.
Context and Geometry Aware Voxel Transformer for Semantic Scene Completion
May 22, 2024



Vision-based Semantic Scene Completion (SSC) has gained much attention due to its widespread applications in various 3D perception tasks. Existing sparse-to-dense approaches typically employ shared context-independent queries across various input images, which fails to capture distinctions among them as the focal regions of different inputs vary and may result in undirected feature aggregation of cross-attention. Additionally, the absence of depth information may lead to points projected onto the image plane sharing the same 2D position or similar sampling points in the feature map, resulting in depth ambiguity. In this paper, we present a novel context and geometry aware voxel transformer. It utilizes a context aware query generator to initialize context-dependent queries tailored to individual input images, effectively capturing their unique characteristics and aggregating information within the region of interest. Furthermore, it extend deformable cross-attention from 2D to 3D pixel space, enabling the differentiation of points with similar image coordinates based on their depth coordinates. Building upon this module, we introduce a neural network named CGFormer to achieve semantic scene completion. Simultaneously, CGFormer leverages multiple 3D representations (i.e., voxel and TPV) to boost the semantic and geometric representation abilities of the transformed 3D volume from both local and global perspectives. Experimental results demonstrate that CGFormer achieves state-of-the-art performance on the SemanticKITTI and SSCBench-KITTI-360 benchmarks, attaining a mIoU of 16.87 and 20.05, as well as an IoU of 45.99 and 48.07, respectively. Remarkably, CGFormer even outperforms approaches employing temporal images as inputs or much larger image backbone networks. Code for the proposed method is available at https://github.com/pkqbajng/CGFormer.