 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEVPlace++: Fast, Robust, and Lightweight LiDAR Global Localization for Unmanned Ground Vehicles
Aug 03, 2024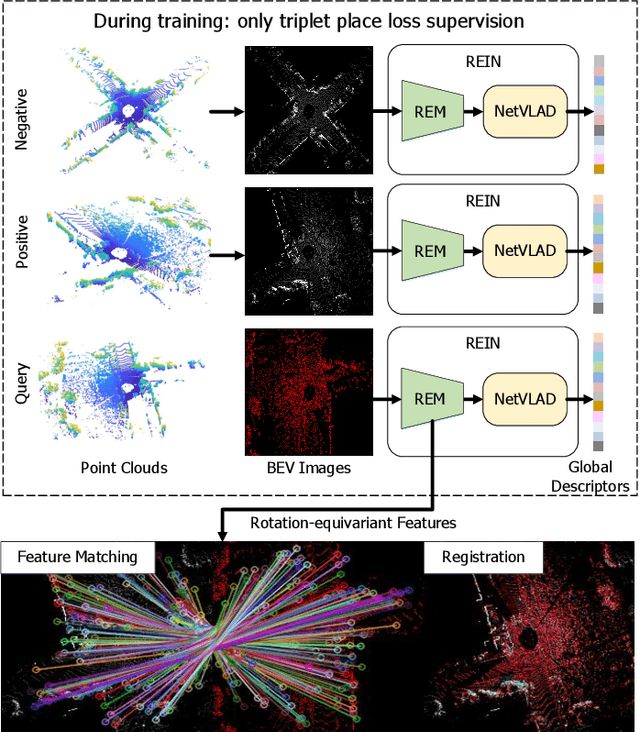
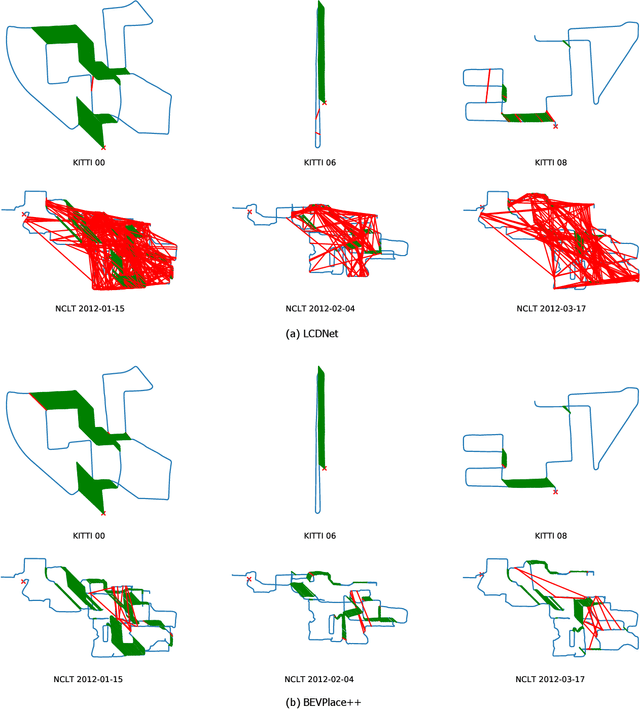
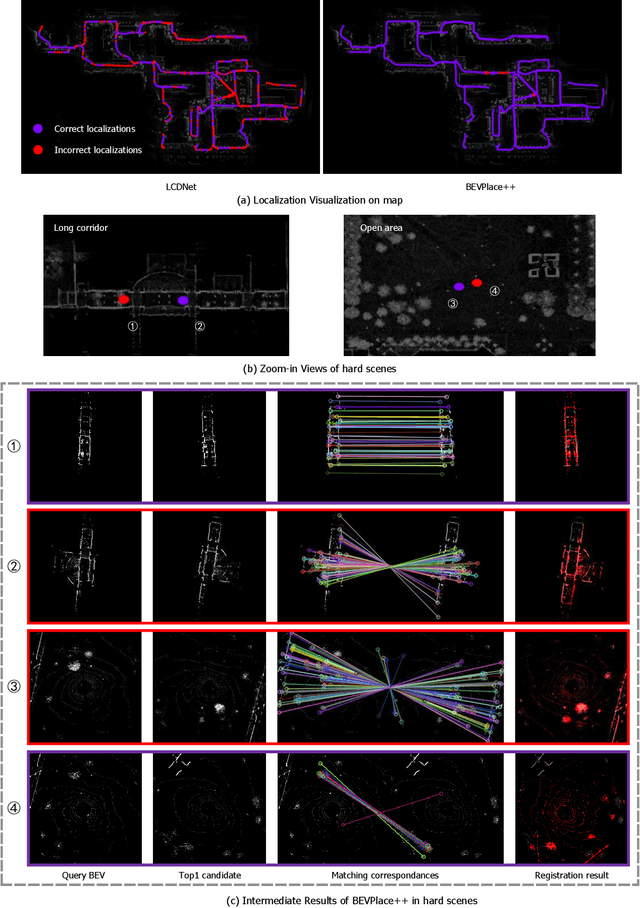
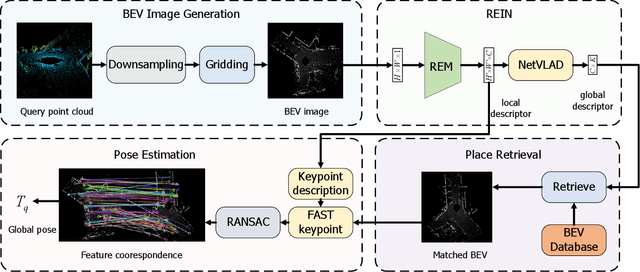
This article introduces BEVPlace++, a novel, fast, and robust LiDAR global localization method for unmanned ground vehicles. It uses lightweight convolutional neural networks (CNNs) on Bird's Eye View (BEV) image-like representations of LiDAR data to achieve accurate global localization through place recognition followed by 3-DoF pose estimation. Our detailed analyses reveal an interesting fact that CNNs are inherently effective at extracting distinctive features from LiDAR BEV images. Remarkably, keypoints of two BEV images with large translations can be effectively matched using CNN-extracted features. Building on this insight, we design a rotation equivariant module (REM) to obtain distinctive features while enhancing robustness to rotational changes. A Rotation Equivariant and Invariant Network (REIN) is then developed by cascading REM and a descriptor generator, NetVLAD, to sequentially generate rotation equivariant local features and rotation invariant global descriptors. The global descriptors are used first to achieve robust place recognition, and the local features are used for accurate pose estimation. Experimental results on multiple public datasets demonstrate that BEVPlace++, even when trained on a small dataset (3000 frames of KITTI) only with place labels, generalizes well to unseen environments, performs consistently across different days and years, and adapts to various types of LiDAR scanners. BEVPlace++ achieves state-of-the-art performance in subtasks of global localization including place recognition, loop closure detection, and global localization. Additionally, BEVPlace++ is lightweight, runs in real-time, and does not require accurate pose supervision, making it highly convenient for deployment. The source codes are publicly available at \href{https://github.com/zjuluolun/BEVPlace}{https://github.com/zjuluolun/BEVPlace}.
Context and Geometry Aware Voxel Transformer for Semantic Scene Completion
May 22, 2024



Vision-based Semantic Scene Completion (SSC) has gained much attention due to its widespread applications in various 3D perception tasks. Existing sparse-to-dense approaches typically employ shared context-independent queries across various input images, which fails to capture distinctions among them as the focal regions of different inputs vary and may result in undirected feature aggregation of cross-attention. Additionally, the absence of depth information may lead to points projected onto the image plane sharing the same 2D position or similar sampling points in the feature map, resulting in depth ambiguity. In this paper, we present a novel context and geometry aware voxel transformer. It utilizes a context aware query generator to initialize context-dependent queries tailored to individual input images, effectively capturing their unique characteristics and aggregating information within the region of interest. Furthermore, it extend deformable cross-attention from 2D to 3D pixel space, enabling the differentiation of points with similar image coordinates based on their depth coordinates. Building upon this module, we introduce a neural network named CGFormer to achieve semantic scene completion. Simultaneously, CGFormer leverages multiple 3D representations (i.e., voxel and TPV) to boost the semantic and geometric representation abilities of the transformed 3D volume from both local and global perspectives. Experimental results demonstrate that CGFormer achieves state-of-the-art performance on the SemanticKITTI and SSCBench-KITTI-360 benchmarks, attaining a mIoU of 16.87 and 20.05, as well as an IoU of 45.99 and 48.07, respectively. Remarkably, CGFormer even outperforms approaches employing temporal images as inputs or much larger image backbone networks. Code for the proposed method is available at https://github.com/pkqbajng/CGFormer.
BEVPlace: Learning LiDAR-based Place Recognition using Bird's Eye View Images
Mar 15, 2023



Place recognition is a key module for long-term SLAM systems. Current LiDAR-based place recognition methods are usually based on representations of point clouds such as unordered points or range images. These methods achieve high recall rates of retrieval, but their performance may degrade in the case of view variation or scene changes. In this work, we explore the potential of a different representation in place recognition, i.e. bird's eye view (BEV) images. We observe that the structural contents of BEV images are less influenced by rotations and translations of point clouds. We validate that, without any delicate design, a simple VGGNet trained on BEV images achieves comparable performance with the state-of-the-art place recognition methods in scenes of slight viewpoint changes. For more robust place recognition, we design a rotation-invariant network called BEVPlace. We use group convolution to extract rotation-equivariant local features from the images and NetVLAD for global feature aggregation. In addition, we observe that the distance between BEV features is correlated with the geometry distance of point clouds. Based on the observation, we develop a method to estimate the position of the query cloud, extending the usage of place recognition. The experiments conducted on large-scale public datasets show that our method 1) achieves state-of-the-art performance in terms of recall rates, 2) is robust to view changes, 3) shows strong generalization ability, and 4) can estimate the positions of query point clouds. Source code will be made publicly available at https://github.com/zjuluolun/BEVPlace.